
深入理解系统调用
一、实验要求
- 找一个系统调用,系统调用号为学号最后2位相同的系统调用
- 通过汇编指令触发该系统调用
- 通过gdb跟踪该系统调用的内核处理过程
- 重点阅读分析系统调用入口的保存现场、恢复现场和系统调用返回,以及重点关注系统调用过程中内核堆栈状态的变化
二、理论知识
2.1 Linux整体架构图
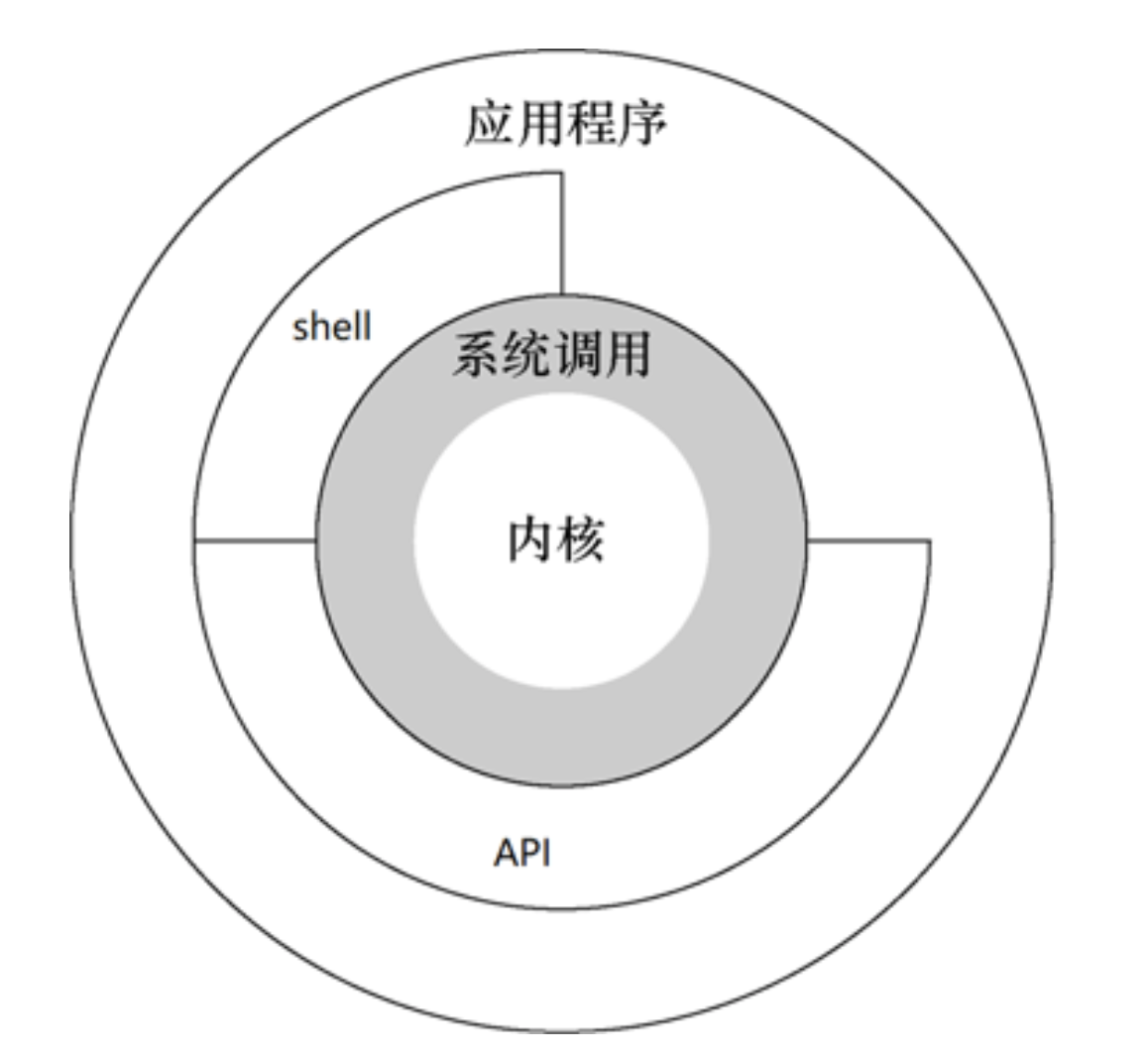
2.2 系统调用
系统调用时操作系统的最小功能单位。根据不同的应用场景,不同的Linux发行版本提供的系统调用数量也不尽相同,大致在240-350之间。这些系统调用组成了用户态跟内核态交互的基本接口,例如:用户态想要申请一块20K大小的动态内存,就需要brk系统调用,将数据段指针向下偏移,如果用户态多处申请20K动态内存,同时又释放呢?这个内存的管理就变得非常的复杂。
2.3 库函数
open(),write(),read()等等。库函数根据不同的标准也有不同的版本,例如:glibc库,posix库等。2.4 用户态与内核态
宏观上 Linux 操作系统的体系架构分为用户态和内核态。计算机的硬件资源是有限的,为了减少有限资源的访问和使用冲突,CPU和操作系统必须提供一些机制对用户程序进行权限划分。现代的 CPU一般都有几种不同的指令执行级别,就是什么样的程 序执行什么样的指令是有权限的。在高的执行级别下,代码可以执行特权指令,访问任意内存,这时 CPU 的执行级别对应的就是内核态,所有的指令包括特权指令都可以执行。相应的,在用户态(低级别指令),代码能够掌控的范围会受到限制。为什么 会出现这种情况呢?其实很容易理解,如果没有权限级别的划分,系统中程序员编写的所有代码都可以使用特权指令,系统就很容易出现崩溃的情况。因为不是每个程序员写的代码都那么健壮,或者说会非法访问其他进程甚至内核的资源,就会产生信息安全问题,这也是操作系统发展的过程中保证系统稳定性和安全性的一种机制。让普通程序员写的用户态的代码很难导致整个系统的崩溃,而操作系统内核的代码是由更专业的程序员写的,有规范的测试,相对就会更稳定、健壮。
2.5 中断
中断分外部中断(硬件中断)和内部中断(软件中断),内部中断又称为异常(Exception),异常又分为故障(fault)和陷阱(trap)。 系统调用就是利用陷阱(trap)这种软件中断方式主动从用户态进入内核态的。
一般来说,从用户态进入内核态是由中断触发的,可能是硬件中断, 在用户态进程执行时,硬件中断信号到来,进入内核态,就会执行这 个中断对应的中断服务例程。也可能是用户态程序执行过程中,调用 了一个系统调用,陷入了内核态,叫作陷阱(trap)(系统调用是特 殊的中断)。
2.6 系统编程接口 API 和系统调用的关系
系统调用的库函数就是我们使用的操作系统提供的 API(应用程序编程接口),API 只是函数定义。系统调用是通过特定的软件中断(陷阱 trap)向内核发出服务请求,int $0x80 和syscall指令的执行就会触发一个系统调用。C库函数内部使用了系统调用的封装例程, 其主要目的是发布系统调用,使程序员在写代码时不需要用汇编指令和寄存器传递参数来 触发系统调用。一般每个系统调用对应一个系统调用的封装例程,函数库再用这些封装例 程定义出给程序员调用的 API,这样把系统调用最终封装成方便程序员使用的C库函数。
C库函数API可能直接提供一些用户态的服务,并不需要通过系统调用 与内核打交道,比如一些数学函数,但涉及与内核空间进行交互的C 库函数API 内部会封装系统调用。一个 API 可能只对应一个系统调用,也可能内部由多个系统调用实现,一个系统调用也可能被多个 API 调用。不涉及与内核进行交互的 API 内部不会封装系统调用,比 如用于求绝对值的数学函数 abs()。对于返回值,大部分系统调用的封装例程返回一个整数,其值的含义依赖于对应的系统调用,返回值-1 在多数情况下表示内核不能满足进程的请求,C库函数中进一步定义的 errno 变量包含特定的出错码。

2.7 Linux系统调用
当用户态进程调用一个系统调用时,CPU切换到内核态并开始执行 system_call(entry_INT80_32或entry_SYSCALL_64)汇编代码,其中根据系统调用号调用对应的内核处理函数。具体来说,在Linux中通 过执行int $0x80或syscall指令来触发系统调用的执行,其中这条int $0x80汇编指令是产生中断向量为128的编程异常(trap)。另外Intel 处理器中还引入了sysenter指令(快速系统调用),因为Intel专用 AMD并不支持,在此不再详述。我们只关注int指令和syscall指令触发 的系统调用,进入内核后,开始执行对应的中断服务程序 entry_INT80_32或entry_SYSCALL_64。
三、搭建实验环境
3.1 安装开发工具
1 sudo apt install build-essential 2 sudo apt install qemu # install QEMU 3 sudo apt install libncurses5-dev bison flex libssl-dev libelf-dev
3.2 下载内核源代码
1 sudo apt install axel 2 axel -n 20 https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.4.34.tar.xz 3 xz -d linux-5.4.34.tar.xz 4 tar -xvf linux-5.4.34.tar 5 cd linux-5.4.34
3.3 配置内核选项
1 make defconfig # Default configuration is based on 'x86_64_defconfig' 2 make menuconfig 3 # 打开debug相关选项 4 Kernel hacking ---> 5 Compile-time checks and compiler options ---> 6 [*] Compile the kernel with debug info 7 [*] Provide GDB scripts for kernel debugging 8 [*] Kernel debugging 9 # 关闭KASLR,否则会导致打断点失败 10 Processor type and features ----> 11 [] Randomize the address of the kernel image (KASLR)
3.4 编译和运行内核
1 make -j$(nproc) # nproc gives the number of CPU cores/threads available 2 # 测试⼀下内核能不能正常加载运⾏,因为没有⽂件系统终会kernel panic 3 qemu-system-x86_64 -kernel arch/x86/boot/bzImage # 此时应该不能正常运行
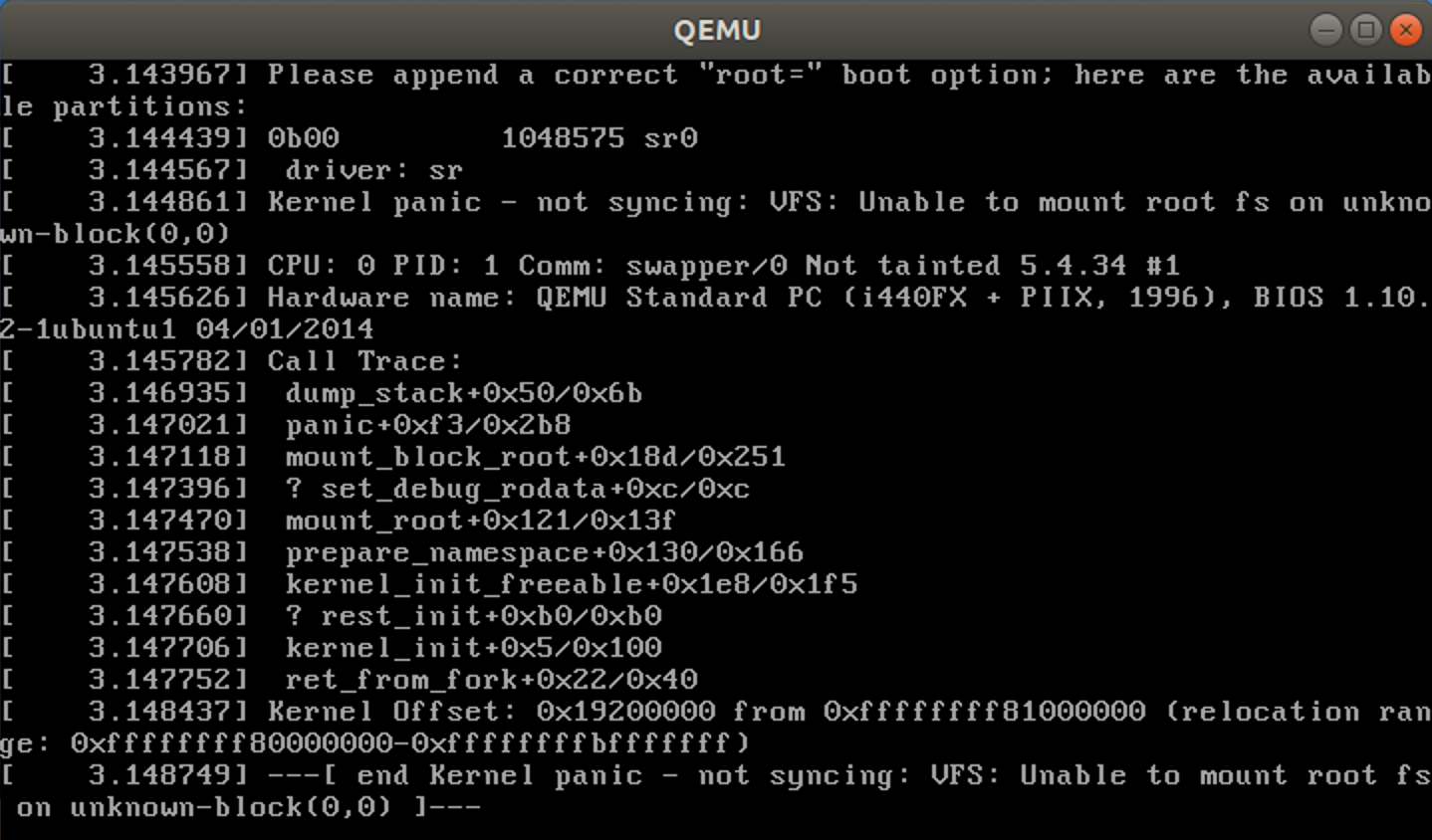
由于没有⽂件系统最终会kernel panic,这属于正常现象
3.5 制作根文件系统
1 首先从https://www.busybox.net下载 busybox源代码解压,解压完成后,跟内核一样先配置编译,并安装。 2 axel -n 20 https://busybox.net/downloads/busybox-1.31.1.tar.bz2 3 tar -jxvf busybox-1.31.1.tar.bz2 4 cd busybox-1.31.1
1 make menuconfig #若出现打不开menuconfig,重启虚拟机即可 2 #记得要编译成静态链接,不⽤动态链接库。 3 Settings ---> 4 [*] Build static binary (no shared libs) 5 #然后编译安装,默认会安装到源码⽬录下的 _install ⽬录中。 6 make -j$(nproc) && make install
制作内存根文件系统镜像
1 mkdir rootfs 2 cd rootfs 3 cp ../busybox-1.31.1/_install/* ./ -rf 4 mkdir dev proc sys home 5 sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/
准备init脚本文件放在根文件系统跟目录下(rootfs/init),添加如下内容到init文件。
1 #!/bin/sh 2 mount -t proc none /proc 3 mount -t sysfs none /sys 4 echo "Wellcome MengningOS!" 5 echo "--------------------" 6 cd home 7 /bin/sh
给init脚本添加可执⾏权限
1 chmod +x init
1 #打包成内存根⽂件系统镜像 2 find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../ rootfs.cpio.gz 3 #测试挂载根⽂件系统,看内核启动完成后是否执⾏init脚本 4 qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz

四、系统调用
我的学号后两位为03,查找linux-5.4.34/arch/x86/entry/syscalls/syscall_32.tb,03号为read系统调用。

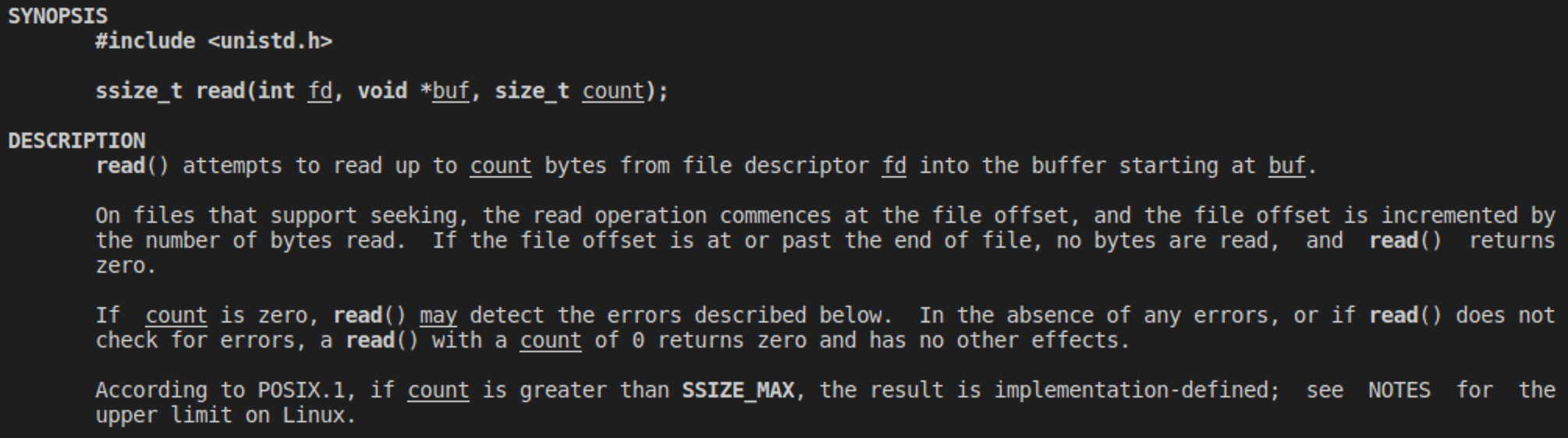
通过man read命令查看read()函数
编写read.c函数
1 #include <unistd.h> 2 #include <stdlib.h> 3 #include <stdio.h> 4 5 int main(void) 6 { 7 char buf[10]; 8 int n = read(STDIN_FILENO, buf, 10); 9 printf("%d: %s\n", n, buf); 10 return 0; 11 }
编译运行

使用汇编指令触发系统调用,vi read_asm.c
1 #include <unistd.h> 2 #include <stdlib.h> 3 #include <stdio.h> 4 5 #define SYS_READ 3 6 7 int main() 8 { 9 char buff[10]; 10 ssize_t charsread; 11 asm volatile("int $0x80" 12 : "=a" (charsread) 13 : "0" (SYS_READ), "b" (STDIN_FILENO), "c" (buff), "d" (sizeof(buff)) 14 : "memory", "cc"); 15 16 printf("%d: %s", (int)charsread, buff); 17 18 return 0; 19 }
编译运行

分析:read系统调用主要作用是,读取输入(文件内容)到buf,返回内容结束位置
五、gdb跟踪read系统调用的内核处理过程
1 find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
1 qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
1 #开启新的terminal 2 3 cd linux-5.4.34 4 gdb vmlinux 5 target remote:1234
1 #设置断点 2 b __ia32_sys_read

(gdb) target remote:1234 Remote debugging using :1234 default_idle () at arch/x86/kernel/process.c:581 581 trace_cpu_idle_rcuidle(PWR_EVENT_EXIT, smp_processor_id()); (gdb) b __ia32_sys_read Breakpoint 1 at 0xffffffff811d0b50: file fs/read_write.c, line 597. (gdb) bt #0 default_idle () at arch/x86/kernel/process.c:581 #1 0xffffffff81095ebe in cpuidle_idle_call () at kernel/sched/idle.c:154 #2 do_idle () at kernel/sched/idle.c:263 #3 0xffffffff810960f4 in cpu_startup_entry (state=CPUHP_ONLINE) at kernel/sched/idle.c:355 #4 0xffffffff81a7eec5 in rest_init () at init/main.c:451 #5 0xffffffff829aeab7 in arch_call_rest_init () at init/main.c:573 #6 0xffffffff829aef74 in start_kernel () at init/main.c:785 #7 0xffffffff810000d4 in secondary_startup_64 () at arch/x86/kernel/head_64.S:241 #8 0x0000000000000000 in ?? () (gdb) l 576 */ 577 void __cpuidle default_idle(void) 578 { 579 trace_cpu_idle_rcuidle(1, smp_processor_id()); 580 safe_halt(); 581 trace_cpu_idle_rcuidle(PWR_EVENT_EXIT, smp_processor_id()); 582 } 583 #if defined(CONFIG_APM_MODULE) || defined(CONFIG_HALTPOLL_CPUIDLE_MODULE) 584 EXPORT_SYMBOL(default_idle); 585 #endif (gdb) l 586 587 #ifdef CONFIG_XEN 588 bool xen_set_default_idle(void) 589 { 590 bool ret = !!x86_idle; 591 592 x86_idle = default_idle; 593 594 return ret; 595 } (gdb) l 596 #endif 597 598 void stop_this_cpu(void *dummy) 599 { 600 local_irq_disable(); 601 /* 602 * Remove this CPU: 603 */ 604 set_cpu_online(smp_processor_id(), false); 605 disable_local_APIC(); (gdb) l 606 mcheck_cpu_clear(this_cpu_ptr(&cpu_info)); 607 608 /* 609 * Use wbinvd on processors that support SME. This provides support 610 * for performing a successful kexec when going from SME inactive 611 * to SME active (or vice-versa). The cache must be cleared so that 612 * if there are entries with the same physical address, both with and 613 * without the encryption bit, they don't race each other when flushed 614 * and potentially end up with the wrong entry being committed to 615 * memory. (gdb) l 616 */ 617 if (boot_cpu_has(X86_FEATURE_SME)) 618 native_wbinvd(); 619 for (;;) { 620 /* 621 * Use native_halt() so that memory contents don't change 622 * (stack usage and variables) after possibly issuing the 623 * native_wbinvd() above. 624 */ 625 native_halt(); (gdb) l 626 } 627 } 628 629 /* 630 * AMD Erratum 400 aware idle routine. We handle it the same way as C3 power 631 * states (local apic timer and TSC stop). 632 */ 633 static void amd_e400_idle(void) 634 { 635 /* (gdb) l 636 * We cannot use static_cpu_has_bug() here because X86_BUG_AMD_APIC_C1E 637 * gets set after static_cpu_has() places have been converted via 638 * alternatives. 639 */ 640 if (!boot_cpu_has_bug(X86_BUG_AMD_APIC_C1E)) { 641 default_idle(); 642 return; 643 } 644 645 tick_broadcast_enter(); (gdb) l 646 647 default_idle(); 648 649 /* 650 * The switch back from broadcast mode needs to be called with 651 * interrupts disabled. 652 */ 653 local_irq_disable(); 654 tick_broadcast_exit(); 655 local_irq_enable(); (gdb) l 656 } 657 658 /* 659 * Intel Core2 and older machines prefer MWAIT over HALT for C1. 660 * We can't rely on cpuidle installing MWAIT, because it will not load 661 * on systems that support only C1 -- so the boot default must be MWAIT. 662 * 663 * Some AMD machines are the opposite, they depend on using HALT. 664 * 665 * So for default C1, which is used during boot until cpuidle loads, (gdb) l 666 * use MWAIT-C1 on Intel HW that has it, else use HALT. 667 */ 668 static int prefer_mwait_c1_over_halt(const struct cpuinfo_x86 *c) 669 { 670 if (c->x86_vendor != X86_VENDOR_INTEL) 671 return 0; 672 673 if (!cpu_has(c, X86_FEATURE_MWAIT) || boot_cpu_has_bug(X86_BUG_MONITOR)) 674 return 0; 675 (gdb) l 676 return 1; 677 } 678 679 /* 680 * MONITOR/MWAIT with no hints, used for default C1 state. This invokes MWAIT 681 * with interrupts enabled and no flags, which is backwards compatible with the 682 * original MWAIT implementation. 683 */ 684 static __cpuidle void mwait_idle(void) 685 { (gdb) l 686 if (!current_set_polling_and_test()) { 687 trace_cpu_idle_rcuidle(1, smp_processor_id()); 688 if (this_cpu_has(X86_BUG_CLFLUSH_MONITOR)) { 689 mb(); /* quirk */ 690 clflush((void *)¤t_thread_info()->flags); 691 mb(); /* quirk */ 692 } 693 694 __monitor((void *)¤t_thread_info()->flags, 0, 0); 695 if (!need_resched()) (gdb) l 696 __sti_mwait(0, 0); 697 else 698 local_irq_enable(); 699 trace_cpu_idle_rcuidle(PWR_EVENT_EXIT, smp_processor_id()); 700 } else { 701 local_irq_enable(); 702 } 703 __current_clr_polling(); 704 } 705 (gdb) l 706 void select_idle_routine(const struct cpuinfo_x86 *c) 707 { 708 #ifdef CONFIG_SMP 709 if (boot_option_idle_override == IDLE_POLL && smp_num_siblings > 1) 710 pr_warn_once("WARNING: polling idle and HT enabled, performance may degrade\n"); 711 #endif 712 if (x86_idle || boot_option_idle_override == IDLE_POLL) 713 return; 714 715 if (boot_cpu_has_bug(X86_BUG_AMD_E400)) { (gdb) l 716 pr_info("using AMD E400 aware idle routine\n"); 717 x86_idle = amd_e400_idle; 718 } else if (prefer_mwait_c1_over_halt(c)) { 719 pr_info("using mwait in idle threads\n"); 720 x86_idle = mwait_idle; 721 } else 722 x86_idle = default_idle; 723 } 724 725 void amd_e400_c1e_apic_setup(void) (gdb) l 726 { 727 if (boot_cpu_has_bug(X86_BUG_AMD_APIC_C1E)) { 728 pr_info("Switch to broadcast mode on CPU%d\n", smp_processor_id()); 729 local_irq_disable(); 730 tick_broadcast_force(); 731 local_irq_enable(); 732 } 733 } 734 735 void __init arch_post_acpi_subsys_init(void) (gdb) l 736 { 737 u32 lo, hi; 738 739 if (!boot_cpu_has_bug(X86_BUG_AMD_E400)) 740 return; 741 742 /* 743 * AMD E400 detection needs to happen after ACPI has been enabled. If 744 * the machine is affected K8_INTP_C1E_ACTIVE_MASK bits are set in 745 * MSR_K8_INT_PENDING_MSG. (gdb) l 746 */ 747 rdmsr(MSR_K8_INT_PENDING_MSG, lo, hi); 748 if (!(lo & K8_INTP_C1E_ACTIVE_MASK)) 749 return; 750 751 boot_cpu_set_bug(X86_BUG_AMD_APIC_C1E); 752 753 if (!boot_cpu_has(X86_FEATURE_NONSTOP_TSC)) 754 mark_tsc_unstable("TSC halt in AMD C1E"); 755 pr_info("System has AMD C1E enabled\n"); (gdb) l 756 } 757 758 static int __init idle_setup(char *str) 759 { 760 if (!str) 761 return -EINVAL; 762 763 if (!strcmp(str, "poll")) { 764 pr_info("using polling idle threads\n"); 765 boot_option_idle_override = IDLE_POLL; (gdb) l 766 cpu_idle_poll_ctrl(true); 767 } else if (!strcmp(str, "halt")) { 768 /* 769 * When the boot option of idle=halt is added, halt is 770 * forced to be used for CPU idle. In such case CPU C2/C3 771 * won't be used again. 772 * To continue to load the CPU idle driver, don't touch 773 * the boot_option_idle_override. 774 */ 775 x86_idle = default_idle; (gdb) l 776 boot_option_idle_override = IDLE_HALT; 777 } else if (!strcmp(str, "nomwait")) { 778 /* 779 * If the boot option of "idle=nomwait" is added, 780 * it means that mwait will be disabled for CPU C2/C3 781 * states. In such case it won't touch the variable 782 * of boot_option_idle_override. 783 */ 784 boot_option_idle_override = IDLE_NOMWAIT; 785 } else (gdb) l 786 return -1; 787 788 return 0; 789 } 790 early_param("idle", idle_setup); 791 792 unsigned long arch_align_stack(unsigned long sp) 793 { 794 if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space) 795 sp -= get_random_int() % 8192; (gdb) l 796 return sp & ~0xf; 797 } 798 799 unsigned long arch_randomize_brk(struct mm_struct *mm) 800 { 801 return randomize_page(mm->brk, 0x02000000); 802 } 803 804 /* 805 * Called from fs/proc with a reference on @p to find the function (gdb) l 806 * which called into schedule(). This needs to be done carefully 807 * because the task might wake up and we might look at a stack 808 * changing under us. 809 */ 810 unsigned long get_wchan(struct task_struct *p) 811 { 812 unsigned long start, bottom, top, sp, fp, ip, ret = 0; 813 int count = 0; 814 815 if (p == current || p->state == TASK_RUNNING) (gdb) l 816 return 0; 817 818 if (!try_get_task_stack(p)) 819 return 0; 820 821 start = (unsigned long)task_stack_page(p); 822 if (!start) 823 goto out; 824 825 /* (gdb) l 826 * Layout of the stack page: 827 * 828 * ----------- topmax = start + THREAD_SIZE - sizeof(unsigned long) 829 * PADDING 830 * ----------- top = topmax - TOP_OF_KERNEL_STACK_PADDING 831 * stack 832 * ----------- bottom = start 833 * 834 * The tasks stack pointer points at the location where the 835 * framepointer is stored. The data on the stack is: (gdb) l 836 * ... IP FP ... IP FP 837 * 838 * We need to read FP and IP, so we need to adjust the upper 839 * bound by another unsigned long. 840 */ 841 top = start + THREAD_SIZE - TOP_OF_KERNEL_STACK_PADDING; 842 top -= 2 * sizeof(unsigned long); 843 bottom = start; 844 845 sp = READ_ONCE(p->thread.sp); (gdb) l 846 if (sp < bottom || sp > top) 847 goto out; 848 849 fp = READ_ONCE_NOCHECK(((struct inactive_task_frame *)sp)->bp); 850 do { 851 if (fp < bottom || fp > top) 852 goto out; 853 ip = READ_ONCE_NOCHECK(*(unsigned long *)(fp + sizeof(unsigned long))); 854 if (!in_sched_functions(ip)) { 855 ret = ip; (gdb) l 856 goto out; 857 } 858 fp = READ_ONCE_NOCHECK(*(unsigned long *)fp); 859 } while (count++ < 16 && p->state != TASK_RUNNING); 860 861 out: 862 put_task_stack(p); 863 return ret; 864 } 865 (gdb) l 866 long do_arch_prctl_common(struct task_struct *task, int option, 867 unsigned long cpuid_enabled) 868 { 869 switch (option) { 870 case ARCH_GET_CPUID: 871 return get_cpuid_mode(); 872 case ARCH_SET_CPUID: 873 return set_cpuid_mode(task, cpuid_enabled); 874 } 875 (gdb) l 876 return -EINVAL; 877 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号