
Linux课程总结分析报告
Linux系统概念模型
如图所示,Linux 操作系统是由 Linux 内核、Shell、文件系统和 Linux 应用程序这四部分组成。
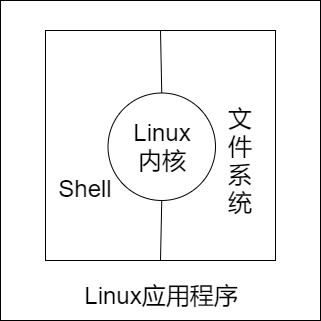
一、Linux内核
内核是 Linux 操作系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,其从用户那里接受命令并把命令送给内核去执行。
1. 用户态和内核态
Linux 所谓的用户态和内核态,本质是对 CPU 提供的功能的一层封装抽象。用户态下和内核态下工作的程序有很多差别,最重要的差别就在于特权级的不同。运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态。
用户态就是提供应用程序运行的空间,为了使应用程序访问到内核管理的资源例如 CPU,内存,I/O。内核必须提供一组通用的访问接口,这些接口就叫系统调用。
2. Linux进程管理
2.1 进程结构
为了描述控制进程的运行,系统中存放进程的管理和控制信息的数据结构称为进程控制块(PCB Process Control Block),它是进程管理和控制的最重要的数据结构,每一个进程均有一个PCB,在创建进程时,建立PCB,伴随进程运行的全过程,直到进程撤消而撤消。PCB是进程存在的唯一标志。PCB一般包括:
- PID(程序ID、进程句柄):它是唯一的,一个进程都必须对应一个PID。PID一般是整形数字。
- 特征信息:一般分系统进程、用户进程、或者内核进程等
- 进程状态:运行、就绪、阻塞,表示进程现的运行情况
- 优先级:表示获得CPU控制权的优先级大小
- 资源需求、分配控制信息等
2.2 进程的状态
- Running(R),运行或将要运行
- Interruptible(S),被阻断而等待一个事件,可能会被一个信号激活
- Uninterruptible(D),被阻断而等待一个事件,不会被信号激活
- Stopped(T),由于任务的控制或者外部的追踪而被终止,比如:strace
- Zombie(Z),僵死,但是它的父进程尚未调用wait函数
- Dead(X)
2.3 进程的调度
- 进程调度的主要入口函数是 schedule()。它定义在文件 kernel/sched.c 中。
- 多个调度算法
- 进程调度的时机
- 进程上下文切换
3. 中断与系统调用
中断是指 CPU 对系统发生的某个事件做出的一种反应,CPU 暂停正在执行的程序,保存现场后自动去执行相应的处理程序,处理完该事件后再返回中断处继续执行原来的程序。
中断分外部中断(硬件中断) 和 内部中断(软件中断),内部中断又称为异常(Exception),异常又分为故障(fault)和陷阱(trap)。系统调用就是利用陷阱(trap)这种软件中断方式主动从用户态进入内核态的。
- 外部中断指来自CPU执行指令以外的事件的发生,如外部设备(外设是硬件,所以也叫硬件中断)发出的I/O结束中断,表示设备输入/输出处理已经完成,希望处理机能够向设备发下一个输入 / 输出请求,同时让完成输入/输出后的程序继续运行。时钟中断,表示一个固定的时间片已到,让处理机处理计时、启动定时运行的任务等。
- 内部中断是由CPU内部事件所引起的中断,例如进程在运算中发生了上溢或者下溢,有如程序出错,如非法指令,地址越界等。
4. 物理内存和虚拟内存
物理内存就是系统硬件提供的内存大小,是真正的内存。虚拟内存是为了满足物理内存的不足而提出的策略,它是利用磁盘空间虚拟出的一块逻辑内存。用作虚拟内存的磁盘空间被称为交换空间(又称 swap 空间)。
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
作为物理内存的扩展,Linux 会在物理内存不足时,使用交换分区的虚拟内存,更详细地说,就是内核会将暂时不用的内存块信息写到交换空间,这样一来,物理内存得到了释放,这块内存就可以用于其他目的,当需要用到原始的内容时,这些信息会被重新从交换空间读入物理内存。
虚拟存储器提供了三个重要的能力:
- 它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效地使用了主存
- 它为每个进程提供了一致的地址空间,从而简化了存储器管理
- 它保护了每个进程的地址空间不被其他进程破坏
二、Shell
命令解释器(Shell)是系统的用户界面,其提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行。
不仅如此,Shell 有自己的编程语言用于对命令的编辑,它允许用户编写由 Shell 命令组成的程序。Shell 编程语言具有普通编程语言的很多特点,如它也有循环结构和分支控制结构等,用这种编程语言编写的 Shell 程序与其他应用程序具有同样的效果。
Shell 有两种执行指令的方式,第一种方式是用户事先编写一个 sh 脚本文件,内含 Shell 脚本,而后使用 Shell 程序执行该脚本,这种方式,我们习惯称为 Shell 编程。
第二种方式,则是用户直接在 Shell 界面上执行 Shell 命令,由于 Shell 界面的关系,大家都习惯一行行的书写,很少写出成套的程序来一起执行,所以也称命令行。
总结:Shell 可以说只是为用户与机器之间搭建成的一个桥梁,让我们能够通过 Shell 来对计算机进行操作和交互,从而达到让计算机为我们服务的目的。
三、文件系统
文件系统(File System)是文件存放在磁盘等存储设备上的组织方法,其主要体现在对文件和目录的组织上。
目录提供了管理文件的一个方便而有效的途径,用户可以从一个目录切换到另一个目录,而且可以设置目录和文件的权限,设置文件的共享程度。
Linux 文件系统利用树形结构管理文件。每个节点有多个指针,指向下一层节点或者文件的磁盘存储位置。文件节点还附有文件的操作信息(metadata),包括修改时间,访问权限等。
用户的访问权限通过能力表(Capability List)和访问控制表(Access Control List)实现。前者从文件角度出发,标注了每个用户可以对该文件进行何种操作。后者从用户角度出发,标注了某用户可以以什么权限操作哪些文件。
Linux 的文件权限分为读、写和执行,用户组分为文件拥有者,组和所有用户。可以通过命令对三组用户分别设置权限。
应用举例
一 Linux下的COW
1. 简介
写入时复制(Copy On Write,简称COW)核心思想是,如果有多个调用者同时请求相同资源,他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给该调用者,而其他调用者所见到的最初的资源仍然保持不变。
我们知道,fork() 会产生一个和父进程完全相同的子进程(除了pid)。按传统的做法,会直接将父进程的数据拷贝到子进程中,拷贝完之后,父进程和子进程之间的数据段和堆栈是相互独立的。
但是,以我们的使用经验来说:往往子进程都会执行 exec() 来做自己想要实现的功能。
所以,如果按照上面的做法的话,创建子进程时复制过去的数据是没用的(因为子进程执行 exec(),原有的数据会被清空)。既然很多时候复制给子进程的数据是无效的,于是就有了 Copy On Write 这项技术了,原理也很简单:
- fork 创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程,这样创建子进程的速度就很快了。
- 并且如果在 fork 函数返回之后,子进程第一时间 exec() 一个新的可执行映像,那么也不会浪费时间和内存空间了。
2. Copy On Write技术实现原理:
fork()之后,kernel 把父进程中所有的内存页的权限都设为 read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU 硬件检测到内存页是 read-only 的,于是触发页异常中断(page-fault),陷入 kernel 的一个中断例程。中断例程中,kernel 就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
3. 文件系统的COW
COW 在对数据进行修改的时候,不会直接在原来的数据位置上进行操作,而是重新找个位置修改,这样的好处是一旦系统突然断电,重启之后不需要做 fsck。好处就是能保证数据的完整性,掉电的话容易恢复。
比如说:要修改数据块 A 的内容,先把 A 读出来,写到 B 块里面去。如果这时候断电了,原来 A 的内容还在。
4. 总结
- Linux 通过 Copy On Write 技术极大地减少了
fork()的开销。 - 文件系统通过 Copy On Write 技术一定程度上保证数据的完整性。
二、mmap的应用
1. 简介
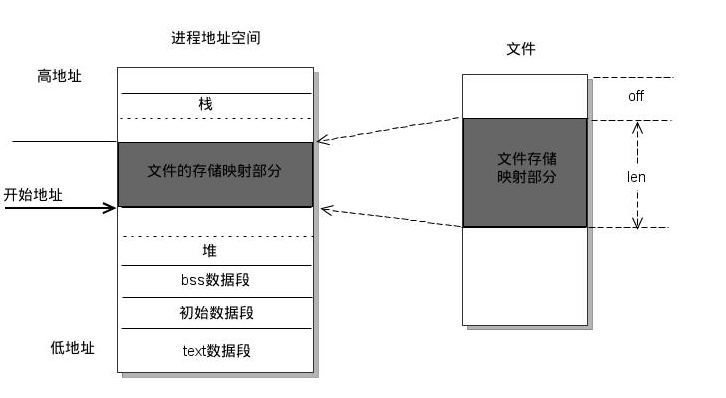
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read, write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
2. mmap 在 read 和 write 时会发生什么
2.1 read 系统调用
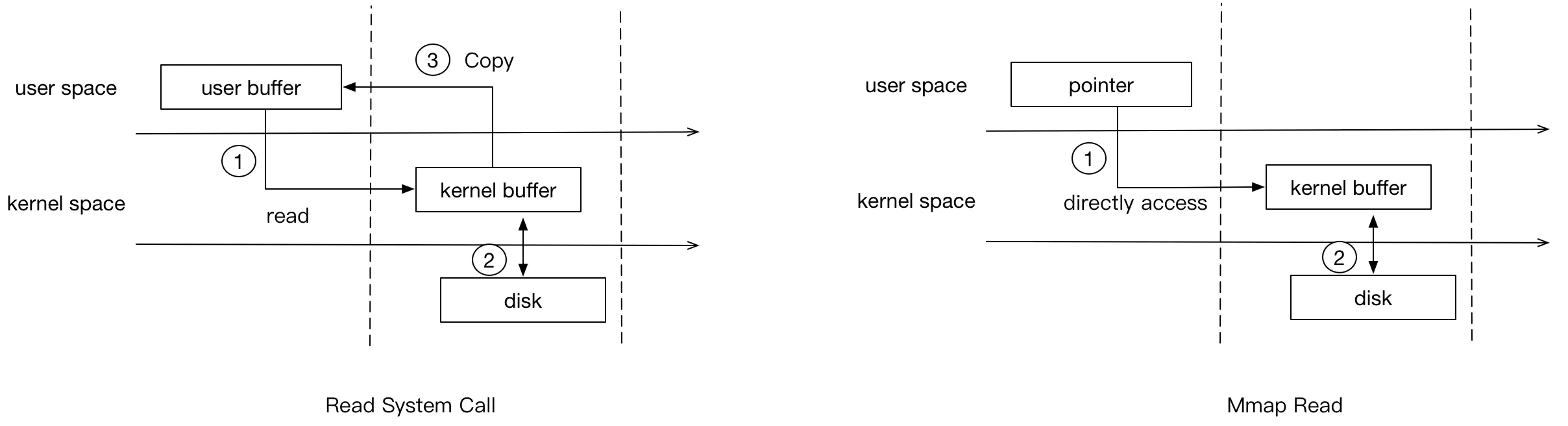
从图中可以看出,mmap 要比普通的read 系统调用少了一次 copy 的过程。因为 read 调用,进程是无法直接访问 kernel space 的,所以在 read 系统调用返回前,内核需要将数据从内核复制到进程指定的 buffer。但 mmap 之后,进程可以直接访问 mmap 的数据(page cache)。
2.2 write 系统调用
- 进程(用户态)将需要写入的数据直接 copy 到对应的 mmap 地址(内存copy)
- 若mmap地址未对应物理内存,则产生缺页异常,由内核处理
- 若已对应,则直接copy到对应的物理内存
- 由操作系统调用,将脏页回写到磁盘(通常是异步的)
因为物理内存是有限的,mmap在写入数据超过物理内存时,操作系统会进行页置换,根据淘汰算法,将需要淘汰的页置换成所需的新页,所以mmap对应的内存是可以被淘汰的(若内存页是"脏"的,则操作系统会先将数据回写磁盘再淘汰)。这样,就算mmap的数据远大于物理内存,操作系统也能很好地处理,不会产生功能上的问题。
3. 总结
- mmap 对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代 I/O 读写,提高了文件读取效率。
- mmap 实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
应用程序性能分析
此例子中我们主要关心的是 cache miss 事件,那么我们只需要统计程序 cache miss 的次数即可。使用perf 来检测程序执行期间由此造成的 cache miss 的命令是 perf stat -e cache-misses ./filename ,另外,检测 cache miss 事件需要取消内核指针的禁用(/proc/sys/kernel/kptr_restrict 设置为 0)。
有两个数组 A 和 B,访问的时候会先访问 A 再访问 B。这样 A[i] 和 B[i] 就距离很远,如果 A、B 是两个长度很大的数组,那么可能 A[i] 和 B[i] 无法同时存在 cache 之中。为了增加程序访问的局部性,需要将 A[i] 和 B[i] 尽量存放在一起。为此,我们可以定义一个结构体,包含 A 和 B 的元素各一个。这样的两个程序对比如下:
// test.c
#include <stdio.h>
#define NUM 393216
void add(float *a, float *b, int num){
int i=0;
for(i=0; i<num; i++) {
*a = *a + *b;
a++;
b++;
}
}
int main()
{
float a[NUM],b[NUM];
for(int i = 0; i < 1000; i++)
add(a, b, NUM);
return 0;
}
// test2.c
#include <stdio.h>
#define NUM 39216
typedef struct {
float a;
float b;
}Array;
void add(Array *myarray, int num)
{
for(int i = 0; i < num; i++) {
myarray->a = myarray->a + myarray->b;
myarray++;
}
}
int main()
{
Array myarray[NUM];
for(int i = 0; i < 1000; i++)
add(myarray, NUM);
return 0;
}
使用 Perf 查看 test.c 和 test2.c 的 cache miss,结果如下:
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf stat -e cache-misses ./test
Performance counter stats for './test':
180,284 cache-misses
0.604338708 seconds time elapsed
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf stat -e cache-misses ./test2
Performance counter stats for './test2':
21,307 cache-misses
0.063258666 seconds time elapsed
可以看到,后者的 cache miss 数量相对前者有很大的下降,耗费的时间大概是前者的十分之一左右。
进一步,可以查看触发 cache miss 的函数:
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf record -e cache-misses ./test
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.021 MB perf.data (106 samples) ]
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf report
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 106 of event 'cache-misses'
# Event count (approx.): 209792
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ................................
#
66.13% test test [.] add
17.91% test test [.] _fini
5.26% test [kernel.kallsyms] [k] clear_page_erms
3.19% test [kernel.kallsyms] [k] get_page_from_freelist
1.44% test [kernel.kallsyms] [k] mem_cgroup_throttle_swaprate
1.42% test [kernel.kallsyms] [k] mem_cgroup_try_charge
1.15% test [kernel.kallsyms] [k] _raw_spin_lock
0.75% test [kernel.kallsyms] [k] try_charge
0.73% test [kernel.kallsyms] [k] wp_page_copy
0.71% test [kernel.kallsyms] [k] kthread_blkcg
0.60% test [kernel.kallsyms] [k] second_overflow
0.48% test libc-2.27.so [.] __run_exit_handlers
0.15% test [kernel.kallsyms] [k] invoke_rcu_core
0.04% test [kernel.kallsyms] [k] attach_entity_load_avg
0.01% test [kernel.kallsyms] [k] idle_cpu
0.01% test test [.] main
0.01% test libc-2.27.so [.] exit
0.00% perf [kernel.kallsyms] [k] perf_event_addr_filters_exec
从 perf 输出的结果可以看出,test.c 程序 cache miss 主要是由 add 触发的。
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf record -e cache-misses ./test2
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.017 MB perf.data (13 samples) ]
root@kdjlyy:/home/kdjlyy/courses/linuxOS/lab7# perf report
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 13 of event 'cache-misses'
# Event count (approx.): 21715
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ................................
#
19.09% test2 [kernel.kallsyms] [k] kernel_init_free_pages
19.06% test2 [kernel.kallsyms] [k] clear_page_erms
16.89% test2 ld-2.27.so [.] _dl_relocate_object
14.54% test2 [kernel.kallsyms] [k] vmacache_find
11.75% test2 [kernel.kallsyms] [k] page_fault
10.88% test2 [kernel.kallsyms] [k] kmem_cache_free
5.38% test2 [kernel.kallsyms] [k] vma_interval_tree_insert
1.96% test2 [kernel.kallsyms] [k] __vm_munmap
0.40% test2 [kernel.kallsyms] [k] __update_load_avg_cfs_rq
0.05% test2 [kernel.kallsyms] [k] find_next_bit
0.00% perf [kernel.kallsyms] [k] perf_event_addr_filters_exec
从 perf 输出的结果可以看出,test2.c 程序 cache miss 主要是由内核函数触发的。
总结
实际情况下,一个程序的 cache 失效比例往往并不像我们从理论上预测的那么简单。影响 cache 失效比例的因素主要有:数组大小,cache 映射策略,二级 cache 大小,Victim Cache 等,同时由于 cache 的不同写回策略,我们也很难从理论上预估一个程序由于 cache miss 而导致的时间耗费。真正在进行程序设计的时候,我们在进行理论上的分析之后,只有使用perf等性能调优工具,才能更真实地观察到程序对 cache 的利用情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号