

Bit, Byte, ASCII, Unicode, UTF, Base64
前言
做项目偶尔会接触到 stream 这个感念,不管是 memory stream 还是 file stream,它们又会提到 bytes。
还有像 Identity – 安全基础知识 中提到的 SHA-256,非对称加密等等,在 ASP.NET Core 操作这些也都是用 bytes。
而提到 bytes 又经常会牵扯出 ASCII,Unicode 这些鬼东西。所以这一篇就让我们来了解它们究竟是什么吧。
参考:
阮一峰 – 字符编码笔记:ASCII,Unicode 和 UTF-8
Bit
bit 又叫比特. 是数码世界中最小的单位。一个 bit 就代表一个二进制 (binary),0 或者 1。
在数码世界里,万物就是用 0 和 1 来表达的,为什么要用二进制来表达呢?看这一篇 计算机为什么采用二进制?
其中一个原因是通信可以靠电压高低来表示 0 或 1,这样实现起来会很容易,看这篇 李永乐老师 – How does the chip internally perform addition operations?
ASCII
想象一下,如果我发一串长长的电压给你,有高有底,然后问你,知道我说什么吗?
你肯定不知道,因为表达除了声音以外,还要有规则丫,就好比摩斯密码那样。
我们先看看英文,英文的结构是首先有 26 个字母、空格、标点符号。
把 a-z 字母拼接起来就变成单字,在通过拼接单字 (空格作为分割),标点符号,最后变成句子。
所以下一步就是制定一个规则,把二进制转换成英文,这样就可以通信了。
ASCII 就是干这件事儿的。它规范了 a-z、A-Z、0-9、空格、各种符号,每一个对应的二进制数。
举例:
0 = 48,1 = 49,A = 65,a = 97... 以此类推。(注:这里写的是十进制,只是为了方便我们看)
最终 ASCII 定义了 128 个表达,里面包括了各种字母和符号,参考: Wikipedia – ASCII
比如 digit 0 对应的代号是 48 (十进制),转换成二进制就是 110000

通常一个字符会有 2 个形式表达,一个是 Code 一个是 Decimal。
Decimal 是十进制数,Code 则是十六进制 (前面再加上 U+)
总之,一个字符对应一个数(这个数不管是用二进制,十进制 或 十六进制来表达都是同一个数来的)
Byte
ASCII 字典里,一个字符对应的是一组 bit,比如 0 = 110000,a = 1100001。
这一组 bit 的长度是不一致的,0 是 6 bit,a 是 7 bit。
当我们收到一串长长的电压时 (e.g. 0011000001100001),具体要怎样去找字典呢?
总不可能说,有短的就马上配对,那长的起不是永远都配不上了🤔。
所以我们还需要一个切分的规则,这就是 byte 的概念。
1 byte = 8 bit,把上面的电压切分成 byte 就成了 [00110000, 01100001]。
一个字符就对应一个 byte,这样就有规则去找 ASCII 字典了。
那为什么是按照 8 个 bit 来切分呢?为什么不是 10 个?感兴趣的朋友可以去考古一下:What is the history of why bytes are eight bits? 和 Quora – Why is one byte = 8 bits, even on a 16 or 32-bit machine?
那为什么 110000 变成了 00110000 (前面多了两个零) ?因为要充数丫,切分规则是每 8 个 bit 切一刀成 1 个 byte,1 byte 等于 1 个字母,所以即使字母不需要 8 个 bit,也需要硬硬凑数到 8 bit。
8 个 bit 可以 cover 从 00000000 到 11111111 一共 2^8 = 256 个不同的排列,也就是说可以表达出 256 个不同的冬冬,ASCII 定义所有字母和符号只需要 128 个而已,最多只用到 7 个 bit,所以 ASCII 的 byte 第一个 bit 一定是 0。
总之有了 byte,就可以把长长的 bits 切断,一个一个 byte 去找字典转换成字母,这样英文词就慢慢拼出来了。
补充知识:
参考:
详解计算机中的字、字节(Byte)、比特(bit)及它们之间的关系
Youtube – How computer memory works
byte 是一个单位,
1 byte = 8 bits.
1 kb = 2^10 = 1024 bytes. 因为是 2^10 所以是 1024 而不是 1000 bytes (为什么1KB等于1024字节而不是1000字节?)
补充:
参考: What is the difference between Kilobits and Kilobytes ? 和 KB to Bytes Conversion
1 kB (kilobyte) = 1000 Bytes (in decimal, k 小写)
1 KB = 1024 Bytes (in binary, K 大写)
1 KiB (kibibytes) = 1.024 KB = 1024 Bytes
所以要非常清楚的表达 1024 最好使用 KiB, 避免不必要的混乱, 比如 Google Light 就用 KiB 来表达

经常听到 OS, CPU, 软件 有分 32-bit (x86) 和 64-bit (x64), 它们是啥? 参考: 为什么好多软件都区分32位和64位,到底有什么区别?

它们指的是 CPU 一次可以处理多少位字的信息, 32-bit 就是 32 bits 也就是 4 个 bytes. 而 64-bit 就是 8 个 bytes.
那为什么说 32-bit 只能支持 4 GB ram 呢? 看 32位CPU最多支持4G内存是怎么算出来的?(解惑篇)和 知乎 – 32位系统只能寻址4G空间,64位则是128G,这些是怎么算出来的?
内存的最小单位是 bytes (CPU 1 次读 ram 最少就是拿 1 byte 的意思), 32-bit 可以表示 2^32 = 4294967296 状态, 1 个对应 1 个内存地址的话就是可以操控 4294967296 bytes
换算到来就是 4294967296 / 1024 become kb / 1024 become mb / 1024 become gb = 4gb.
Unicode
ASCII 是英文对应二进制的字典,那其它语言呢?汉字、日文、怎么办?简单丫,继续往上加呗。于是就有了 Unicode。
比如:
严 = 20005

截至 2022 年 2 月 19 日,Unicode 定义了 144,697 个字符,用二进制表示的话需要 18 个 bits 才足够。
早年 Unicode 只用 16 进制而已,所以一般会说 2 bytes 就足够,但是 2 bytes = 16 bits = 2^16 = 65536 表达,哪里够 144,697。
所以现在是用 32 进制 4 bytes 了。
定义是 ok 了,但 1 - 4 bytes 才能表达 1 个字符,那要怎么知道拿到多少 bytes 的时候去查 Unicode 字典找出对应的字符呢?
总不能强制每个字符都占据 4 bytes 吧,这太浪费磁盘空间,网络带宽,传输速度了吧。
软件工程里有一句话,没有任何一个问题是不能通过多加一层去解决的,如果有那就再加一层。
于是,就有了 UTF-8。
UTF-8
UTF-8 是一种 Unicode 的实现手法, 它依然遵守 1 byte = 8 bits 原则. 刚才我们说 ASCII 用了后面 7 个 bits, 最前面还有一个 bit 是 0.
这就让它有了利用价值. 如果发现开头是 1 就表示它是一个 Unicode 然后需要去拿下一个 byte. 具体规则看这里.
总之就是一种解析规则, 通过识别几个 bytes > 从 bytes 里获取最终的二进制 > 去找 Unicode 字典 > 得出字符串.
UTF-8 还向后兼容了 ASCII, 又通过巧妙的设计, 让只有需要很多 bits 的字符才真的用到那么多 bits. 所以它收到了大家的青睐.
UTF-16, 32
UTF-16, 32 也是对 Unicode 的一种实现, 解析的规则不一样而已.
它们其实各有特色. 可以参考:
Unicode 编码及 UTF-32, UTF-16 和 UTF-8
简单说, UTF-8 的优势是, 按需用量, 节省空间. 然后兼容 ACSII. 所以它既可以保留英文为主的场景, 又可以兼容后续的语言. 这就成为了大家最喜爱的了.
UTF-16 本来是有它的优势的, 但后来随着 Unicode 越来越多, 它根本支持不完. 所以优势也没了.
取而代之的是 UTF-32, 如果 1 个字符需要用到 32 bits 那么用 UTF-8 来处理其实不会比 UTF-32 来的好. 毕竟多一层处理.
所以有时候会看到处理信息时会把它 convert to UTF-32. 尤其是非英文内容时
UTF-8 vs UTF-16
这里拿一个阮一峰老师文章中的例子
"严“ 这个中文字在 Unicode 字典里对应的二进制是 100111000100101
如果用 UTF-8 的规则, 最终需要 3 bytes [11100100, 10111000, 10100101]
而 UTF-16 只需要 2 bytes [100101, 1001110]
总结
Unicode 只规定, 一个字母或符号对应的二进制. 至于这一个字母的二进制你要用多少个 bytes 来保存那它不管的.
UTF 则是负责规定多少个 bytes = 1 个字母.
UTF-8 最少 1 bytes = 1 字母, 当一个 1 bytes 不足够它会用更多 bytes 来表示 1 个字母
UTF-16 最少 2 个 bytes = 1 字母
UTF-32 最少 4 个 bytes = 1 字母
因为英文占据了多数, 所以 UTF-8 最 popular. 但从上面 "严" 的例子可以看出. 如果字母本身需要超过 1 byte, 用 UTF-8 反而会用更多 space.
因为它需要加入额外的信息让 decoder 知道这个 byte 还不足够, 需要再加上下一个.
Base64
参考:让你彻底理解Base64算法(Base64是什么,Base64解决什么问题,Base64字符串末尾的=是什么)
用 ASCII 来表达任何 Unicode
Base64 的坏处是会让内容变大, 大概变成 135% 左右.
好处就是它可以确保传输完整 (有些旧设备比如路由器只支持 ASCII)
Base64 URL
Base64 同时符合 URL 限制的字符. 这样几乎任何字符都可以通过 URL 传递了.
ASP.NET Core Bytes & String Conversion
var valueByte = System.Text.Encoding.ASCII.GetBytes("test"); var valueString = System.Text.Encoding.ASCII.GetString(valueByte);
System.Text.Encoding.Unicode 就是 UTF-16 来的, 比较常用的应该是 UTF-8 (网页都是跑这个)
参考: Hashing a string with Sha256
比如: ASP.NET Core 要做 SHA256 是这样: HashAlgorithm.ComputeHash Method
var source = "Hello World!"; var hashBytes = SHA256.HashData(Encoding.UTF8.GetBytes(source)); var stringBuilder = new StringBuilder(); for (int i = 0; i < hashBytes.Length; i++) { stringBuilder.Append(hashBytes[i].ToString("x2")); // 转成十六进制 } var hash = stringBuilder.ToString(); Console.WriteLine(hash); // 7f83b1657ff1fc53b92dc18148a1d65dfc2d4b1fa3d677284addd200126d9069
图片编码
我曾经有个疑问, 图片也是 Unicode 吗? 当然不是.
一个文件, 储存的就是 bytes, 一堆的二进制而已.
这些二进制表达着什么, 取决于你怎么去看它.
知乎 – 为什么同样是二进制编码的数据,从计算机内部来看都是一堆0/1代码,有的数据就是文字,而有的是图片?
比如, txt 代表文字内容文件. 把它的 bytes 拿出来后, 通过 ASCII Unicode 规范字典, 翻译成了人类看得懂的字符.
.jpeg, .webp 是图片文件, 把它的 bytes 拿出来后, 就要对照图片编码的字典, 翻译成图像让人类看得懂 (其实对显示器来说, 字符, 图像是一样的, 就是亮几颗灯管的不同而已)
所以每当我们用错了解析器, 就无法显示正确的内容了, 比如你用 notepad 打开一张图, 它会去拿 bytes 然后对 Unicode 做翻译, 结果当然是乱七八糟. 因为图片有自己的编码规则.
二进制, 十进制, 十六进制
上面提到的都是讲二进制对应的字母和符号. 和十进制, 十六进制没有什么关系.
十进制, 十六进制只是另一种表达手法而已.
二进制是 0 和 1, 两个号而已, 到号了就进位.
十进制就是我们熟悉的 0123456789 它比 2 进制多了 8 个号 3456789 所以叫 10 进制. 同样的, 到号后就进位.
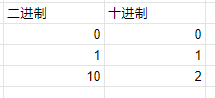
二进制没有 “2” 这个号, 所以就进位成 10 了. 而十进制则可以用 "2" 来表达.
十六进制又比十进制多了 6 个号. 它们是 abcdef
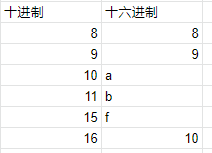
二进制的 10 = 十进制的 2
十进制的 10 = 十六进制的 a
所以同样的 10 在不同的进制情况下表达的数是不同的. 这是我们要清楚的.
JS binary convert
Number(30).toString(2); // 转成二进制 11110 Number(30).toString(10); // 转成十进制 30 Number(30).toString(16); // 转成十六进制 1e parseInt('1e', 16); // 十六进制 转成 十进制 30
C# binary convert
var value1 = Convert.ToString(30, 2); // 转成二进制 11110 var value2 = Convert.ToString(30, 10); // 转成十进制 30 var value3 = Convert.ToString(30, 16); // 转成十六进制 1e var value4 = Convert.ToInt16("1e", 16); // 十六进制 转成 十进制 30
各个类型的 online convertor :

 浙公网安备 33010602011771号
浙公网安备 33010602011771号