常见的无损压缩算法
无损压缩算法
LZ77 算法
LZ77 算法的关键是搜索,即在已经处理过的符号序列(数据流)中,寻找与待编码符号序列相同的模式,如果找到匹配的模式,就设法对这个模式进行索引,也就是生成一个指针,然后输出该索引即可。LZ77 算法巧妙地实现了这个处理。为了帮助读者理解算法原理,我们用图 5-8 描述 LZ77 算法的操作过程,其中涉及到算法用到的几个关键概念。
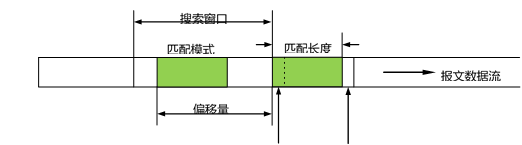
当前编码位置,即匹配模式的首字符 下一个字符
5-8 描述 LZ77 算法的操作过程
压缩处理是从整个报文的第一个字符开始的。但是,为了使描述不失一般性,我们假设压缩过程已经推进到了当前编码位置。图 5-8 中,深色(绿色)部分代表搜索到的一个匹配模式。当然,搜索过程本身还包含一些具体技术,实际上也是算法的难点。通过搜索,还得到了匹配模式的长度(length),以及偏移量(off)。从图 5-8 可以看出,当前编码位置是指正在处理的匹配模式的第一个字符,而偏移量是指搜索到的匹配模式的第一个字符到当前编码位置的距离,即从匹配模式的首字符开始算起,到当前编码位置之前的字符数。可以想见,在当前编码位置确定的条件下,off 和 length 就可以作为匹配模式的索引(即指针)。因为在解码的时候,解码程序很容易通过 off 和 length 找到需要还原的模式。所以,总体上 LZ77 算法就是一个搜索匹配模式、输出匹配长度和偏移量的循环过程。这个整体概念有助于理解算法的基本原理。有了整体框架,我们还要考虑一些细节问题。
第一个问题,图 5-8 中的"下一个字符"(next_char)有什么用?下一个字符是紧跟在从
当前编码位置开始的匹配模式的后面的一个字符。实际上,在搜索不到匹配模式的情况下,我们还是需要将压缩过程往前推进,如果直接输出 next char,就可以往前推进一个字符。否则的话,算法就会原地踏步。由此可见,next_char 的设计起到了一个保证压缩进程不会中途停止的作用。
第二问题是,随着压缩过程往前推进,已经处理过的数据会越来越长,这显然会使后续的搜索时间增加。不难想见,如果能够限制搜索范围,自然可以避免这种增加。这就是图 5-8 中搜索窗口的由来。从数据结构的角度看,搜索窗口就是从当前编码位置开始往回统计的字符个数(max_window_size)。当然,限制搜索范围,也会降低搜索到最大匹配长度的概率,而匹配长度关系到压缩效率。因此,这里实际上需要在压缩效率与计算时间之间寻找一个平衡点。实际应用中,max_window_size 可以作为一个参数交由用户设置。
代码 5-1 给出了 LZ77 算法的伪码描述,其中的变量名称采用了上面论述中类似的命名方法,如 off 表示偏移量,length 表示匹配长度,等等。
代码 5-1 描述 LZ77 算法的伪码
______________________________________________________________________________ Algorithm_LZ77( input:message output: compressed_message)
{ set current coding position pointer to the start of message; while ( TRUE) { search the max matched string in the slide window;
get the off and the length; if ( length ≠ 0){ add (off, length, next_char) to the end of compressed_message; move the current coding position pointer ahead length+1;
} else{ add (0, 0, next_char) to the end of compressed_message; move the current coding position pointer ahead 1;
}
If ( the current coding position pointer is the end of message) return ;
}
}
_______________________________________________________________________________
下面来看一个例子。设输入报文是(AABCBBABCAABCE),搜索窗口长度为 10。第一轮循环结束时的状态如图 5-9 所示。
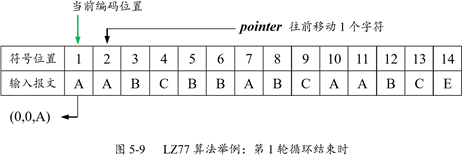
最初,当前编码位置为 1,搜索窗口为空。然后开始搜索,即在搜索窗口中查找与 A 相同的字符,显然找不到,因为窗口为空,故 off 和 length 均等于 0,按照算法要求,输出编码为(0,0,A),指针 pointer 往前移动 1 个字符,指向位置 2,也就是下一轮循环的当前编码位置。
第二轮循环的当前编码位置是 2,且窗口含有字符 A。开始搜索,能够为 2 号位置的 A 找到匹配模式 A,且 off 等于 1,length 也等于 1,因此,输出(1,1,B),并将 pointer 往前移动 2 个字符。第二轮循环结束时的状态如图 5-10 所示。

第三轮循环的结果如图 5-11 所示。尽管第三轮循环开始的时候,搜索窗口中已经包含了 AAB 三个字符,但仍不能为当前的 C 找到匹配模式,因此输出(0,0,C)。

第四轮循环的时候,我们满意地看到,窗口中包含的 AABC 正好与当前编码位置开始的模式 AABC 匹配,所以,off 等于 4,length 也等于 4(这是巧合),因此输出为(4,4,C)。注意,这个输出的三元组中的 C 是位置 9 上的字符 C。循环结束时,pointer 往前移动 5 个字符,即指向第 10 个字符位置。第四轮循环结束时的状态如图 5-12 所示。

第五轮循环开始的时候,窗口中包含的字符达到了 9 个,即 AABCAABCC,它们均属于搜索窗口。当前编码位置是上轮循环结束时 pointer 指向的位置 10。开始搜索,我们再次看到 AABC 这个匹配模式,而且在窗口中存在两个匹配的模式,左边那个的 off 等于 9,右边那个匹配模式的 off 为 5,length 为 4,因此,输出结果是(5,4,E)或(9,4,E)。第五轮循环结束时的状态如图 5-13 所示。
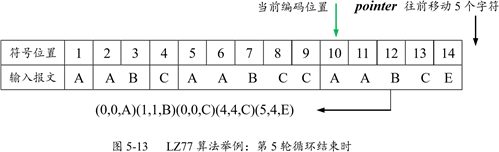
第五轮循环结束时,整个压缩处理即告结束。
在第五轮循环中,我们看到搜索过程并非一个简单的顺序查找,实际上是一个从多个匹配逐步演变为最佳匹配的过程。因此,如果要真正实现 LZ77 算法,在搜索过程中,还需要精心设计有效的数据结构。
作为最早提出来的词典编码算法,LZ77 的开创性贡献自不待言,但也存在一些需要改进的地方。首先,输出数据的格式可以简化,例如,在没有找到匹配模式的时候,只要输出下一个字符(next_char)即可,不需要采用(0,0,next_char)这种格式,这样可以消除不少冗余。第二,匹配模式的最小长度需要往上提高,因为匹配长度越短,意味着压缩效率越低,但输出数据消耗的存储空间不会减少。第三,在可以找到匹配模式的情况下,输出数据中不需要捎带 next_char,因为这时 next_char 是直接复制到输出数据中去了,实际上没有参与压缩,如果将它留下来参与后续的压缩,可以提高整个压缩过程的有效性。
LZSS 算法
LZSS 算法正是在 LZ77 算法基础上改进而来的,它的总体框架与 LZ77 算法一样,主要区别在于它设置了一个最小匹配长度,并改进了输出数据格式。如果匹配模式的长度大于最小匹配长度,就输出(off,length),否则就直接输出原字符序列(其长度取决于最小匹配长度,例如,如果最小匹配长度为 2,那么直接输出的原字符长度等于 1)。
代码 5-2 给出了 LZSS 算法的伪码描述。
代码 5-2 描述 LZSS 算法的伪码
______________________________________________________________________________ Algorithm_LZSS( input:message output: compressed_message)
{ set current coding position pointer to the start of message;
set MINIMUM_MATCHED_LENGTH;
while ( TRUE) { search the max matched string in the slide window;
get the off and the length;
if ( length ≥ MINIMUM_MATCHED_LENGTH ){
add (off, length) to the end of compressed_message; move the current coding position pointer ahead length;
} else{ add original_char_string to the end of compressed_message; move the current coding position pointer ahead length of original_char _string;
}
If ( the current coding position pointer is the end of message) return ; }
}
_______________________________________________________________________________
我们还是来看一个示例。设输入报文是(AABBCBBAABC),搜索窗口长度为 10,最小匹配长度 MINIMUM_MATCHED_LENGTH=2。
从第一轮循环开始,直到编码位置移动到 5 为止,由于搜索不到等于或大于 2 的匹配模式,因此得到的输出编码是原字符序列 AABBC 的拷贝。这之后,当前编码位置移到了第 6 个字符 B,算法接着在窗口中搜索,结果找到 BB 这一匹配模式,偏移量等于 3,长度为 2,所以算法将编码(3,2)添加到压缩报文尾部,得到 AABBC(3,2)。接着将当前编码位置移到第 8 个字符,开始新一轮搜索,结果找到 AAB 这个匹配模式,偏移量为 7,匹配长度等于 3,
因此将编码(7,3)添加到输出数据尾部,得到 AABBC(3,2)(7,3)。最后输出为拷贝的字符 C,从而得到最终压缩结果 AABBC(3,2)(7,3)C。
在相同的计算环境下,LZSS 算法的压缩效率比 LZ77 算法高,而译码同样简单。这也就是为什么这种算法成为开发新算法的基础,许多后来开发的文档压缩程序都使用了 LZSS 算法。例如,PKZip、ARJ、LHArc 和 ZOO 等等,其差别仅仅是指针的长短和窗口的大小等有所不同。此外,LZSS 算法常常与熵编码联合使用,例如 ARJ 就与霍夫曼编码联用,而 PKZip 则与香农-范诺算法联用,它的后续版本也集成了霍夫曼编码技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号