
多表查询与navicat
昨日内容回顾
-
查询关键字之where筛选
分组之前对数据进行整体的筛选 1.支持逻辑运算 and or not 2.模糊查询 查询关键字like %: _: 3.针对null 只能使用 is 不能使用 = -
查询关键字之group by分组
对单个个体按照规律进行分组 1.分组后只能直接获取分组依据,分组字段以外的字段无法直接获取 2.mysql5.6及之前的的版本需要自己设置严格模式才能满足以上条件 3.分组之后配合聚合函数使用 max min sum avg count 聚合函数要在分组后使用 -
查询关键字之having筛选
和where一样都是筛选字段 但是适用于分组之后 -
查询关键字之distinct
去重 1.去重的条件是数据必须完全一致,如果包含了主键条件一定无法满足 -
查询关键字之order by
排序 asc 升序默认) desc 降序 -
limit
分页 1.当表中的数据过于庞大,为避免电脑内存爆炸,对查询结果的条数进行限制 select * from emp limit 5; # 读取5行 select * from emp limit 5,5; # 跳过前五行数据 -
查询关键字之regexp
正则表达式(以后会详解) '^j.*?(n|y)&' -
补充
打破分组后数据无法直接获取 1.group_concat 分组后 2.concat 分组前 3.concat_ws 偷懒 # 4.as 命名 -
多表查询思路
1.子查询 分步操作 # 将一条sql语句的查询结果作为另一条sql语句的条件 2.连表操作 # 将多张表先拼接起来 然后用单表查询解决
今日内容概要
-
多表查询基本操作(先掌握方法)
-
子查询
-
连表操作
-
可视化软件之navicat
无需自己写sql语句,点点点就能解决数据库的各种操作 -
多表查询练习题(有难度)
-
python代码操作mysql
今日内容详细
多表查询基本操作
#建表
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'保洁')
;
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
子查询
# 1.查询部门是技术或者人力资源的人工信息
1.先去部门表查询技术和人力资源部门的id号
2.再去员工表中根据部门id号筛选出对应的员工
直接套娃
'''当一条sql语句需要当做另一条sql语句的条件是,只需要在该sql语句前后加上括号即可'''
连表操作
'''连表其实就是按照两张表中共有的字段连接表'''
select * from emp,dep;
针对多表操作,涉及到字段名称冲突的情况我们在字段前面加上表名划分
inner join 内连接
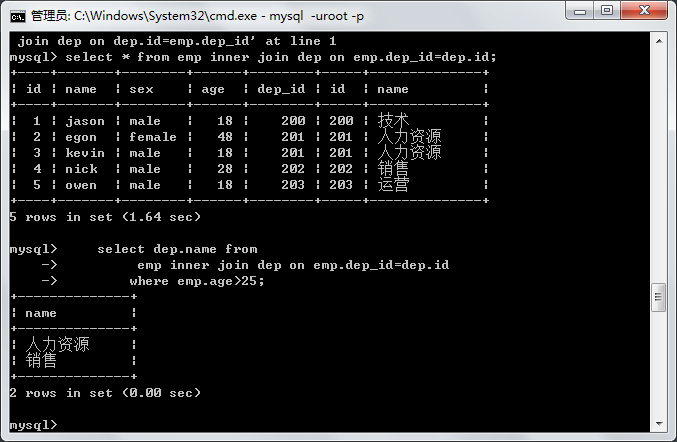
select * from emp inner join dep on emp.dep_id=dep.id;
# 将两张表公共的部分拼接起来,独有的都不要昂!
left join 左连接
select * from emp left join dep on emp.dep_id=dep.id;
# 以左边的表为基准进行拼接,左边全要,右边没对应的就用unll填充
right join 右连接
# 以右边的表为基准进行拼接,右边全要,左边边没对应的就用unll填充
union 全连接
select * from emp inner join dep on emp.dep_id=dep.id
union
select * from emp left join dep on emp.dep_id=dep.id;
# 全都要 没对应的就用unll填充
结论:
涉及到多表查询
可视化软件之navicat
可以充当很多数据库软件客户端
并且通过鼠标点点点就可以完成增删改查操作
# 补充
最规范的情况用大写字母写
# mysql 中的注释
1.--
2.#
# python中的注释
1.#
2.'''三引号'''
python操作mysql
python如果需要操作mysql数据库,需要借助于第三方模块
针对第三方模块要先基于网络下载
pip3 install pymysql
pip3 install pymysql -i 国内的源
mysql默认的服务端ip地址
127.0.0.1
port端口号
port=3306
user='root'
密码
password=''
字符编码
chaeset='utf8'
python操作MySQL
python如果需要操作mysql数据库,需要借助于第三方模块>>>:pymysql
针对第三方模块要先基于网络下载
pip3 install pymysql
pip3 install pymysql -i 国内的源
# MySQL默认的端口号是3306
# 导入模块
import pymysql
# 连接MySQL服务端
conn = pymysql.connect(
# 服务端的ip地址
host='127.0.0.1', # 本机回环地址
# 服务端的port地址
port=3306, # MySQL默认端口号
# 用户名
user='root',
# 密码
password='123456',
# 要操作的数据库名
database='db8',
# 字符编码
charset='utf8'
)
# 产生一个可以执行命令的游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# 构造SQL语句
sql = 'select * from teacher;'
# 利用cursor发送给服务端执行sql语句
cursor.execute(sql)
# 获取执行之后的结果
res = cursor.fetchall()
print(res) # ((1, '张磊老师'), (2, '李平老师'), (3, '刘海燕老师'), (4, '朱云海老师'), (5, '李杰老师'))
"""
针对查询结果默认是元组的形式展示,各个数据对应的字段名称无法查看,会导致识别不准的情况
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
加上参数之后结果就会是列表套字典的形式,这是我们比较喜欢的形式
"""
补充
定个小目标 两倍速!
作业
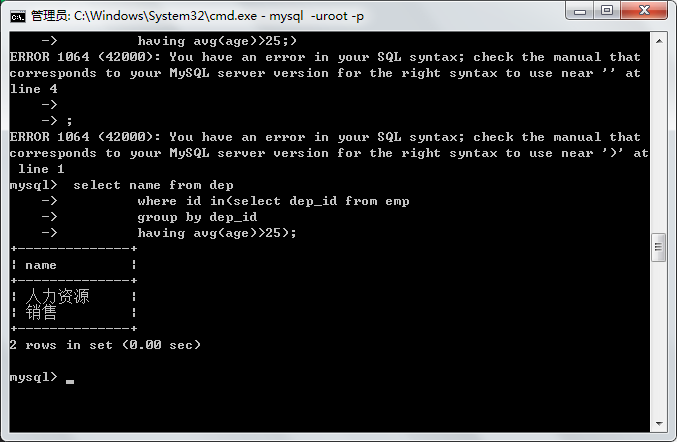
1.查询年龄在25以上的部门名
两种方式
# 子查询
select dep_id from emp
group by dep_id
having avg(age)>25;
select name from dep
where id in(select dep_id from emp
group by dep_id
having avg(age)>25);
# 连表操作
select dep_id,age from emp;
select * from dep;
select dep.name from
emp inner join dep on emp.dep_id=dep.id
where emp.age>25;
2.下载安装好navicat
3.练习navicat使用以及多表数据特征(熟悉sql文件运行完后的五张表)
4.练习pymysql模块


 浙公网安备 33010602011771号
浙公网安备 33010602011771号