
爬虫requests操作与网络常识需知
昨日内容回顾
-
body内常见标签
# 标题标签 <h1></h1> <h2></h2> <h3></h3> <h4></h4> <h5></h5> <h6></h6> # 段落标签 <p></p> #换行和分割线 <br> <hr> -
常见符号
  空格 & &(真的&) > 大于 < 小于 ¥ 羊角符 © ©版权标记 ® ®商标 # 眼熟吧 -
常用标签
a 标签 href 1.可以放网址 2.也可以放id值 target 确认为是否打开新网页跳转 img标签 src 图片的地址 alt 加载失败展示的信息 title 鼠标放置图上会显示的说明信息 width 调整图片的宽度(二者最好别一起调整参数) height 调整图片的高度 div与span标签(都起到了划分区域) div用于布局 spen用来标识写普通文本的区域 -
标签的两大属性
id 唯一标签,类似于身份证 class 类别标签,用于分类 -
列表标签
无序列表(主学这个) 无序列表虽然比较丑,但是可以美容,主要的列表方式 有序标签 标题列表 -
表格标签
<table> <thead> # 表头 <tr> <th><th> <tr> <thead> <tbody> # 表单 <tr> <td><td> <td><td> <td><td> <tr> <tbody> </table> <tr> # 表示一行列表 <th> # 加粗文本 <td> # 普通文本 -
form表单
'''获取用户数据并提交后台的服务器(软件开发架构)''' <body> <form action="https://www.bilibili.com"> <p>普通文本: <input type="text"> </p> <p>密码暗文: <input type="password"> </p> <p>email: <input type="email"> </p> <p>日期: <input type="data"> </p> <p>单选框: <input type="radio" name="gender">学习 <input type="radio" name="gender">努力学习 <input type="radio" name="gender">我的心中只有学习 </p> <p>多选框: <input type="checkbox">英语AB <input type="checkbox">英语四级 <input type="checkbox">英语六级 </p> <p>文件上传: <input type="file"m> </p> <p>提交按钮: <input type="submit"> </p> <p>重置内容: <input type="reset"> </p> <p>一个等待开发的按钮: <input type="button"> </p> <p>下拉选项框: <select> <option value="">选一</option> <option value="">选而</option> <option value="">选三</option> <option value="">选四</option> </select> </p> <p>可以输入一大段内容的文字框: <textarea></textarea> </p> <p>密码暗文:<input type="password"></p> <p>密码暗文:<input type="password"></p> </form> </body> -
爬虫简介
1.什么是互联网 由一台台计算机,路由器,交换机组成的一张大网 2.接入互联网 建立连接 3.上网的本质 访问其他计算机 4.爬虫简介 用代码模仿浏览器去获取信息 ''' 快速高效的获取浏览器上携带的信息(最赚钱的方法都在法律里面写了) '''
今日内容概要
-
爬虫模块之requests模块
requests模块可以模拟浏览器超服务器发送网络请求 最基本的两种求情: get请求 post请求 ..... -
HTTP协议哦
规定了浏览器与服务端之间数据交互的格式及一系列相关的原则 -
reques模块方法大全
-
cookie与session
今日内容详细
requests模块
'''
1.使用浏览器访问网站
1.发送请求
2.服务端接收请求
3.服务端返回响应
4.浏览器美化页面给你看
2.使用爬虫代码模拟浏览器访问网站
1.发送请求
2.服务端接收请求
3.服务端返回响应
4.爬虫接收服务器返回的响应通过代码筛选出需要的数据并保存到库中
************
基于网络传输数据,都是二进制
在python中也可以是bytes类型
************
'''
# 下载
pip3 install requests
# 导入
import requests
# 使用
requests.get(url)
requests.post(url)
'''
url
统一资源定位符(就是网址)
网络上的资源很多,如何明确我们的目标呢,使用url明确目标
'''
HTTP协议
规定了浏览器与服务端之间数据交互的各项原则
如果你在开发网站的时候不遵循HTTP协议,浏览器将无法正常的访问到你的网站(大家不带你玩,当然你可以使用钞能力自己建站建规则)
1.四个特性(此处划重点)
1.给予TCP,IP协议作用于应用层之上的协议(忘了去看预科)
2.给予请求响应
给予HTTP交互数据的服务器不会主动发送信息给你
你先主动请求它才会响应你(妖艳贱货)
3.无状态
不保存用户的状态(游客模式)
4.无/短连接
交互后连接断开(你不是她唯一,阿哲)
2.数据格式
请求数据格式
请求首行: 请求方法,协议版本,告知以下内容
# 请求头: 包含了一大堆k:v键值对,用于说明请求方身份信息,验证信息等
(此处换行符)
请求体: 存放着账号密码敏感信息(get请求数据不在这里)
响应数据格式
响应首行: 请求方法,协议版本,告知以下内容
响应头: 包含了一大堆k:v键值对
(此处换行符)
响应体: 浏览器展示出来的数据
3.响应状态码
暗号啥的,代替文字说明你与服务端交互的状态说明
1xx 服务端已经接受到信息正在进行处理,可以继续提交或等待
2xx 请求成功,服务端并返回了相应的响应
3xx 重定向,就是界面跳转,会员才能继续让你登录啥的
4xx 403你没有访问权限,404访问的资源不存在
5xx 服务器炸了昂
'''
响应状态码很多公司有自己定制的独有状态码
看看b站的=-=
'''
防爬措施
网站防止你白嫖,当然你肯定想继续白嫖
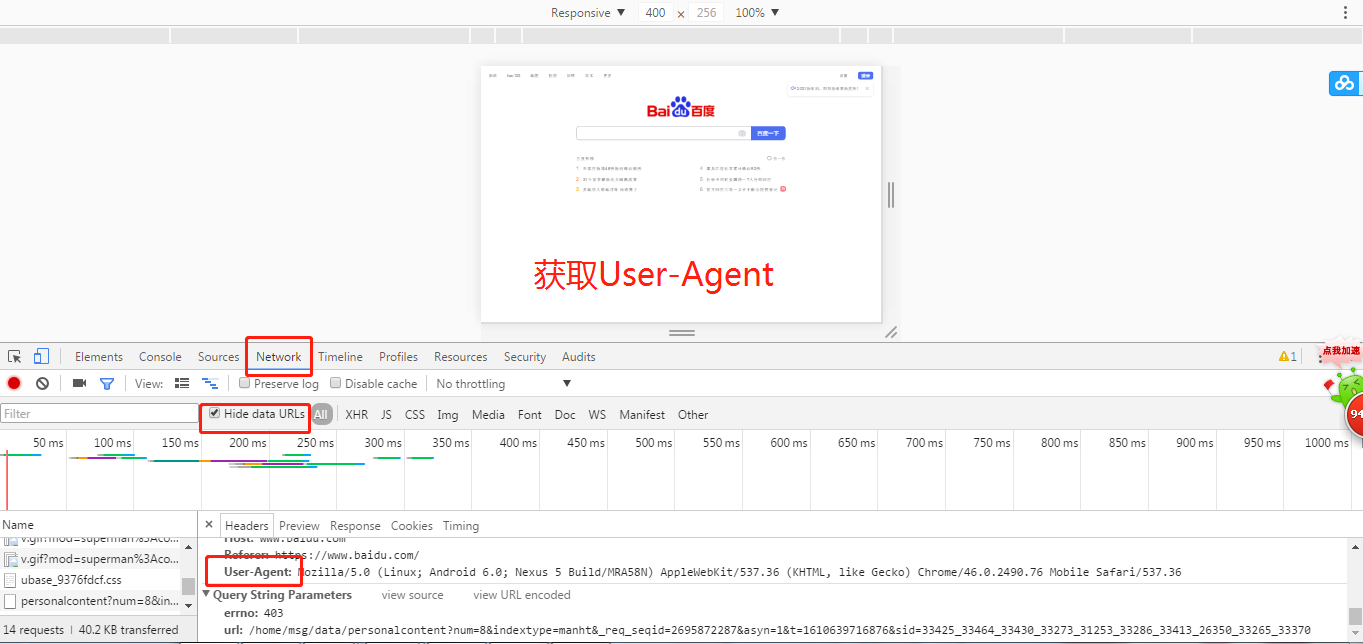
1.校验你是否是一个浏览器
通过查看请求头是否有一个标识你是一个浏览器的K:V键值对
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36
破解措施
就是在我们的请求头中带上上述的键值对即可
requests.get(url,headers={k1:v1,k2:v2...})
requests更多操作
import requests
# 网站验证是否是浏览器时,携带请求头数据(小破站没有可以直接搞)
res=requests.get(
'https://www.bilibili.com/',
headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36"}
)
print(res)# 200
import requests
# 在请求头中直接加入参数
res=requests.get(
'https://search.bilibili.com/all',
params={
"keyword":"小黄图"
},
headers={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36"}
)
print(res) # 200
cookie与session
HTTP协议四大特性中有一个特性是无法保存用户状态,但是我们现在很多软件都需要保存用户状态
在开始阶段所有访问网站的用户都属于游客模式
但是基于权限用户与网站都对于身份验证有需求
# cookie与session应运而生
cookie模式是指用户进行登录操作与服务器验证之后,浏览器会保存用户信息,之后每次与服务端交互代替用户登录信息操作,但是用户的敏感信息会存于浏览器中,安全性较低
sesion模式是浏览器与服务端交互后,服务端验证后返回一串随机字符串,浏览器cookie记录该字符串用作身份信息继续与服务端做交互
# 无论是cook模式还是session模式都并非完全完全,在互联网世界中没有绝对的安全
两种模式都基于cookie,浏览器是可以设置拒绝cookie,可以帮好朋友搞一个!!!
作业
1.抄写今日笔记(尤其是HTTP协议和cookie与session)
针对cookie与session需要你们自己用自己的话描述
2.练习requests模块
朝其他网站发送get请求获取资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号