kafka副本数不足导致leader选举失败原因解析
我们聚焦在Kafka集群中"副本不足导致Leader选举失败"的具体逻辑和原因。当Broker节点宕机后,分区(Partition)的Leader选举是维持服务可用的关键,但若副本不足,选举将失败。
核心概念回顾
-
分区(Partition)与副本(Replica)
- 每个分区有多个副本(由
replication.factor配置,假设为3)。 - Leader副本:负责读写请求的唯一副本。
- Follower副本:从Leader异步拉取数据,作为备份。
- 每个分区有多个副本(由
-
ISR(In-Sync Replicas)
- Kafka维护的已与Leader同步的副本集合。
- Follower是否在ISR中取决于:
- 副本当前与Leader的消息差距(通过
replica.lag.time.max.ms判断,默认30秒)。 - 副本进程存活并与Leader保持心跳。
- 副本当前与Leader的消息差距(通过
副本不足导致Leader选举失败的逻辑流程
场景模拟
- 集群状态:
- Topic
T的分区P0,配置replication.factor=3,存储于Broker [1,2,3]。 - Leader为Broker1,ISR为[1,2,3]。
- Topic
- 故障发生:
Broker1宕机(原Leader),此时分区P0的状态变为:- 存活副本:Broker2和Broker3(均为Follower)。
- ISR:此时Kafka Controller会检测到Broker1离线,将其从ISR移除,更新ISR为[2,3]。
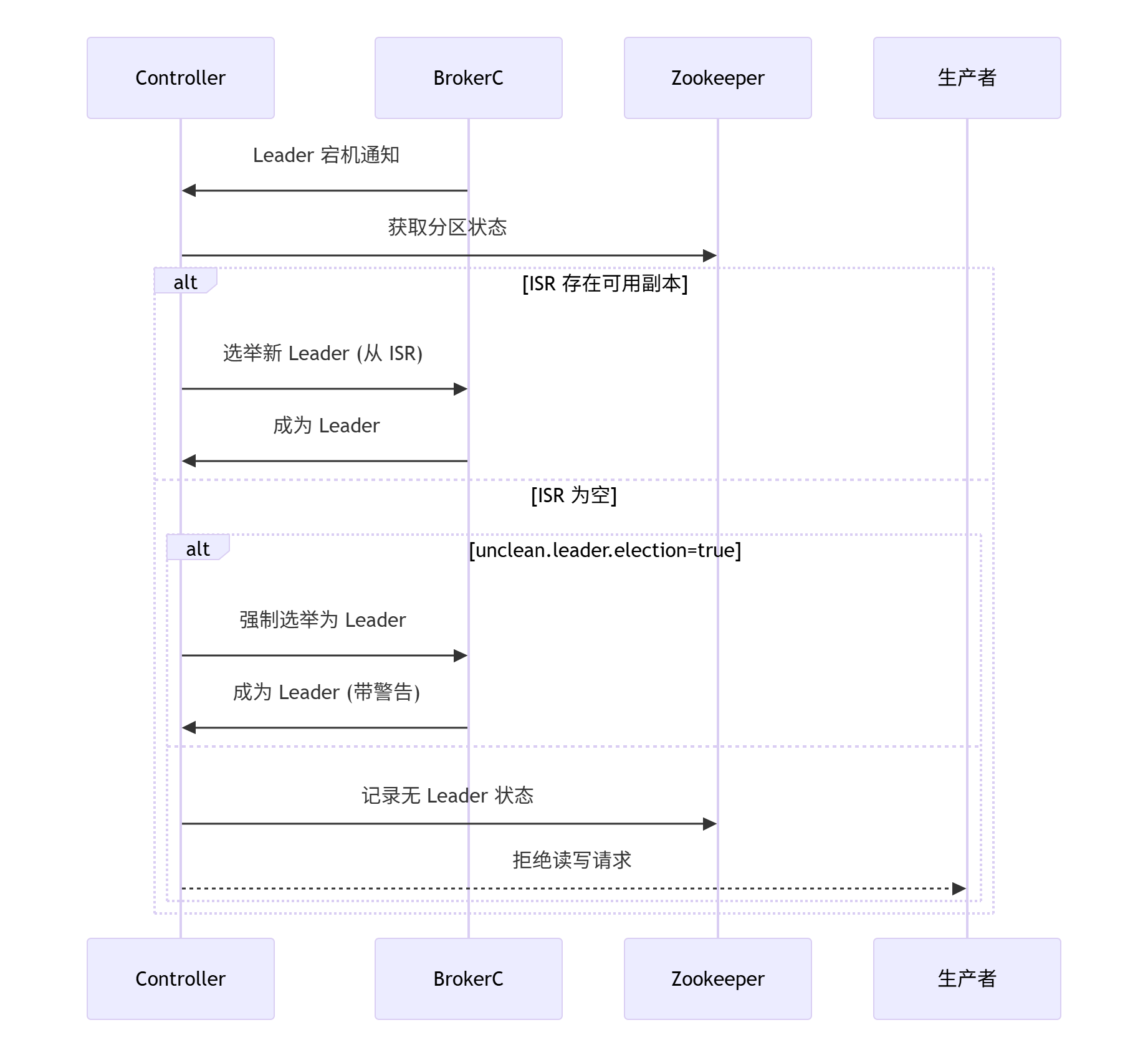
Leader选举触发条件
-
Controller检测Leader失效
Kafka Controller(集群协调节点)监控到Broker1离线,触发P0的Leader选举。 -
选举规则
Controller会从 当前ISR([2,3])中选新Leader。假设选Broker2为新Leader。
副本不足如何导致选举失败?
失败发生在以下两种关键情况:
情况1:ISR列表为空
- 原因:
- 如果Broker1宕机前,Follower全部滞后超过阈值(例如Broker2、3因网络延迟或高负载被移出ISR),则ISR=[1](仅Leader自身)。
- Broker1宕机后,ISR变为空[]。
- 选举规则:
根据配置unclean.leader.election.enable决定行为:- 若
=false(推荐生产环境):禁止从ISR外选举,选举失败,分区进入 不可用状态(Leader=-1)。 - 若
=true:允许从存活但不同步的副本(如Broker2)中选Leader,但可能丢失数据(因Broker2的数据落后于原Leader)。
- 若
情况2:ISR副本数不足最小要求
- 前置配置:
min.insync.replicas=2(生产者要求的最小ISR副本数,用于保证持久性)。 - 故障过程:
- Broker1(Leader)宕机 → ISR降为[2,3](假设之前完全同步)。
- 紧接着Broker2宕机 → ISR降为[3]。
- 选举结果:
- ISR中只有Broker3,Controller成功选Broker3为Leader。
- 但分区仍不可用?
- 生产者视角:当生产者要求
acks=all时,需要等待至少min.insync.replicas=2个副本写入成功。此时只有一个副本(Broker3),生产者写入会被阻塞(无限重试或超时报错)! - 消费者视角:虽能继续读(Broker3成Leader),但无法写入新数据(生产者阻塞),表现为 消息停滞。
- 生产者视角:当生产者要求
关键参数对选举的影响
| 参数 | 默认值 | 对选举的影响 | 生产建议 |
|---|---|---|---|
min.insync.replicas |
1 | 控制写入最小同步副本数。 ISR低于此值时,Leader虽在位但生产者阻塞 |
≥2(且小于 replication.factor) |
unclean.leader.election.enable |
false | ISR为空时,是否允许从非同步副本选举? false=禁止 → 分区不可用 |
生产环境必须false |
default.replication.factor |
1 | 新创建Topic的默认副本数 | ≥3 |
offsets.topic.replication.factor |
1 | 内部Topic __consumer_offsets 的副本数 |
≥3(且≤集群节点数) |
故障恢复手段
-
修复集群节点:
重启宕机的Broker1(前提是硬件/网络修复)。- Controller会自动将其添加回Follower副本。
-
强制解除阻塞(若ISR为空且禁止unclean选举):
# 手动触发unclean选举(可能丢数据!) bin/kafka-leader-election.sh --bootstrap-server 10.6.5.138:9092 \ --topic T --partition 0 --election-type=unclean
-
扩增副本(如果存活副本不足):
# 增加Topic的副本因子(需有足够Broker) bin/kafka-topics.sh --bootstrap-server 10.6.5.138:9092 \ --alter --topic T --partitions 1 --replication-factor 3
预防措施
-
副本规划:
replication.factor = N(集群节点数≥N)。min.insync.replicas = M(通常为N-1或N/2+1)。
-
监控告警:
实时采集以下指标:- 各分区
ISR Count(应≥min.insync.replicas)。 - 是否有分区
Leader=-1。
kafka-cluster-lag: kafka.server:name=PartitionCount,topic=([^,]+),partition=([0-9]+) -> metric: "UnderReplicatedPartitions"
- 各分区
-
部署建议:
- 跨机架/可用区部署Broker,避免单点故障全挂副本。
- 使用
Kafka KRaft(取代ZooKeeper)提升Controller稳定性。
通过确保至少存活 min.insync.replicas+1 个节点,可有效避免选举失败导致的可用性问题。
Kafka 副本不足导致 Leader 选举失败的全解析
核心机制图解
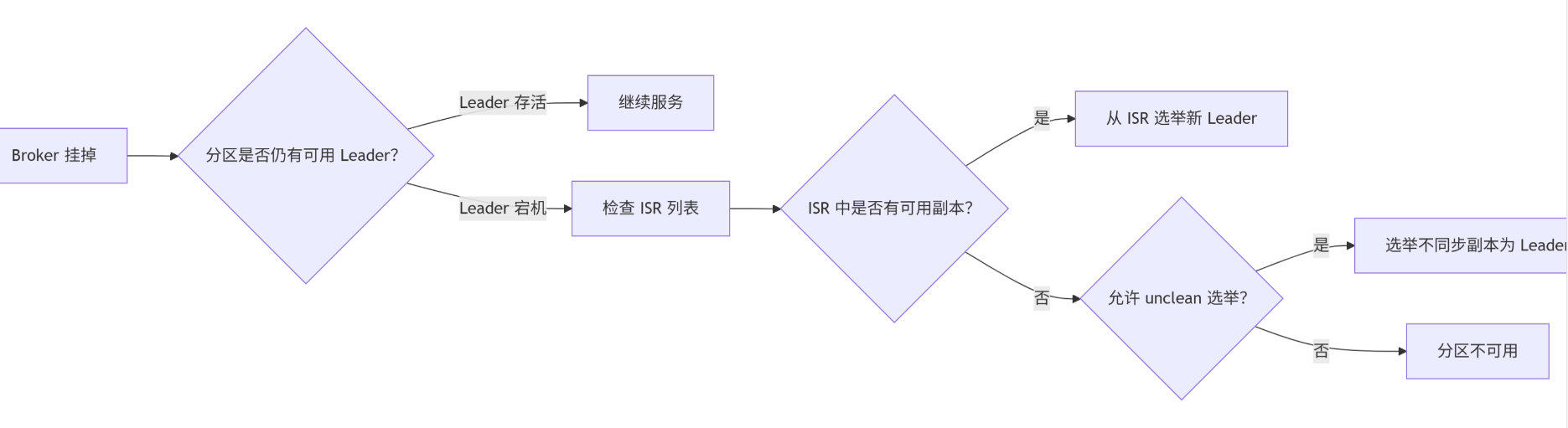
具体故障逻辑分析
1. ISR(In-Sync Replicas)机制失效
- ISR 定义:与 Leader 完全同步的副本集合
- 故障场景:
- 假设分区 P0 配置了 3 个副本(A、B、C)
- Broker A(Leader)和 Broker B(ISR)同时宕机
- 仅剩 Broker C(同步滞后超过
replica.lag.time.max.ms)
- 后果:
- ISR 列表变为空集合
- Kafka Controller 无法选出新 Leader
2. min.insync.replicas 配置约束
- 保护机制:
- 生产者要求写成功的副本数(当
acks=all时)
- 生产者要求写成功的副本数(当
- 故障场景:
- 配置
min.insync.replicas=2 - 初始状态:Leader A + ISR B
- A 和 B 同时宕机
- 配置
- 后果:
- 系统拒绝选举新 Leader,分区进入冻结状态
3. 副本分配不均衡
- 典型场景:
- 分区副本集中分配在少数 Brokers
- 例:P0 副本在 [Broker1, Broker2]
- P1 副本在 [Broker2, Broker3]
- Broker1 和 Broker2 同时挂掉
- 后果:
- P0 无任何存活副本
- P1 仅剩非同步副本
4. unclean.leader.election 策略
- 关键配置:
-
- 当 ISR 为空且此配置为 false 时
- Controller 拒绝选举非同步副本
- 分区保持 Leader=-1 状态
- 数据一致性保护:
- 避免落后副本上位导致数据丢失
实时选举流程图
故障特征判断表
| 特征 | 副本充足 | 副本不足 |
|---|---|---|
| Broker 状态 | 分区自动恢复 | 分区持续不可用 |
kafka-topics --describe |
Leader 立即切换 | Leader 显示 "-1" |
| 生产端表现 | 短暂阻塞后恢复 | 持续抛出 NOT_ENOUGH_REPLICAS |
| 消费端表现 | 自动重连新 Leader | 持续拉取失败 |
| Controller 日志 | "Completed leader election" | "No replica in ISR for partition" |
解决方案优先级
- 紧急恢复: 强制触发 unclean 选举(可能丢数据) kafka-leader-election.sh \ --election-type=unclean \ --topic=your_topic --partition=0
- 副本扩展: 扩展副本因子(需新 broker) kafka-topics.sh --alter \ --topic your_topic \ --partitions 3 \ --replication-factor 4
- 配置优化: 推荐生产环境配置 default.replication.factor=3 min.insync.replicas=2 unclean.leader.election.enable=false
- 架构改造:
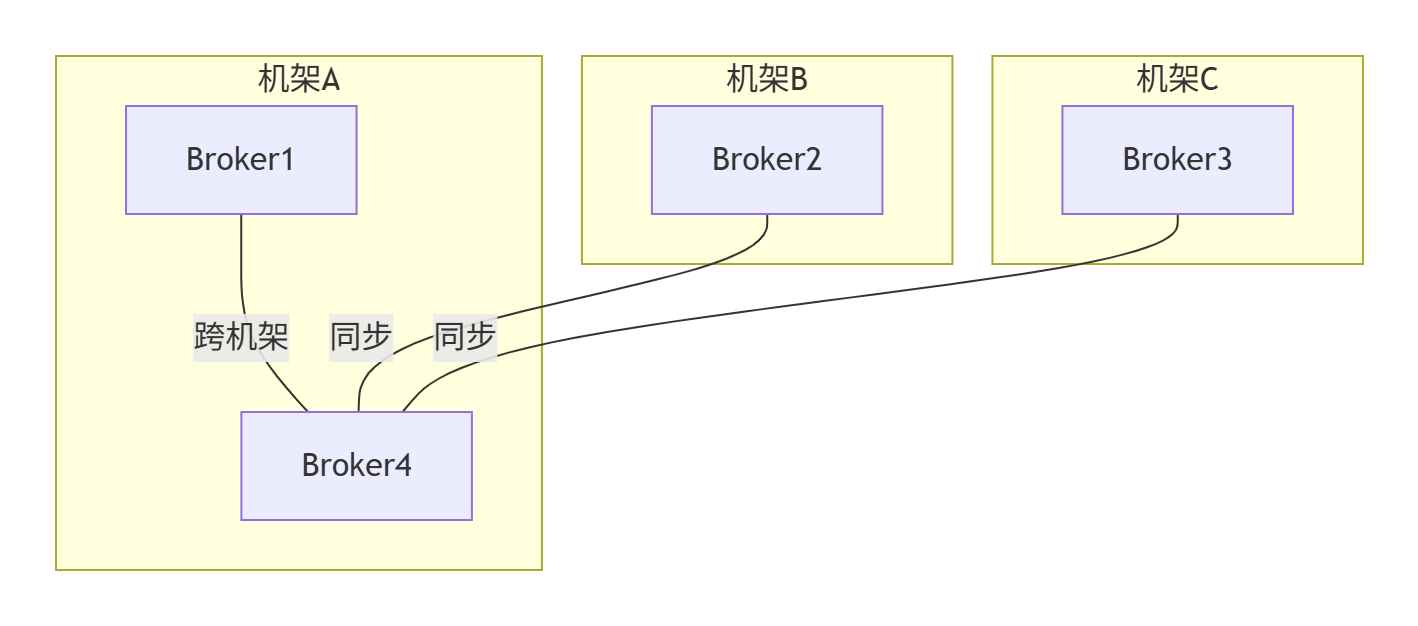
机架感知配置:
broker.rack=A1 replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
最佳实践:设置副本因子 > 故障域数量,并确保每个故障域(机架/AZ)都有完整副本集
副本不足导致的 Leader 选举失败本质是: 数据持久化与可用性的权衡结果。通过合理配置 min.insync.replicas 和副本分配策略,结合机架感知部署,可大幅降低此类故障概率。
linux下的docker操作命令及异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号