Python爬虫之爬取西刺免费IP并保存到MySQL
最近在学习scrapy爬虫框架,刚开始爬取简单网页的图片(妹子图)保存到本地,之后这已经满足不了我了,后来开始爬取大型网站,也会用selenium模拟浏览器操作,以及获取ajax网页数据,在爬取过程中,我发现偶尔会出现一些302错误以及操作频繁的反爬虫策略。所以该文就是来爬取大量免费IP来伪装,从而达到反反爬虫的目的。
首先建立爬虫文件get_ips.py
导入网络框架requests
import requests
新建爬虫函数爬取西刺免费ip网站http://www.xicidaili.com/nn
def crawl_ips():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:55.0) Gecko/20100101 Firefox/55.0'
}
response = requests.get('http://www.xicidaili.com/nn', headers=headers)
导入scrapy的选择器Selector对目标网站HTML进行解析
from scrapy.selector import Selector
在爬取函数中解析每一个ip数据
selector = Selector(text=response.text)
td_nodes = selector.xpath('//tr[@class]')
网站部分数据如下:

将每一个数据的ip地址、端口号、服务器地址、协议类型、速度、存活时间这些数据保存下来
网页部分源码如下

原生数据爬取如下:
for td_node in td_nodes:
td = td_node.xpath('td')
ip = td[1].xpath('text()').extract_first()
port = td[2].xpath('text()').extract_first()
addr = td[3].xpath('a/text()').extract_first()
proxy_type = td[5].xpath('text()').extract_first()
speed_str = td[6].xpath('div/@title').extract_first()
exist_time_str = td[8].xpath('text()').extract_first()
之后对原生数据中的speed_str、exist_time_str进行处理,得到Float类型的时间数据
处理函数如下
def split_str(s, time_des):
return float(s.split(time_des)[0])
def get_second(s):
second = 0.0
if s.endswith('秒'):
second = float(s.split('秒')[0])
return second
def get_hour(s):
hour = 0.0
if s.endswith('分钟'):
hour = split_str(s, '分钟') / 60
elif s.endswith('小时'):
hour = split_str(s, '小时')
elif s.endswith('天'):
hour = split_str(s, '天') * 24
return hour
调用函数处理原生数据:
speed = get_second(speed_str)
exist_time = get_hour(exist_time_str)
通过调试,以上代码可以爬取该网站的第一页所有ip地址数据,远远达不到我们的需求,而该网站一共有2000多页高匿ip地址数据,每一页URL格式如下:http://www.xicidaili.com/nn/%d
所以我设置了一个爬取的最大页数,当然也可以通过解析下一页中的url获取该网站所有数据,但是我们并不需要这么多的数据,所以我只是设置了一个爬取页数的常数
修改如下:
PAGE_COUNT = 100
def crawl_ips():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:55.0) Gecko/20100101 Firefox/55.0'
}
for page in range(PAGE_COUNT):
response = requests.get('http://www.xicidaili.com/nn/%d' % (page+1), headers=headers)
selector = Selector(text=response.text)
td_nodes = selector.xpath('//tr[@class]')
for td_node in td_nodes:
td = td_node.xpath('td')
ip = td[1].xpath('text()').extract_first()
port = td[2].xpath('text()').extract_first()
addr = td[3].xpath('a/text()').extract_first()
proxy_type = td[5].xpath('text()').extract_first()
speed_str = td[6].xpath('div/@title').extract_first()
exist_time_str = td[8].xpath('text()').extract_first()
speed = get_second(speed_str)
exist_time = get_hour(exist_time_str)
接下来将获取到的数据保存到MySQL,由于之前没有接触过MySQL,所以也算是碰到不少灰才算顺利保存数据。
打开我们的神器Navicat Premium(据说官网买好几千刀,当然在国内这个大环境下自然很容易不攻自‘破’)。
创建表xici_ips:
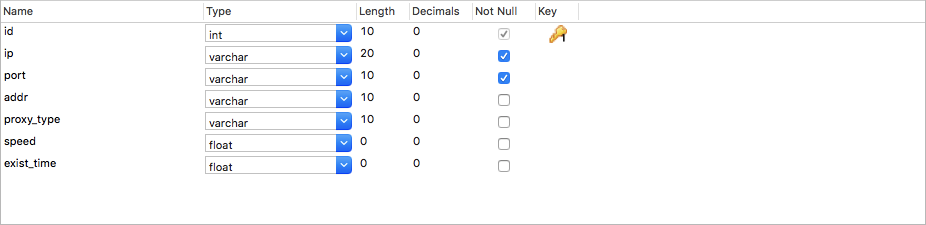
新手的话特别要注意几个坑:
首先是主键id,一定设置默认值(0或1),其次是勾上自增长选项
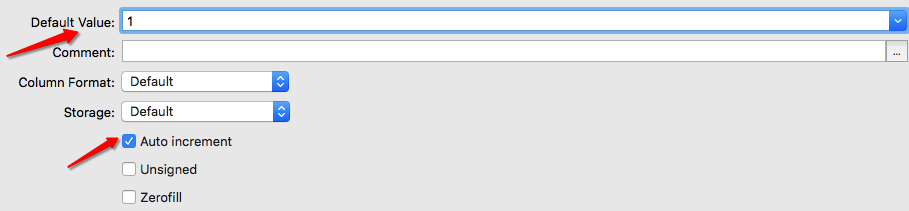
其次是数据字符集,这是个很大的坑。在Python这种执行插入语句时,会抛出错误mysql err 1366,这是字符集不支持中文编码的问题。在我们的数据addr中包含中文,所以在不知情的情况下插入该数据会引发错误,导致无法插入任何数据。解决方法是:在列addr配置中,选择字符集为utf8,如下:

配置完毕后,开始在项目中加入MySQL
这里我们选择的是pymysql模块,理由是MySQLdb模块目前还未支持Python3,只能支持Python2,如果强行执行终端命令pip install MySQLdb会报错,后来百度后可用pymysql代替MySQLdb模块,用法几乎一样。
pymysql模块的安装这里不作解释
在项目中导入pymysql
import pymysql
连接MySQL数据库并创建cursor
mysql_connect = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='keqipu',
database='lagou_db',
charset='utf8',
use_unicode=True
)
cursor = mysql_connect.cursor()
在爬取到所有数据的语句下执行插入语句
insert_sql = """insert into xici_ips(ip, port, addr, proxy_type, speed, exist_time)
values(%s, %s, %s, %s, %s, %s)"""
cursor.execute(insert_sql, (ip, port, addr, proxy_type, speed, exist_time))
mysql_connect.commit()
运行后发现数据成功保存到MySQL数据库

speed单位是s,exist_time单位是h,表示存活时间,这两列用于查询数据时作为重要判断依据
在调试过程中,我发现在删除所有数据后继续执行程序,主键还是在原来的基础上自增长,所以需要将主键重置。
打开mac终端
mysql -u root -p
输入密码便可进入MySQL命令行
进入相应数据库
use lagou_db
将主键重置
ALTER TABLE xici_ips AUTO_INCREMENT= 1;
大功告成!
完整代码如下:
import requests
import pymysql
from scrapy.selector import Selector
PAGE_COUNT = 1
mysql_connect = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='keqipu',
database='lagou_db',
charset='utf8',
use_unicode=True
)
cursor = mysql_connect.cursor()
def crawl_ips():
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.11; rv:55.0) Gecko/20100101 Firefox/55.0'
}
for page in range(PAGE_COUNT):
response = requests.get('http://www.xicidaili.com/nn/%d' % (page+1), headers=headers)
selector = Selector(text=response.text)
td_nodes = selector.xpath('//tr[@class]')
for td_node in td_nodes:
td = td_node.xpath('td')
ip = td[1].xpath('text()').extract_first()
port = td[2].xpath('text()').extract_first()
addr = td[3].xpath('a/text()').extract_first()
proxy_type = td[5].xpath('text()').extract_first()
speed_str = td[6].xpath('div/@title').extract_first()
exist_time_str = td[8].xpath('text()').extract_first()
speed = get_second(speed_str)
exist_time = get_hour(exist_time_str)
insert_sql = """insert into xici_ips(ip, port, addr, proxy_type, speed, exist_time)
values(%s, %s, %s, %s, %s, %s)"""
cursor.execute(insert_sql, (ip, port, addr, proxy_type, speed, exist_time))
mysql_connect.commit()
def split_str(s, time_des):
return float(s.split(time_des)[0])
def get_second(s):
second = 0.0
if s.endswith('秒'):
second = float(s.split('秒')[0])
return second
def get_hour(s):
hour = 0.0
if s.endswith('分钟'):
hour = split_str(s, '分钟') / 60
elif s.endswith('小时'):
hour = split_str(s, '小时')
elif s.endswith('天'):
hour = split_str(s, '天') * 24
return hour
if __name__ == '__main__':
crawl_ips()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号