

SQL Server – 树结构 (二叉树, 红黑树, B-树, B+树)
前言
很久以前有学习过各种树结构, 但后来真的没有在实际项目中运用到. 毕竟我主要负责的都是写业务代码. 太上层了
但是忘光光还是很可惜的. 所以久久可以复习一下. 记得概念也好, 帮助思考.
参考:
YouTube – How to Create Database Indexes: Databases for Developers: Performance #4 (必看)
YouTube – mysql底层原理-二叉树、红黑树、BTree、B+Tree (必看)
怎样保存资料, 怎样找的快?
如果我们有个 Array, 里面装了 1-100 凌乱的数字,
const numbers = [20, 15, 99, 75, 100, 1, 15, 8, ...]
如果想找出其中一个号, 那么就得 for loop 每一个号码.
日常生活给我们的经验是, 东西乱就找得慢, 要找的快, 那么东西就要存放好好, 有规律.
像这样
const numbers = [ [1, 2, ...50], [51, 52, ...100] ];
首先要保存的数据要排序. 然后是拆分 (所谓的二分查找). 最外层 for loop 只有 2 个 child array (各负责 50% 数据)
如果发现找的号数在 1-50 那么就 for loop 1-50 的 array 就可以了, 这样就直接过滤掉了另外 50% 的数据.
上面只是一个概念, 我们还可以拆分的更细. 比如 [51-75], [76-100] 以此类推.
二叉树
二叉树就是通过有规则的保存方式来确保找的快的.
它的规则是左小右大.
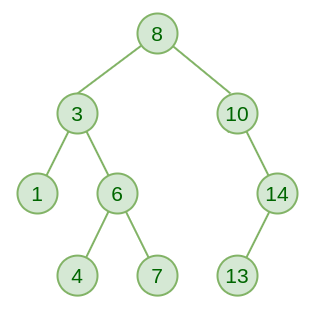
如果目标是 7, 那么从最上面 8 开始,
7 小于 8 所以肯定在左边, 那么右边的数据 (10, 14, 13) 直接忽视掉. 以此类推
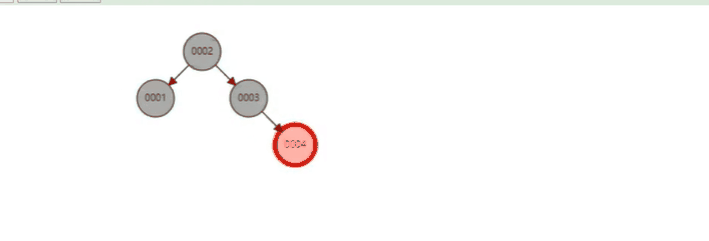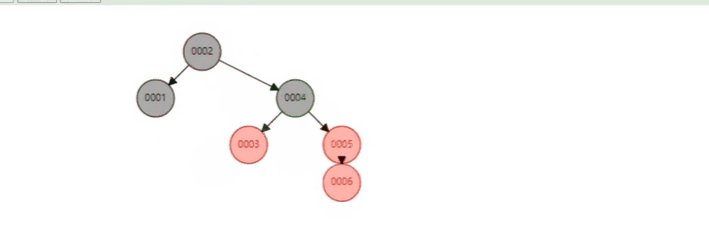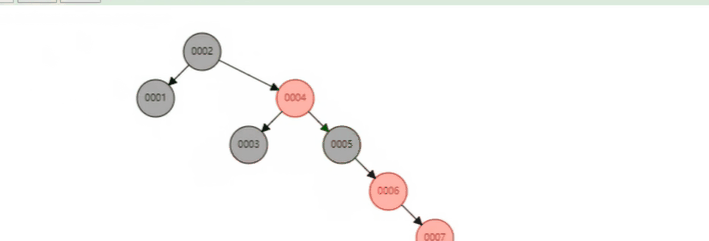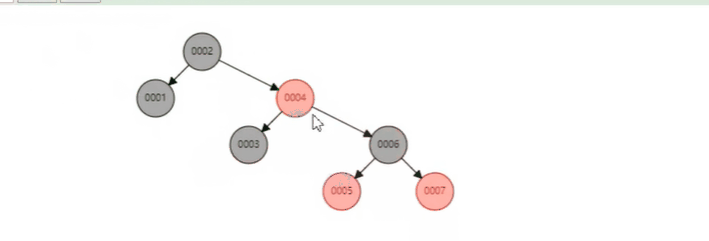
二叉树的问题在于, 它不一定平衡. 如果顺序插入 1-7, 那么它会长这样

所有数据都往右边长, 这完全就不是二叉树了丫.
于是我们需要添加一些规则给它. 在保持左小右大规则的同时又能兼顾平衡. 不要所有数据都往一边靠.
红黑树
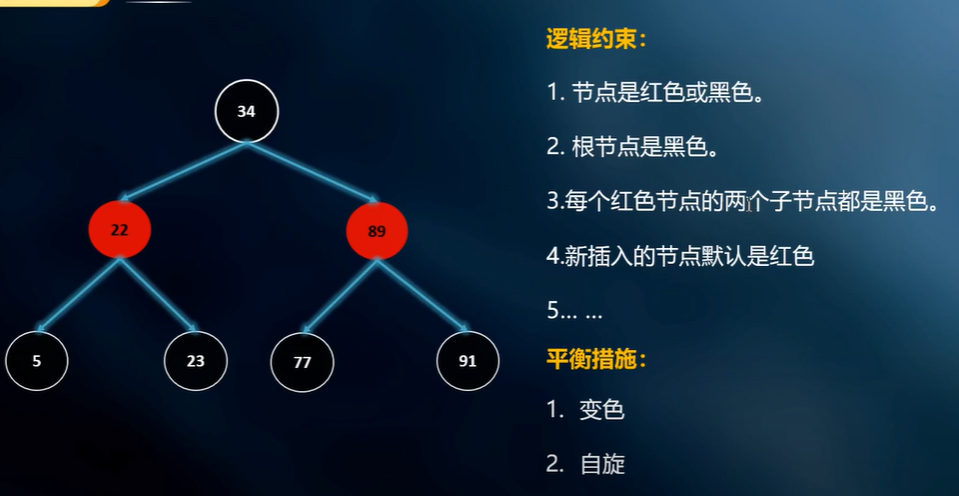
红黑树的规则可以确保树支的方向是平均生长的.
每当新节点插入的时候, 为了要满足规则, 树结构就必须做调整. 当然这个调整是有消耗的. 但为了找的时候快, 只能让插入的时候变慢. 这就是 trade-off
B 树
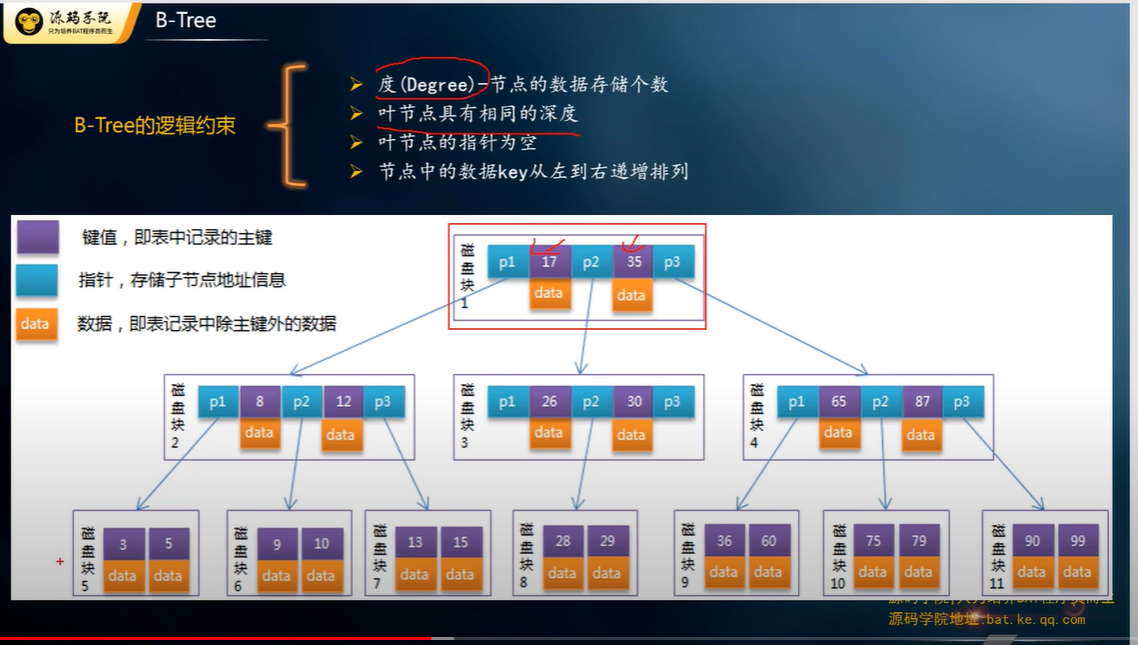
B 树又对红黑进行了优化, 它利用了磁盘预读原理, 加大了树的宽度 (MySQL 16kb, SQL Server 8kb per page), 减少了树的高度.
磁盘每一次读多少是不确定的, 因为系统会缓存, 可能把几次读操作合并一起做, 参考: 磁盘读写与数据库的关系
预读是因为局部性原理, 通常当你需要一个资料, 它附近的资料你也会想要用到. 而且顺着读性能不大, 所以就顺便预读出来了.
B+ 树
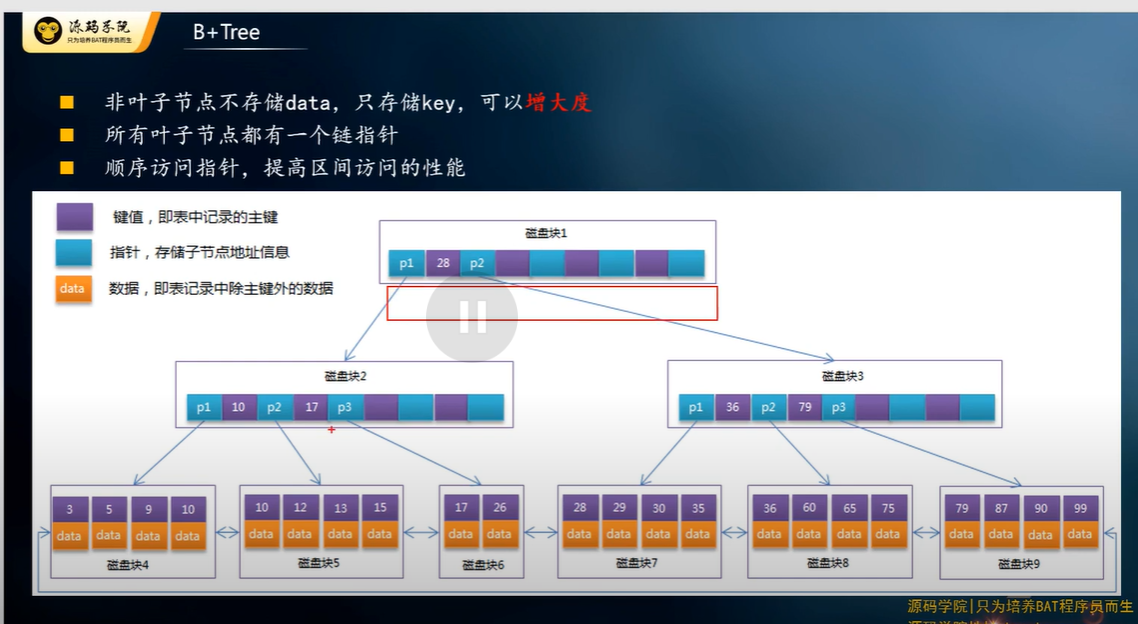
对 B 树做了优化, data size 太大, 会导致磁盘块太大, 于是把 data 都移到了最底部, 这样就先查找关键字, 然后才去拿资料. 这也说明为什么索引只能 450 字 (索引就是查找关键字, 在上层, 起到 column data 在底层).
结论
数据库的设计和找字典是一样概念, 上面这些磁盘块, 就好比字典的目录,
比如我找 Derrick 这个字, 一页一页翻肯定很慢, 但是有一个 A-Z 的目录, 里面就 26 个字母.
先把目录读出来, 然后 loop 到 D, 那么就锁定 D 的范围了. 过滤了大部分不相关的字.
所谓的 index 就是目录. 依据不同 column 排序.
p.s 红黑, B 树 抽象都是平衡二叉树, 目的都为了平衡, B-树就是B树来的. 只是因为有一个B+树所以就把原来的叫B-树.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号