Gevent
gevent基础之阻塞,非阻塞
1.gevent中一个很大的改进就是将阻塞IO改为非阻塞IO;
- 阻塞调用是指调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回
- 非阻塞指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回
同步,异步概念
1.同步就是发生调用时,一定等待结果返回,整个调用才结束;
2.异步就是发生调用后,立即返回,不等待结果返回。被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
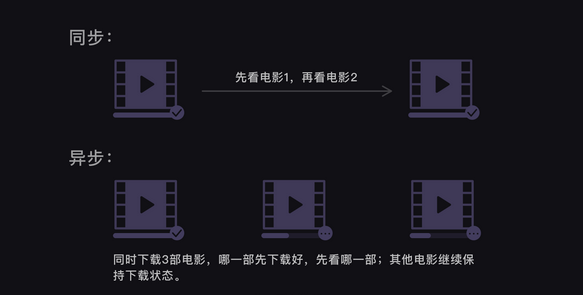
同步异步与阻塞,非阻塞区别
1.阻塞/非阻塞, 它们是程序在等待消息(无所谓同步或者异步)时的状态;
2.同步/异步,是程序获得关注消息通知的机制。
要实现异步的爬虫方式的话,需要用到多协程。在它的帮助下,我们能实现前面提到的“让多个爬虫替我们干活”
它的原理是:一个任务在执行过程中,如果遇到等待,就先去执行其他的任务
当等待结束,再回来继续之前的那个任务。
在计算机的世界,这种任务来回切换得非常快速,看上去就像多个任务在被同时执行一样。
这就好比当你要做一桌饭菜,你可以在等电饭煲蒸饭的时候去炒菜。而不是等饭做好,再去炒菜。你还是那个你,但工作时间就这样被缩短了。多协程能够缩短工作时间的原理,也是如此。
那么问题来了,-–怎么使用多协程?
gevent库
用‘gevent’库,能让我们再python中实现多协程
接下来我会带你了解gevent的用法,和实操一个多协程案例:爬取8个网站(包括百度、新浪、搜狐、腾讯、网易、爱奇艺、天猫、凤凰)。
我们先用之前同步的爬虫方式爬取这8个网站,然后等下再和gevent异步爬取做一个对比。
import requests
from time import time
start = time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'https://www.qq.com/',
'https://www.qq.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
# 把8个网站封装成列表
for url in url_list:
# 遍历url_list
r = requests.get(url)
print(url, time() - start, r.status_code)
结果
https://www.baidu.com/ 0 200
https://www.sina.com.cn/ 1 200
https://www.qq.com/ 2 200
https://www.163.com/ 2 200
http://www.iqiyi.com/ 3 200
https://www.tmall.com/ 3 200
http://www.ifeng.com/ 4 200
http://www.ifeng.com/ 4.37 200
现在,我们一行行来看刚刚用了gevent的代码。
在使用多进程加协程时,patch_all()后出现警告信息:MonkeyPatchWarning: Monkey-patching ssl after ssl has already been imported may lead to errors, including RecursionError。 有时会导致不能正常使用requests或者其他包,其实只要调整import的顺序即可,把import gevent,from gevent import monkey,monkey.patch_all()三行语句放在其他所有的import语句之前后,可以避免出现警告或者报错信息
import requests
from time import time
from gevent import monkey
#从gevent库里导入monkey模块
monkey.patch_all()
#monkey.patch_all()能把程序变成协作式运行,就是可以帮助程序实现异步。
import gevent,requests
#导入gevent、requests。
start = time()
url_list = ['https://www.baidu.com/',
'https://www.sina.com.cn/',
'https://www.qq.com/',
'http://www.sohu.com/',
'https://www.163.com/',
'http://www.iqiyi.com/',
'https://www.tmall.com/',
'http://www.ifeng.com/']
# 把8个网站封装成列表
def crawler(url):
r = requests.get(url)
# 用requests.get()函数爬取网站。
print(url,time() - start, r.status_code)
# 打印网址、请求运行时间、状态码。
tasks_list = []
for url in url_list:#遍历url_list。
task = gevent.spawn(crawler,url)
# 用gevent.spawn()函数创建任务。
tasks_list.append(task)
# 往任务列表添加任务。
gevent.joinall(tasks_list)
#执行任务列表里的所有任务,就是让爬虫开始爬取网站。
end = time()
#记录程序结束时间。
print(end-start)
#打印程序最终所需时间。
结果
https://www.baidu.com/ 0.7616446018218994 200
http://www.sohu.com/ 0.8563909530639648 200
http://www.ifeng.com/ 0.968092679977417 200
https://www.163.com/ 1.0633463859558105 200`
http://www.iqiyi.com/ 1.2518761157989502 200
https://www.qq.com/ 1.279768705368042 200
1.279768705368042
结果显而易见
Queue
1.Queue(队列),用于存取数据的有序数据结构;
2.最常见的是先进先出Queue。
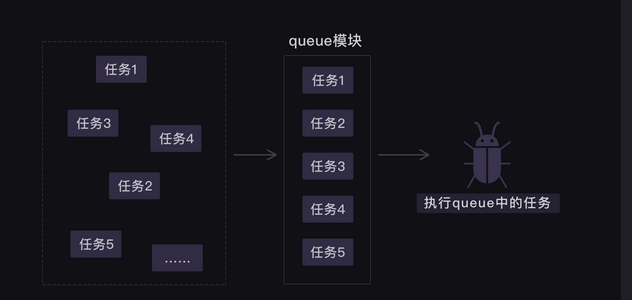
python内置Queue介绍
1.Queue 模块实现了多生产者、多消费者队列
它特别适用于信息必须在多个线程间安全地交换的多线程程序中。这个模块中的 Queue 类实现了所有必须的锁语义;
2.模块实现了三类队列,主要差别在于取得数据的顺序上
FIFO队列中,最早加入的任务会被最先得到。LIFO队列中,最后加入的任务会被最先得到(就像栈一样)。在优先队列中,任务被保持有序,拥有最小值的任务(优先级最高)被最先得到;
3.python内置Queue特点:
虽然线程安全,但同步线程开销;
4.gevent中Queue
1)Queue(先进先出);
2)LifoQueue(先进后出);
3)PriorityQueue(优先级队列)。
5.gevent中Queue特点
无线程同步开销,但有Greenlet之间的线程内同步,无法线程间操作。

当我们用多协程来爬虫,需要创建大量任务时,我们可以借助queue模块。
queue翻译成中文是队列的意思。我们可以用queue模块来存储任务,让任务都变成一条整齐的队列,就像银行窗口的排号做法。因为queue其实是一种有序的数据结构,可以用来存取数据。
这样,协程就可以从队列里把任务提取出来执行,直到队列空了,任务也就处理完了。就像银行窗口的工作人员会根据排号系统里的排号,处理客人的业务,如果已经没有新的排号,就意味着客户的业务都已办理完毕。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号