
Group By的使用 ,group_conact,with rollup
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表

3、简单Group By
示例1
select 类别, sum(数量) as 数量之和 from A group by 类别
返回结果如下表,实际上就是分类汇总。

4、Group By 和 Order By
示例2
select 类别, sum(数量) AS 数量之和 from A group by 类别 order by sum(数量) desc
返回结果如下表
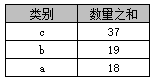
在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
select 类别, sum(数量) as 数量之和, 摘要 from A group by 类别 order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6、Group By All
示例4
select 类别, 摘要, sum(数量) as 数量之和 from A group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表

“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
select 类别, 摘要, sum(数量) AS 数量之和 from A group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
示例5:求各组平均值
select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
select 类别, sum(数量) as 数量之和 from A group by 类别 having sum(数量) > 18
示例9:Having和Where的联合使用方法
select 类别, SUM(数量)from A where 数量 > 8 group by 类别 having SUM(数量) > 10
本文中使用的例子均在下面的数据库表tt2下执行:
1、功能:将多个字符串连接成一个字符串。
2、语法:concat(str1, str2,...)
返回结果为连接参数产生的字符串,如果有任何一个参数为null,则返回值为null。
3、举例:
例1:select concat (id, name, score) as info from tt2;
中间有一行为null是因为tt2表中有一行的score值为null。
例2:在例1的结果中三个字段id,name,score的组合没有分隔符,我们可以加一个逗号作为分隔符:
这样看上去似乎顺眼了许多~~
但是输入sql语句麻烦了许多,三个字段需要输入两次逗号,如果10个字段,要输入九次逗号...麻烦死了啦,有没有什么简便方法呢?——于是可以指定参数之间的分隔符的concat_ws()来了!!!
1、功能:和concat()一样,将多个字符串连接成一个字符串,但是可以一次性指定分隔符~(concat_ws就是concat with separator)
2、语法:concat_ws(separator, str1, str2, ...)
说明:第一个参数指定分隔符。需要注意的是分隔符不能为null,如果为null,则返回结果为null。
3、举例:
例3:我们使用concat_ws()将 分隔符指定为逗号,达到与例2相同的效果:
例4:把分隔符指定为null,结果全部变成了null:
前言:在有group by的查询语句中,select指定的字段要么就包含在group by语句的后面,作为分组的依据,要么就包含在聚合函数中。(有关group by的知识请戳:浅析SQL中Group By的使用)。
例5:
该例查询了name相同的的人中最小的id。如果我们要查询name相同的人的所有的id呢?
当然我们可以这样查询:
例6:
但是这样同一个名字出现多次,看上去非常不直观。有没有更直观的方法,既让每个名字都只出现一次,又能够显示所有的名字相同的人的id呢?——使用group_concat()
1、功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果。
2、语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
3、举例:
例7:使用group_concat()和group by显示相同名字的人的id号:
例8:将上面的id号从大到小排序,且用'_'作为分隔符:
例9:上面的查询中显示了以name分组的每组中所有的id。接下来我们要查询以name分组的所有组的id和score:
转载 https://blog.csdn.net/Mary19920410/article/details/76545053
作者:艾格尔
链接:https://www.jianshu.com/p/43cb4c5d33c1
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号