
一、词频统计
A. 分步骤实现
- 准备文件
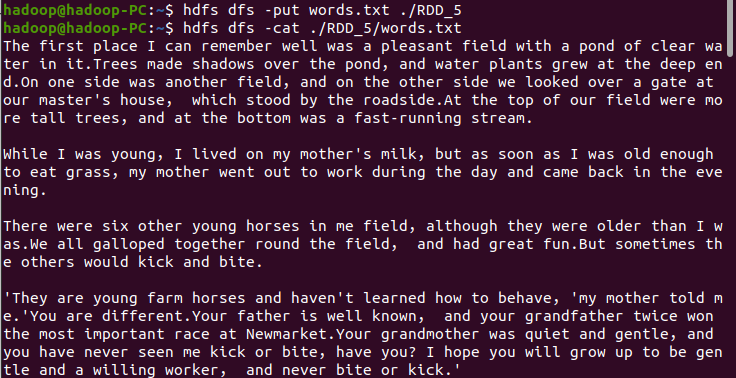
- 下载小说或长篇新闻稿
- 上传到hdfs上
![]()
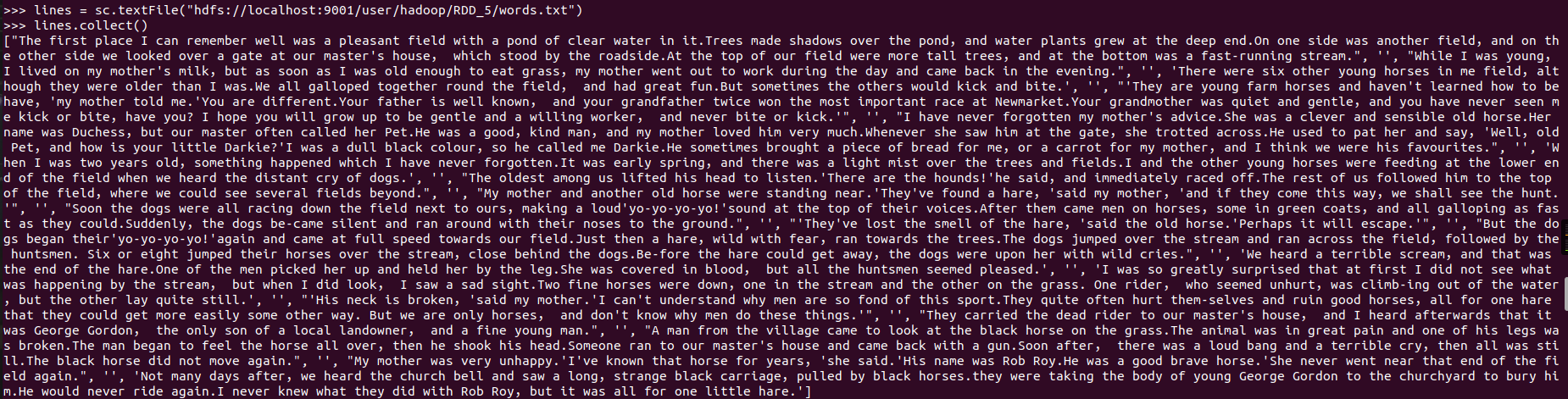
- 读文件创建RDD
![]()
- 分词
![]()
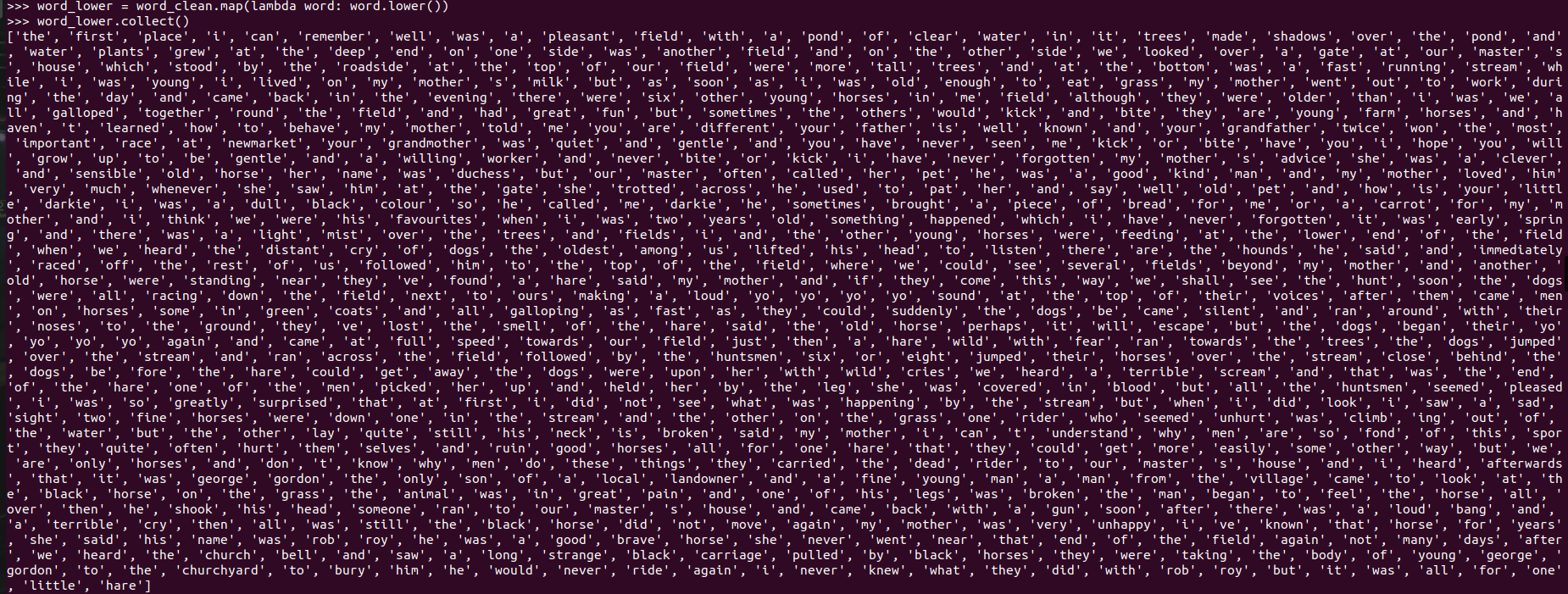
- 排除大小写lower(),map()
![]()
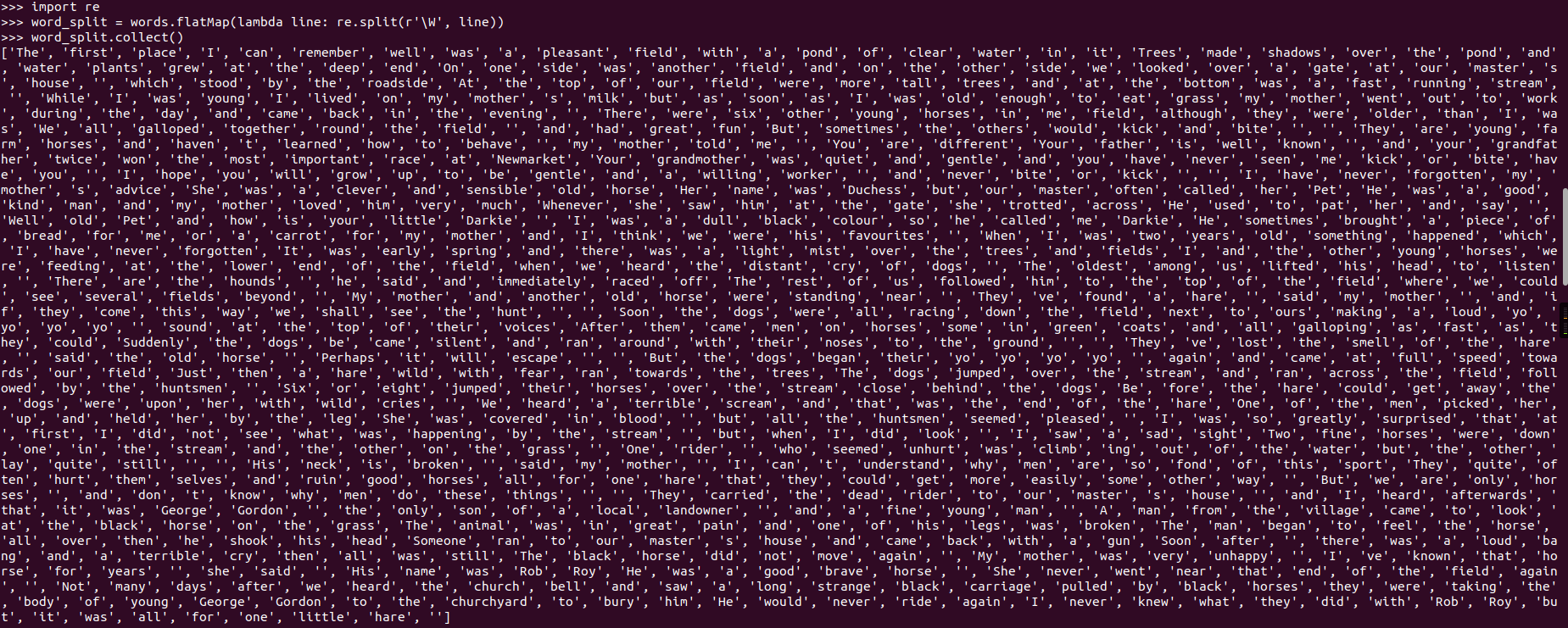
标点符号re.split(pattern,str),flatMap(),![]()
停用词,可网盘下载stopwords.txt,filter(),![]()
长度小于2的词filter()![]()
- 统计词频
![]()
- 按词频排序
![]()
- 输出到文件
![]()
- 查看结果
![]()






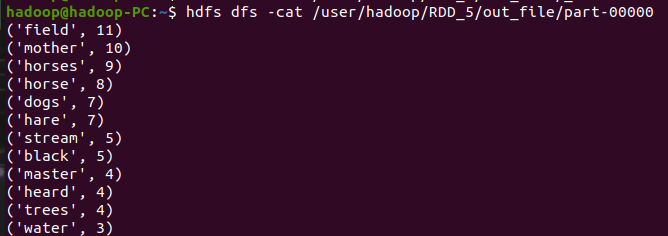
B. 一句话实现:文件入文件出
lines = sc.textFile("hdfs://localhost:9001/user/hadoop/RDD_5/words.txt") \ .flatMap(lambda line: line.split()) \ .flatMap(lambda line: re.split(r'\W', line)) \ .flatMap(lambda line: line.split()) \ .map(lambda word: word.lower()) \ .filter(lambda x: x not in stopwords) \ .filter(lambda x: len(x) > 2) \ .map(lambda a: (a, 1)) \ .reduceByKey(lambda a, b: a + b) \ .sortBy(lambda x: x[1], False)
C.和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解Spark编程的特点。
# 1导入模块 # 导入字符串模块 import string # 2读取文件,并分词 list_dict = {} # 创建一个空字典,放词频与单词,无序排列 data = [] # 创建一个空列表,放词频与单词,有序:从多到少 f = open('test.txt', 'r') # 打开文件 content = f.read() # 读取文件 f.close() # 关闭文件 content = content.replace('-', ' ') # 连字符—用空格代替 words = content.split() # 字符串按空格分割--分词 # 迭代处理:将字典变列表,存入数据 for i in range(len(words)): words[i] = words[i].strip(string.punctuation) # 去掉标点符号,去掉首尾 words[i] = words[i].lower() # 统一大小写 if words[i] in list_dict: # 统计词频与单词 list_dict[words[i]] = list_dict[words[i]] + 1 # 不是第一次 else: list_dict[words[i]] = 1 # 第一次 # print(list_dict) # 打印字典(词频与单词,无序) # 遍历字典 for key, value in list_dict.items(): # 遍历字典 temp = [value, key] # 变量,变量值 data.append(temp) # 添加数据 data.sort(reverse=True) # 排序 print(data) # 打印列表(词频与单词,有序,从多到少)
Spark编程的特点:利用lambda函数比较多,代码少,简单方便
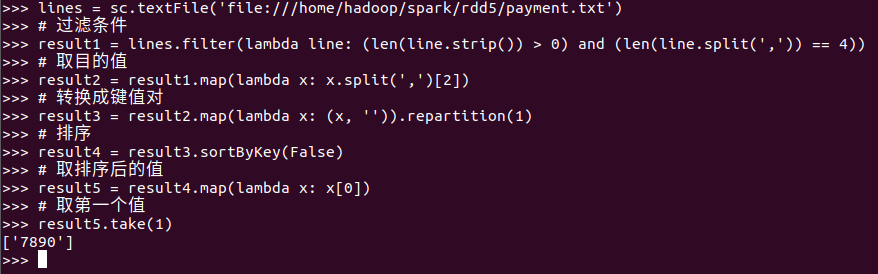
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号