

用数学逻辑终结AI幻觉,亚马逊云科技的Bedrock这新功能有点东西!
新用户可获得高达 200 美元的服务抵扣金
亚马逊云科技新用户可以免费使用亚马逊云科技免费套餐(Amazon Free Tier)。注册即可获得 100 美元的服务抵扣金,在探索关键亚马逊云科技服务时可以再额外获得最多 100 美元的服务抵扣金。使用免费计划试用亚马逊云科技服务,最长可达 6 个月,无需支付任何费用,除非您选择付费计划。付费计划允许您扩展运营并获得超过 150 项亚马逊云科技服务的访问权限。
当你的AI开始“一本正经地胡说八道”时
你精心搭建的RAG(检索增强生成)应用,昨天还像个博学的专家,对答如流,今天在关键问题上却突然开始一本正经地胡说八道。它可能自信地引用了一篇不存在的论文,或者在财务报告里张冠李戴,给出了一个听起来合理但实际上完全错误的数字。这不只是尴尬,这是生产环境中的一颗定时炸弹。
这个现象,就是技术圈内人尽皆知的“AI幻觉”(AI Hallucination)。它已经成为将大语言模型(LLM)从有趣的玩具转变为能在高风险、关键任务中独当一面的可靠工具的最大障碍 。这本质上是一个信任问题。当你构建的服务,其基础随时可能凭空捏造事实时,你如何能安心地将其交付给用户?
社区为了应对这个问题,发明了各种“创可贴”式的解决方案。但它们大多是在“降低犯错概率”的维度上打转。那么,有没有一种可能,我们可以从根本上改变游戏规则?不再是祈祷AI别犯错,而是用一种近乎绝对的方式,去证明一个回答的正确性?这听起来像是科幻,但这正是亚马逊云科技正在探索的新领域,而且他们已经拿出了一个相当硬核的解决方案。
这个方案的推出时机非常微妙。当前,生成式AI的初步热潮正在退去,市场开始从追逐新奇的“概念验证”(Proof-of-Concept)转向寻求能在真实业务中创造价值、稳定可靠的企业级应用。在这个阶段,AI幻觉的风险,也从一个可以容忍的技术瑕疵,演变成了足以导致业务失败的重大负债 。亚马逊云科技此刻推出的,不仅仅是一个新功能,更是一套针对“生产级AI信任”的解决方案。它瞄准的,正是那些对准确性有着严苛要求的严肃企业级AI场景。这背后,是亚马逊云科技将其服务自身庞大、复杂且高度可靠的基础设施时所沉淀下来的“形式化方法”(Formal Methods)能力,巧妙地产品化并推向了市场 。
AI幻觉:不只是“说错话”那么简单 🤔
要解决一个问题,首先得深入理解它的根源。AI幻觉,尤其是在目前最主流的RAG架构中,其成因远比“模型知识不足”要复杂得多。
深入幻觉的“病因”
学术界的研究揭示了RAG系统中幻觉的几个核心根源:
-
核心冲突:内部知识 vs. 外部知识 大语言模型经过海量数据的预训练,其内部形成了一套庞大的“参数化知识”。然而,这套知识可能存在过时、偏见或事实性错误。RAG架构的初衷,就是通过提供外部的、权威的上下文信息,来“纠正”或“引导”模型。但问题恰恰出在这里:当内部知识与外部上下文发生冲突时,模型常常会陷入“困惑”,不知道该相信谁 。它可能会固执地依赖自己的错误记忆,而忽略了你刚刚喂给它的正确答案。
-
检索失败:“源头”就被污染了 很多时候,问题在LLM看到数据之前就已经发生了。整个RAG流程就像一条流水线,如果源头出了问题,后续再怎么努力也无济于事。研究表明,检索阶段的失败是导致幻觉的主要原因之一 。这包括:
- 数据质量差:知识库本身就包含错误或过时的信息。
- 分块不当:将一篇完整的文档切割成语义不连贯的碎片,导致模型无法理解完整的上下文。
- 检索不准:用户的提问可能很模糊,导致检索系统抓取了不相关或不完全相关的信息。所谓“垃圾进,垃圾出”(Garbage in, garbage out),就是这个道理。
-
生成缺陷:拿到正确答案也不会抄 即便我们幸运地检索到了完美、准确的上下文,LLM在最后一步的生成环节依然可能“掉链子”。模型可能会错误地解读上下文的含义,或者在融合多份文档信息时出现逻辑混乱,最终生成一个与所有源材料都相悖的结论 。
一个具体的例子
让我们用一个简单的例子来说明。假设你为一家银行构建了一个基于其最新信贷政策的RAG问答机器人。政策文档明确规定:“申请我行‘安居贷’产品的最低首付比例为20%”。这时,一个用户问道:“我只有10%的首付,能申请‘安居贷’吗?”
一个产生幻觉的AI可能会回答:“是的,对于某些特定类型的贷款,10%的首付也是可以接受的。”
这个回答就是典型的幻觉。尽管它刚刚“阅读”了规定20%的权威文件,但它庞大的通用训练数据中包含了各种五花八门的贷款产品信息,导致它错误地泛化,最终忽略了最关键、最权威的上下文,给出了一个完全错误的答案。
RAG:一把双刃剑
这个例子也揭示了一个深刻的问题:RAG技术,这个本应是解决幻觉问题的“良药”,本身却引入了一系列新的、独特的、且同样复杂的故障点。我们面临的问题,已经从单纯的“如何修复LLM”,演变成了“如何保障整个RAG信息处理流程的可靠性”。
最初,LLM产生幻觉是因为其知识是静态和有限的 。RAG的出现,通过引入外部实时数据源,极大地缓解了这个问题 。然而,正如我们所见,RAG流程的每一步——从数据源质量、用户查询的解析,到检索算法的准确性,再到最终的生成环节——都可能成为新的“幻觉策源地” 。
这意味着,简单地堆砌一个RAG系统并不能一劳永逸。我们需要一个全新的、能够凌驾于整个流程之上的“最终审计官”。这个审计官的任务,就是拿到AI最终生成的答案,然后与我们预设的“唯一真实之源”(Source of Truth)进行比对,给出一个非黑即白的裁决。而这,恰恰就是亚马逊云科技这次推出的新功能所要扮演的角色。
现有“药方”与亚马逊云科技的“基因疗法” 💊
在深入亚马逊云科技的解决方案之前,我们先快速盘点一下目前社区中主流的幻觉对抗技术。公平地说,这些方法在特定场景下都有其价值,但它们也共享一个根本性的局限。
盘点现有“药方”
- 提示工程(Prompt Engineering) :这是最基础的手段,通过在提示词中给出详尽的指令、角色扮演、提供示例等方式,来“引导”模型走向正确的方向 。它就像是给模型一份详细的“考试大纲”,简单易行,成本低廉。但它的问题在于非常“脆弱”,严重依赖工程师的经验和技巧,且无法保证100%有效。
- 模型微调(Fine-Tuning) :在特定领域的、高质量的数据集上对模型进行“加训”,让它成为该领域的“专家” 。这能显著提升模型在特定任务上的准确性,但成本高昂,且对于训练数据之外的新问题,依然可能产生幻觉。
- 自我修正(Self-Correction) :这是一类更高级的技巧,比如CoVe(Chain of Verification)等方法,其核心思想是让模型对自己生成的答案进行“反思”和“验证” 。它会引导模型先生成草稿,然后提出一系列验证性问题,最后根据验证结果修正答案。这种方法很巧妙,但它基于一个有缺陷的假设:一个会犯错的模型,能够可靠地发现并纠正自己的错误。这本质上还是一个概率游戏。
范式转移:从“概率”到“确定”
以上所有方法,无论多么复杂,其本质都是概率性的。它们的目标是降低AI犯错的可能性,但永远无法将其降为零。而Amazon Bedrock推出的新功能,其底层逻辑发生了根本性的转变,它追求的是确定性。
这种确定性的底气,来源于一个在计算机科学领域历史悠久但对大多数开发者而言略显神秘的学科——形式化方法与自动推理(Automated Reasoning) 。
简单来说,自动推理不关心统计和模式匹配,它玩的是数学和逻辑。它的工作方式是:首先,将一个领域的知识(比如公司政策、法律条款)用严格的数学语言(逻辑公式)进行描述,形成一套“铁律”;然后,当有一个新的陈述(比如AI的回答)出现时,它会运用逻辑推演,来证明这个陈述是否与这套“铁律”相符 。
这就像是从“这个答案看起来对吗?”升级到了“我能用数学方法证明这个答案与我的政策完全一致吗?”。
Amazon Bedrock Guardrails中的自动推理检查功能,正是将这一强大的理论武器产品化的成果。它能获取你的领域知识文档,自动将其翻译成形式化的逻辑规范,然后以高达99%的验证准确度,来检验AI的每一个回答是否越界 。
为了更直观地理解这种范式转移,我们可以看下面这张对比表:
| 幻觉缓解技术 | 核心原理 | 优点 | 局限性 | 性质 |
|---|---|---|---|---|
| 提示工程 | 通过详细指令和示例引导模型 。 | 实施简单,成本低。 | 脆弱,依赖个人技巧,无法保证结果。 | 概率性 / 修正性 |
| 标准RAG | 基于检索到的外部文档生成回答 。 | 提升事实性,利用最新数据。 | 易受检索错误、上下文误解的影响 。 | 概率性 / 修正性 |
| 自我修正 (如CoVe) | 提示模型自我验证和修正答案 。 | 无需外部工具即可捕获部分错误。 | 依赖有缺陷的模型来修复自身,并非万无一失。 | 概率性 / 修正性 |
| 自动推理 | 基于从“真实之源”导出的形式化逻辑规则来验证输出 。 | 提供可证明的、确定性的检查;准确率极高(可达99%);独立于LLM的内部状态。 | 需要一个定义明确的政策或知识库作为检查依据。 | 确定性 / 预防性 |
这张表格清晰地揭示了亚马逊云科技新功能的独特性。它不再是修修补补,而是为你的AI应用加装了一个独立、权威、基于数学逻辑的“事实核查员”。
揭秘!Amazon Bedrock Guardrails的自动推理魔法 🧙♂️
看到这里,你可能会想:听起来很厉害,又是数学逻辑又是形式化验证,这玩意儿用起来是不是得先考个计算机理论博士学位?
这恰恰是亚马逊云科技这次做得最“魔法”的地方。它将一个极其复杂的学科,封装成了一个任何开发者都能轻松上手的用户界面。你不需要懂什么一阶逻辑或者SAT求解器,你只需要一份写着“人话”的政策文档。
让我们以一个轻松的、非“教程”的风格,来看看这个魔法是如何运作的。
第一步:把你的“家规”喂给AI
一切都从你最信任的知识源开始。这可以是你公司的内部合规手册、网站的服务条款、产品的操作指南,任何你希望AI严格遵守的规则,通常是一份PDF文档。
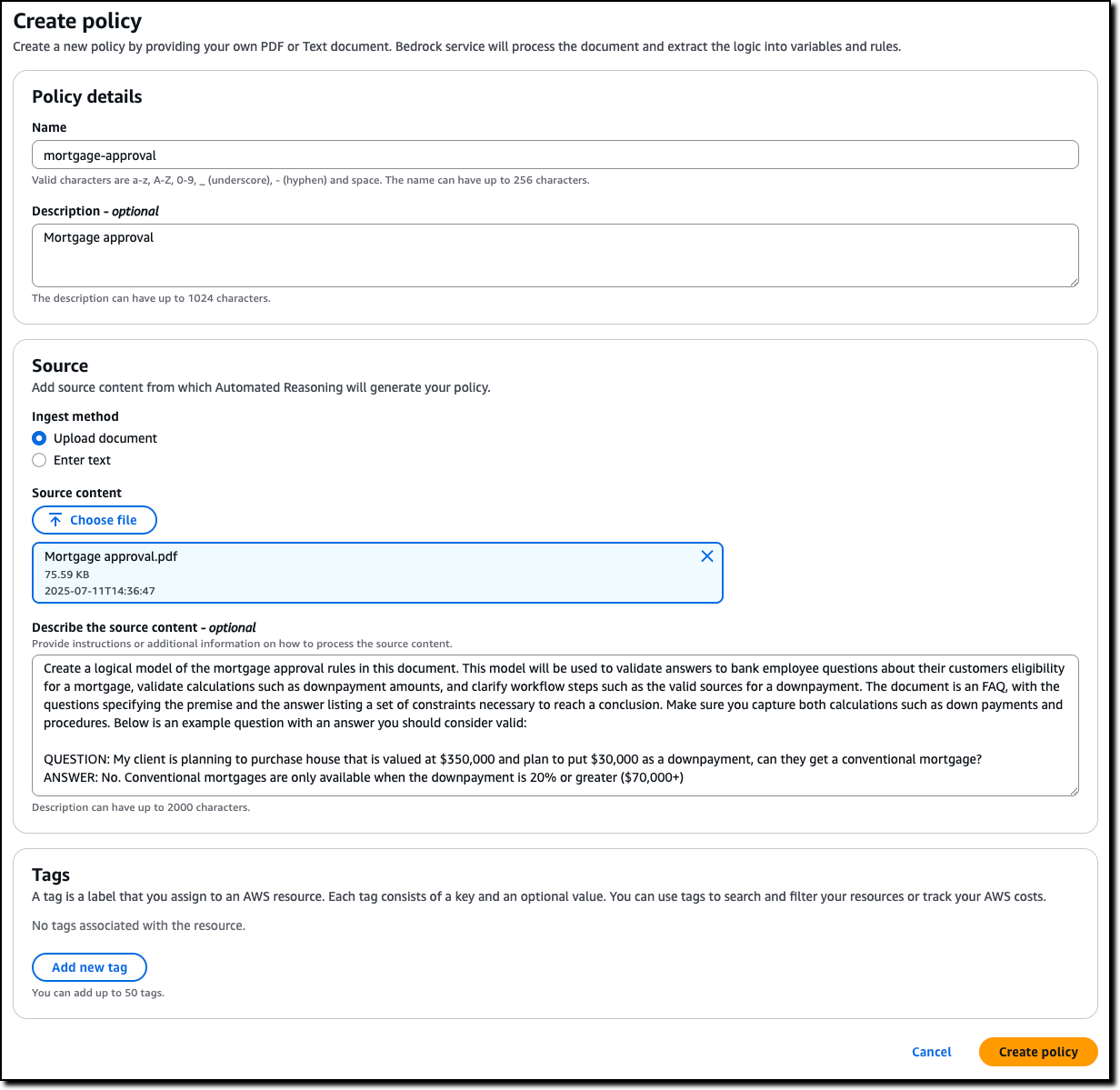
在Amazon Bedrock的控制台中,当你创建一个新的Guardrail(护栏)时,在策略类型中选择“自动推理”。然后,你只需要给这个策略起个名字,再把你的政策文档上传上去。你甚至可以额外输入一些关于这份文档的描述,或者提供一些问答示例,来帮助系统更好地理解你的意图。比如,你可以告诉它:“这是一份抵押贷款审批政策,主要变量包括信用分、首付比例和贷款类型” 。
第二步:AI帮你“划重点”,把自然语言变成逻辑规则
这绝对是整个流程中最神奇的部分。在你上传文档后,Bedrock会在后台施展它的“魔法”。它会自动阅读和分析你的自然语言文档,并将其转换成一个结构化的、形式化的策略。这个策略由三个核心部分构成:定义(Definitions) 。
- 规则(Rules) :这是策略的核心,描述了变量之间的逻辑关系。比如,系统可能会从你的文档中自动提炼出这样一条规则:“IF
credit_score< 650 ANDdown_payment_percent< 20, THENloan_applicationisrejected.”(如果信用分低于650且首付比例低于20%,则贷款申请被拒绝)。每一条规则都有唯一的ID,方便后续追踪和调试。 - 变量(Variables) :系统从文档中识别出的关键概念,比如
credit_score(信用分)、loan_type(贷款类型)等。 - 自定义类型(Custom Types) :对于那些不是简单的数字或布尔值的变量,系统会创建自定义类型。例如,
loan_type的值只能是insured(保险型)或conventional(传统型)中的一种。
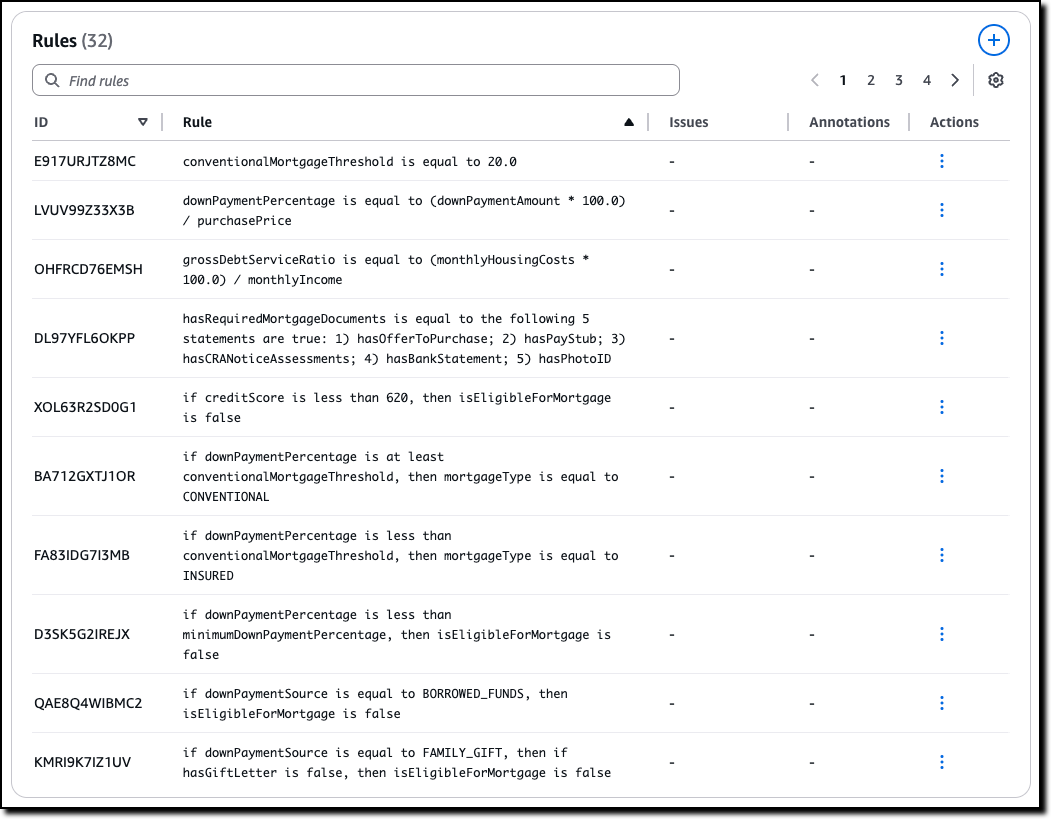
最关键的是,这个转换过程是透明的。开发者可以在控制台清晰地看到AI为你提炼出的所有规则、变量和类型,确保机器的理解与你的预期完全一致。
第三步:模拟“实战演练”,确保逻辑万无一失
在将这个“护栏”正式部署到你的AI应用之前,你需要100%确定它提炼的逻辑是准确无误的。这时,测试(Tests)功能就派上用场了。
这里又有一个令人惊喜的“魔法”:自动化场景生成。Bedrock可以根据它刚刚从你文档中定义的规则,自动生成一系列测试用例。这能极大地节省你编写测试用例的时间,并扩大测试的覆盖范围 。
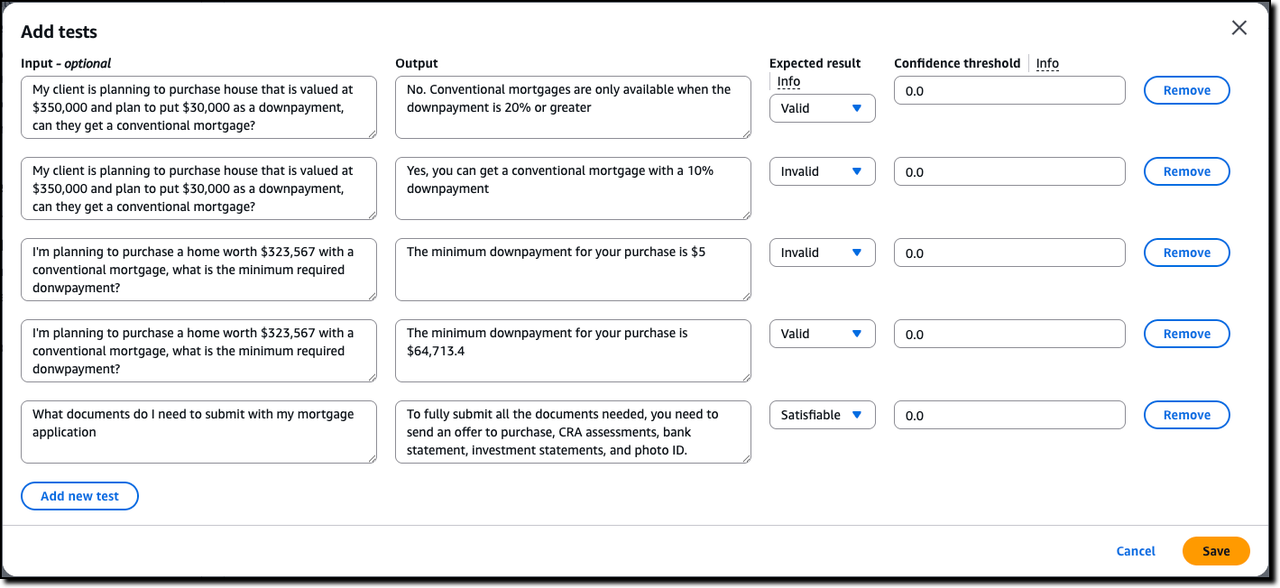
当然,你也可以手动添加更复杂的测试场景。对于每个测试,你需要提供一个输入(比如用户的问题)和一个输出(比如AI可能的回答),然后设定一个预期的验证结果:
- 有效(Valid) :表示AI的回答是正确的,完全符合政策。
- 无效(Invalid) :表示AI的回答是错误的,违反了政策。
- 可满足(Satisfiable) :这是一个非常有意思的状态。它表示AI的回答在某些特定假设下可能是对的,也可能是错的。这通常意味着你的原始政策文档本身存在模糊或不明确之处,需要澄清。这能帮你发现并修复知识库中的“漏洞”。
当你运行所有测试后,如果某个测试失败了,系统会给出非常清晰的反馈。它会明确告诉你,是哪条具体的规则导致了逻辑上的矛盾,让你能够轻松地定位问题,并返回去修正你的原始文档或调整系统生成的规则 。
看穿“魔法”的本质
这个看似神奇的用户友好流程,实际上是该功能最具革命性的地方。形式化验证技术本身非常强大,但一直以来都因其陡峭的学习曲线和高昂的使用门槛,被束之高阁,成为少数专家的“屠龙之技” 。
亚马逊云科技通过这个功能,实际上是将形式化方法的强大能力民主化了。它将最困难的步骤——从自然语言到形式化逻辑的翻译,以及测试用例的生成——完全自动化,从而将任何使用Bedrock的开发者使用这项高级技术的门槛降到了近乎为零。
这背后隐藏着一个更深远的战略布局。这种易用性会极大地促进该功能的普及。随着越来越多的开发者将其应用于各种各样、千奇百怪的业务策略,能够收集到海量的、关于“自动翻译”在哪些场景下表现优异、在哪些场景下会遇到困难的宝贵数据。这些数据,对于改进其底层的自动推理引擎来说,是一座不折不扣的金矿。这形成了一个亚马逊云科技自身非常推崇的“飞轮效应”(Virtuous Cycle):更简单的使用体验带来更多的用户 -> 更多的用户和应用场景反馈改进了核心引擎 -> 更强大的核心引擎让功能变得更好用、更智能 -> 从而吸引更多用户。
可以说,这个简洁的用户界面,是一个战略性的“特洛伊木马”,它将一项高深的小众技术带给了广大的开发者群体,并通过一个正向反馈循环,不断巩固亚马逊云科技在“可信AI”领域的领导地位。
这玩意儿好在哪?为什么说它是开发者的福音?✨
理论和工作流程都讲完了,那么在实际开发中,这个功能到底能带来哪些实实在在的好处呢?我们不空谈特性,而是从一个真实的案例和开发者的痛点出发。
高风险场景的“定心丸”:PwC的成功实践
普华永道(PwC)与亚马逊云科技合作,开发了一个用于公用事业停电管理的复杂系统。这可不是一个简单的闲聊机器人,它处理的是与关键基础设施相关的严肃业务 。
在这个系统中,PwC就利用了自动推理检查来评估AI生成的响应。当AI给出一个操作建议或状态报告时,该功能会立即对其进行验证。如果响应被判定为“无效”或“可满足”(即存在模糊性),系统会利用自动推理的检查结果来重写或改进这个响应,确保最终呈现给操作人员的信息是100%准确和清晰的。
这个案例传递了一个强有力的信号:这项技术已经准备好在受严格监管、高风险、零容错的企业环境中大显身手。对于那些正在金融、医疗、法律等领域构建AI应用的开发者来说,这无疑是一颗强大的“定心丸”。
开发者真正关心的那些事
除了在关键任务中的压舱石作用,该功能在设计上也充分考虑了开发者的日常工作流和需求。
- 即插即用的模块化设计:“它不是一个孤岛。”自动推理检查只是Bedrock Guardrails提供的六种模块化策略之一。你可以像搭积木一样,轻松地将其与内容过滤器(过滤暴力、色情内容)、敏感信息(PII)脱敏、自定义的拒绝主题列表等其他“护栏”组合使用,构建一个分层的、全方位的AI安全防护体系 。
- 强大的兼容性:“无论你钟爱哪个模型……”这是对开发者来说至关重要的一点。Guardrails,包括自动推理检查,可以应用于任何通过Bedrock提供的模型。这不仅包括亚马逊云科技自家的Titan系列模型,也同样适用于来自OpenAI、Anthropic、Google等第三方的顶尖模型。亚马逊云科技提供的不是一个封闭花园里的专属工具,而是一个通用的、跨模型的“安全层” 。这给了开发者最大的选择自由,避免了厂商锁定。
- 能处理“大家伙” :在真实的企业场景中,知识库往往不是几页纸,而是动辄上百页的复杂文档。该功能单个构建就支持高达80K令牌的文档处理能力,大约相当于100页的内容。这意味着它可以轻松应对那些冗长复杂的政策手册、法律文件或技术规范,满足现实世界的需求 。
- 简化维护:业务规则不是一成不变的。当你的公司政策更新时,你只需要上传新版本的文档,然后重新运行之前保存的所有验证测试即可。这种能够保存和重复运行测试的能力,极大地简化了策略的长期维护和迭代过程,让你的AI“护栏”能与业务发展保持同步 。
不再是“薛定谔的猫”,让AI的回答确定无疑 🎯
回顾企业级AI的发展历程,可以说是一场从“概率性的不确定”走向“确定性的信任”的漫长征途。我们已经走过了那个对AI的回答只能“听天由命”的阶段。现在,我们需要的不再是“祈祷”我们的AI是正确的,而是一个能够证明它正确的系统。
Amazon Bedrock Guardrails中的自动推理检查功能,正是这场征途中的一个重要里程碑。它让AI的回答不再像一个“薛定谔的猫”,在被观测(验证)之前处于对错叠加的不确定状态。它提供了一种工具,让我们能够以近乎数学的严谨性,去锁定答案的正确性。
从更宏观的视角看,这个功能也绝非一个孤立的工具。它是亚马逊云科技构建其端到端企业级AI平台战略的关键一环。这个战略不仅涵盖了模型的选择、应用的构建和部署,更重要的是,它将治理(Governance)提升到了前所未有的高度。
对于那些肩负着构建下一代AI应用、需要让企业和客户真正能够信赖其产出的开发者而言,用数学逻辑来强制执行规则,已经不再是一个“有了更好”的选项,它正在成为未来的标配。亚马逊云科技在Bedrock中迈出的这一大步,无疑为这个未来指明了方向,并且绝对值得你在下一个严肃的AI项目中进行深入的探索和尝试。
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号