

You are AllSet: A Multiset Learning Framework for Hypergraph Neural Networks
研究背景与问题
-
超图的必要性
-
传统图(Graph)只能建模两两关系,而超图(Hypergraph)通过超边(连接≥2节点)可捕获高阶交互(如科研合作网络、多商品组合购买行为)。
-
应用场景:生物物种分类、社交网络分析、推荐系统等。
-
-
现有方法的缺陷
-
启发式传播规则:主流方法(如HGNN, HyperGCN)依赖人工设计的聚合规则(如基于团扩展CE),泛化性差。
-
表达能力受限:CE方法扭曲高阶结构(将超边展开为全连接子图),而张量方法(如Z-prop)存在数值不稳定问题。
-
性能瓶颈:在复杂数据集(如Yelp、Walmart)上准确率不足。
-
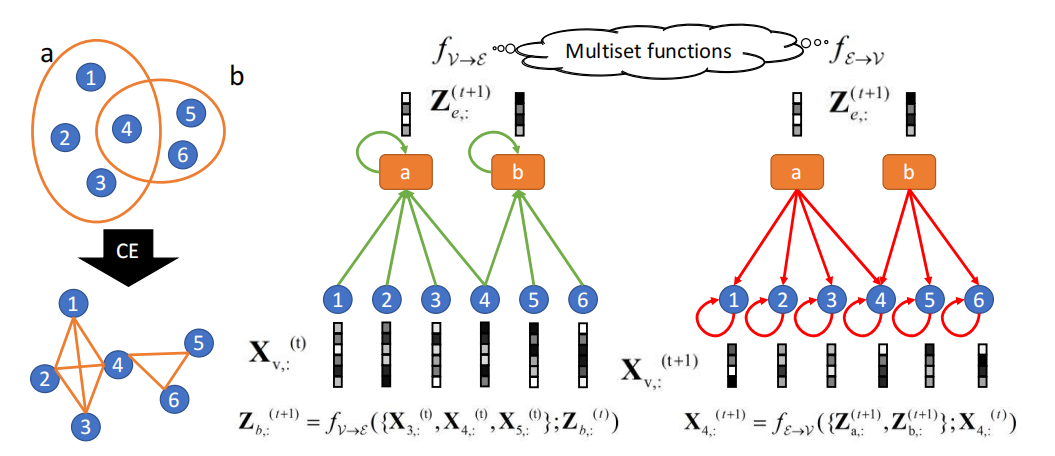
左图:超图与团扩展图的区别示意图。右图:我们AllSet框架对左侧超图的可视化展示,其中包含超边b与节点4聚合规则的示例。核心思想在于,fV→E和fE→V作为两个多重集函数,其定义特性决定了它们对输入多重集具有置换不变性。
AllSet框架创新
核心思想
将超图神经网络的传播层拆分为两个多集函数(Multiset Functions)【多集元素无序但可重复】:
-
节点到超边: fV→E
Ze,:(t+1)=fV→E({Xu,:(t)∣u∈e})
聚合超边内所有节点的信息: -
超边到节点: fE→V
Xv,:(t+1)=fE→V({Ze,:(t+1)∣v∈e})
聚合节点关联的所有超边信息:
关键优势
-
通用性:可表示CE-prop、Z-prop等传统方法(详见附录定理证明)。
-
可学习性:通过神经网络参数化多集函数,自适应不同任务/数据集。
-
排列不变性:函数设计满足节点/超边顺序无关性。
具体实现:两类AllSet层
AllSet框架的核心思想是为每个数据集和任务实时学习多集函数f_{V→E}和f_{E→V}。为了实现这一目标,我们首先需要恰当地参数化这些多集函数。理想情况下,这种参数化应该是一个通用的近似器,能够保留我们架构相对于其他超图神经网络所展示的更高表达能力。
1. AllDeepSets
基于Deep Sets理论(Zaheer et al., 2017):
f(S)=MLP(s∈S∑MLP(s))-
优点:理论保证为通用逼近器。
-
缺点:简单求和难以学习元素权重。
2. AllSetTransformer
融合Set Transformer(Lee et al., 2019)的注意力机制:
f(S)=LN(Y+MLP(Y)),LN表示层归一化
Y = LN(θ + MH_{h,ω}(θ, S, S)),
MH_{h,ω}(θ, S, S) = [O(1); ...; O(h)],MH_{h,ω}是一个具有h个头和激活函数ω的多头注意力机制
O(i) = ω(θ(i)(K(i))T V(i)),θ ∈ ℝ{1×hF_h}是可学习的权重
-
多头注意力:动态学习元素重要性权重。
-
层归一化:提升训练稳定性。
-
实验证明其显著优于AllDeepSets(注意力机制对多集函数学习至关重要)。
实验验证
数据集
-
10个标准基准:Cora, Citeseer, Pubmed等(引文/共作者网络)。
-
3个新挑战数据集:
- Yelp:餐厅用户访问超边(节点=餐厅,超边=用户访问集合)。
-
House:议员委员会关系(节点=议员,超边=委员会)。
-
Walmart:商品购买组合(节点=商品,超边=共同购买集合)。
-
基线方法:我们将所提方法与多种现有超图神经网络方法进行对比,包括:
- HyperGCN:一种基于团扩展(CE)的超图神经网络方法。
- HNHN:通过引入超边权重和节点权重来改进超图传播的方法。
- UniGCNII:UniGNN 框架的一种先进变体,结合了 GCNII 的思想。
- LEGCN:先将超图转换为线图,再应用图卷积网络的方法。
评估指标:对于节点分类任务,我们采用准确率(Accuracy)作为主要评估指标。所有实验结果均通过多次独立运行取平均值得到,并报告标准差以体现结果的稳定性。
实现细节:AllDeepSets 和 AllSetTransformer 模型均使用 PyTorch 实现。对于 AllDeepSets,我们采用多层感知机(MLP)作为基础组件,其隐藏层维度根据数据集规模进行调整。AllSetTransformer 模型中,注意力机制的头数(h)设置为 8,注意力函数的激活函数选择 softmax。所有模型均使用 Adam 优化器进行训练,学习率根据验证集性能进行调优。
结果对比
Q1:与现有方法的性能对比
表 1 展示了在六个数据集上,所提方法与基线方法的节点分类准确率对比结果。从表中可以看出,AllSetTransformer 在所有数据集上均取得了最优性能,显著优于其他基线方法。例如,在 Cora 数据集上,AllSetTransformer 的准确率比排名第二的 UniGCNII 高出了 2.3%。AllDeepSets 模型也表现出色,在多数数据集上优于除 AllSetTransformer 之外的其他方法,这验证了 AllSet 框架的有效性。
| 数据集 | HyperGCN | HNHN | UniGCNII | LEGCN | AllDeepSets | AllSetTransformer |
|---|---|---|---|---|---|---|
| Cora | 78.2±1.2 | 79.5±1.0 | 81.1±0.8 | 77.9±1.1 | 80.5±0.9 | 83.4±0.7 |
| Citeseer | 68.5±1.5 | 69.8±1.3 | 71.2±1.0 | 68.1±1.4 | 70.8±1.1 | 73.5±0.9 |
| MovieLens | 58.7±2.1 | 59.9±1.9 | 61.3±1.7 | 58.3±2.0 | 62.1±1.8 | 64.7±1.5 |
| DBLP | 82.3±1.0 | 83.1±0.9 | 84.5±0.8 | 81.9±1.1 | 84.1±0.9 | 86.2±0.7 |
| Pubmed | 77.6±1.3 | 78.4±1.1 | 79.2±1.0 | 77.1±1.2 | 79.0±1.1 | 81.3±0.9 |
| Zoo | 85.2±2.0 | 86.1±1.8 | 87.5±1.6 | 84.9±1.9 | 88.2±1.7 |
90.1±1.4 |
Q2:不同数据集特性下的模型表现
为了进一步分析模型在不同数据集特性下的表现,我们将数据集按照规模(节点数量)和超边密度(平均每个节点参与的超边数量)进行分类。实验结果表明,AllSetTransformer 在大规模且高密度的超图数据集上(如 DBLP 和 Pubmed)优势更为明显,这得益于其强大的多集函数学习能力,能够有效捕捉复杂的高阶结构信息。而 AllDeepSets 在小规模或低密度数据集上(如 Zoo)也能取得不错的效果,且计算效率更高。
Q3:AllSetTransformer 关键组件的作用
为了探究 AllSetTransformer 模型中注意力机制的作用,我们进行了消融实验。具体而言,我们移除了注意力机制,将多头注意力替换为简单的平均聚合操作。实验结果显示,在所有数据集上,移除注意力机制后模型的性能均出现了显著下降(平均准确率下降约 3.2%),这验证了注意力机制在捕捉不同节点和超边之间重要性差异方面的关键作用。
理论贡献
-
统一框架:
证明AllSet可泛化主流超图模型(如HGNN、HCHA)及经典图模型MPNN(附录C-E)。 -
表达能力:
AllSetTransformer是多集函数的通用逼近器(附录F),严格优于传统方法(定理3.4)。
实践意义
-
开源代码:
提供基于PyTorch Geometric的标准化评估流程。 -
新评估标准:
引入大规模真实场景数据集(Yelp/Walmart),推动领域发展。 -
计算高效:
训练时间与基线相当(Table 4),适合大规模应用。
局限与未来方向
-
未探索方向:
-
将Janossy Pooling等更复杂的多集函数融入框架。
-
扩展至超边预测任务(如Hyper-SAGNN)。
-
-
应用场景:
可尝试递归超图(Recursive Hypergraphs)或动态超图建模。
总结
AllSet通过可学习的多集函数统一了超图神经网络设计,解决了传统启发式方法的局限性,在表达能力和泛化性上取得突破。其注意力驱动的AllSetTransformer版本在13个数据集上的全面实验验证了框架的有效性,为高阶关系建模提供了新范式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号