原文:https://research.swtch.com/hwmm
翻译整理:kefate
引言:单线程的时代已经结束
很久以前,当所有程序都是单线程的时候,让程序变得更快的一个非常有效的方式就是——什么都不做。下一代硬件和下一代编译器会自动让程序运行得更快,行为却丝毫不变。
在那个“童话时代”,是否允许一种优化的判断标准非常简单:如果程序员在行为上感觉不到区别(除了变快),那么这种优化就是允许的。
但这个童话有一天结束了。硬件工程师无法再继续让单核处理器变得更快,他们的新“魔法”是:引入多核处理器,操作系统通过线程抽象将并行能力提供给程序员。
这对硬件工程师很有效,但却给语言设计者、编译器工程师和程序员带来了严重的问题。
很多在单线程中不可见的优化,在多线程中变得“可观察”,从而有可能破坏程序原有的行为。
所以,如果“合法优化”不应该改变“合法程序”的行为,那么就必须进行抉择:是将这些优化宣布为非法?还是将这些程序判为非法?如何选择?又如何判断?
下面是一个 C-like 语言的简单例子(所有变量初始化为 0):
// Thread 1 // Thread 2
x = 1; while (done == 0) { /* loop */ }
done = 1; print(x);
如果 Thread 1 和 Thread 2 分别在各自的处理器上运行完毕,这个程序能打印出 0 吗?
答案是:“看情况”。这取决于硬件,也取决于编译器。
- 在 x86 上逐行翻译执行,不会打印 0(即 x=1 一定先于 print(x))
- 在 ARM 或 POWER 上,可能会打印 0
- 任何平台上,标准的编译器优化也可能导致打印 0,或者让程序陷入死循环
程序员需要一个明确的答案来判断:程序是否能在新硬件或新编译器下继续正确运行。
硬件和编译器设计者也需要一个清晰的契约,规定在执行某个程序时,底层行为被允许到什么程度。
因为问题的核心在于:数据写入内存后对其他线程是否可见、以及何时可见,所以这个契约被称为“Memory Consistency Model”或简称“Memory Model”。
内存模型最早的目标是为汇编程序员定义硬件的行为保证。在这种设定下,编译器并不参与。
但自 25 年前起,研究者开始尝试给高级语言(如 Java 和 C++)定义内存模型,把编译器也纳入其中。这使得模型的定义变得更加复杂。
我们从假设你从“为多核机器写汇编程序”出发,思考这个问题:“程序员需要从硬件得到哪些保证,才能写出正确的程序?”
这是过去 40 多年来计算机科学家一直在寻找答案的问题。
顺序一致性(Sequential Consistency)
1979 年,Leslie Lamport 在论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》中首次提出了顺序一致性这一概念:
“The result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.”
“任意执行的结果应当与以下情况相同:所有处理器的操作被串联成一个顺序执行序列,并且每个处理器自身的操作顺序在这个序列中保持与程序中一致。”
这种模型被称为顺序一致(Sequential Consistency)模型,使用这种模型的硬件是顺序一致的。
我们今天不仅希望硬件提供顺序一致性,还希望高级编程语言能在多线程执行时提供这种语义。
在这种模型下,程序执行就像所有线程的操作交错在一起形成的某种顺序执行一样。
它是目前程序员最容易接受、最理想化的模型:你可以认为程序按代码写的顺序执行,不同线程的语句只是“穿插”而已,不会被打乱。
虽然是否应以顺序一致性为理想模型是个值得讨论的问题(作者并未展开),但直到今天,大多数并发算法的正确性验证,依旧是基于穷举所有可能的线程交错。
我们回到前面的例子,为便于分析,略作简化:
// Thread 1 // Thread 2
x = 1; r1 = y;
y = 1; r2 = x;
所有变量初始值为 0,r1 和 r2 是局部寄存器。我们关心的是:是否可能看到 r1 = 1 且 r2 = 0?
这是一个 litmus test(一种行为是否可发生的试金石)。如果某个模型允许而另一个不允许,则它们的语义显然不同。
如下图所示,在顺序一致模型下,所有可能的线程交错只有六种,但没有一种会导致 r1 = 1 且 r2 = 0。
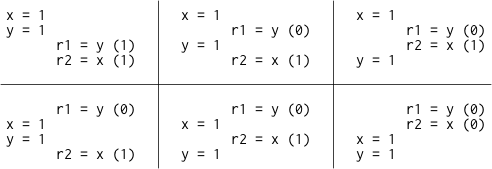
因此,这种结果在顺序一致性的硬件上是禁止的。
我们可以通过一个形象的模型来理解顺序一致性:
- 所有处理器连接到一个共享内存
- 每次只能有一个读或写发生(无缓存)
- 所有访问顺序按唯一时间线排队执行

这种模型直观地体现了“顺序一致性”:所有访问按某个顺序发生,线程内部的执行顺序不能被打乱。
当然,实际系统可能通过缓存、预测等机制实现顺序一致性的外部表现(而不是严格地逐条串行执行),但对程序员而言,关键是它看起来像是按顺序一致执行的。
不幸的是,放弃严格的顺序一致性可以让硬件更快地执行程序,因此所有现代硬件都以各种方式偏离了顺序一致性。
未完待续 —— 下一篇将继续探讨现代硬件如何放弃顺序一致性以换取性能,以及具体的实现方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号