

fcn+caffe+制作自己的数据集
参考博客:
http://blog.csdn.net/jacke121/article/details/78160398
以视网膜血管分割的数据集为例:
训练样本:

训练标签:

标签图的制作依据voc数据集中的样例,将被检测的目标改为voc中的一类。

将用ps软件制作的黑底白色标签转化为,目标为(128,0,0)的单通道彩色图片,存储格式为.png。也就是将待分割的目标当做飞机。
转化png的matlab的代码如下:
imgname='15.jpg'; I=imread(imgname); I_gray=rgb2gray(I); I_bw=uint8(im2bw(I_gray))*128; I1=uint8(zeros(size(I,1),size(I,2),3)); I1(:,:,1)=I_bw; [x,map]=rgb2ind(I1,256); imgSaveName=imgname(1:length(imgname)-4); imwrite(x,map,strcat(imgSaveName,'.png'));

制作好训练集后,修改一些文件中的路径。
我的工程路径:
I:\caffe171101\caffe-master\fcn-master\retina200-fcn32s
I:\caffe171101\caffe-master\fcn-master\data\retina200_200
voc_layers.py修改:
可以删掉底下的class SBDDSegDataLayer(caffe.Layer) 训练的时候用不到。

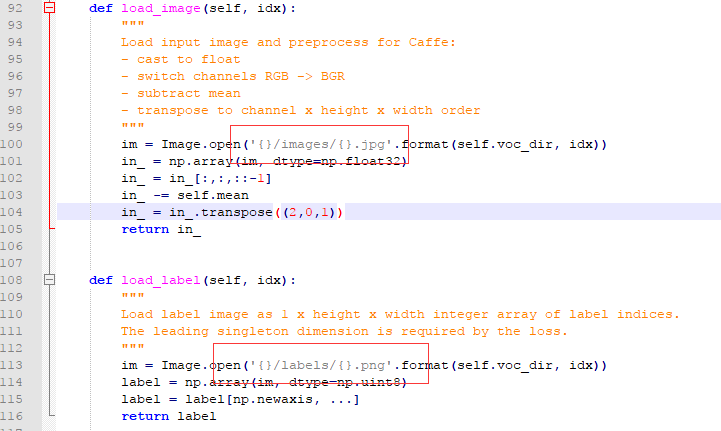
修改这三个地方的路径即可。
train.prototxt修改:

这个mean,就是计算训练样本RGB三通道的平均值。
将后面的num_output:21 全部改为num_output:2 只有背景和待分割的目标两类。
val.prototxt的修改同理。
deploy_voc_32s.prototxt 不变
solver.prototxt 不需要改动
因为是第一次训练,采用fcn32s-heavy-pascal.caffemodel作为预训练模型。
solve.py
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
weights = 'fcn32s-heavy-pascal.caffemodel'
deploy_proto = 'deploy_voc_32s.prototxt'
# init
caffe.set_device(int(0))
caffe.set_mode_gpu()
solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
vgg_net=caffe.Net(deploy_proto,weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
val = np.loadtxt('../data/retina200_200/val.txt', dtype=str)
for _ in range(50):
solver.step(2000)
score.seg_tests(solver, False, val, layer='score')
必须采用transplant的方式训练。因为这个模型的网络中的图片尺寸和自己的数据集中的图片尺寸不一样。
训练完成之后,进行预测时,这个deploy.prototxt文件需要改动一下。
将其中num_output:21的地方全部改为num_output:21
实验结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号