

一、 引言:为什么RAG是构建可信AI应用的关键?
大语言模型(LLM)如ChatGPT在通用任务上表现惊人,但其在企业级或个人知识管理应用中面临两大核心挑战:
知识实时性差:模型训练数据存在滞后性,无法获取最新、最私有的信息。
事实准确性难保:容易产生“幻觉”,对于不熟悉的内容会编造看似合理但错误的答案。
RAG(检索增强生成) 架构应运而生,它巧妙地将信息检索技术与大语言模型相结合,为核心问题提供了优雅的解决方案。其核心流程如同一位严谨的学者:
检索(Retrieval):根据用户问题,从海量知识库中精准“检索”出最相关的信息片段。
增强(Augmentation):将这些信息作为“证据”或“上下文”,与原始问题一起组装成新的、信息更丰富的提示。
生成(Generation):LLM基于这个“有据可依”的提示生成答案,显著提升准确性和可信度。
本文将不仅实现一个基础RAG系统,更会深入探讨其生产环境下的优化方案。
二、 技术栈深度解析:选型背后的思考
一个稳定可靠的RAG系统,技术选型至关重要。我们的选择基于以下考量:
大模型(LLM):ChatGLM3-6B
优势:优秀的双语能力、完全开源、支持INT4量化可在消费级显卡部署。其新增的Code Interpreter功能为未来扩展留下想象空间。
部署:使用transformers库进行本地加载,确保数据隐私和离线可用性。
向量数据库:ChromaDB
优势:轻量级、内存优先、API简洁,无需外部服务,简化了项目复杂度,非常适合原型验证和中小规模应用。
备选:生产环境中,可平滑迁移至Milvus或Qdrant以支持十亿级向量。
嵌入模型(Embedding Model):BAAI/bge-large-zh-v1.5
优势:在中文语义相似度基准(如MTEB)上表现卓越,能深度理解中文语境下的语义关联,是检索准确性的基石。
Web框架:FastAPI
优势:利用现代Python特性(如类型提示),自动生成交互式API文档,异步支持能力完美契合I/O密集型的AI应用。
前端界面:Gradio
优势:只需几行代码即可构建美观的Web UI,极大降低测试和演示的门槛。
系统架构图如下(可用Mermaid语法描述):
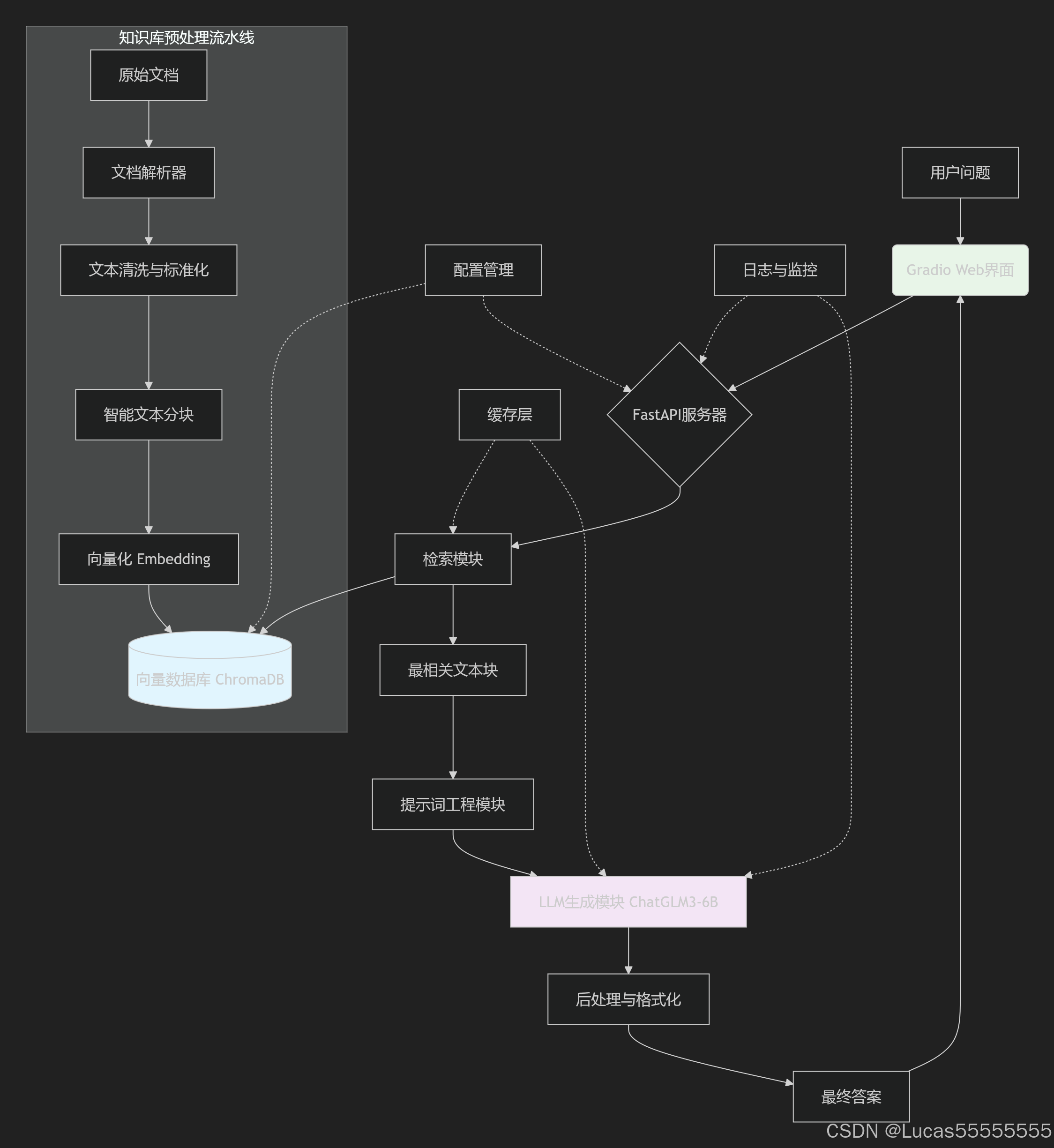
三、 项目实战:从零到一的完整实现
3.1 环境配置与依赖管理
首先,创建并激活Python虚拟环境,然后使用requirements.txt管理依赖。
requirements.txt
fastapi==0.104.1
uvicorn==0.24.0
chromadb==0.4.15
sentence-transformers==2.2.2
transformers==4.35.2
torch==2.1.0
gradio==4.8.0
pypdf2==3.0.1 # 用于PDF文档解析
sentencepiece==0.1.99 # ChatGLM3分词依赖
accelerate==0.24.1 # 用于模型加载优化安装命令:pip install -r requirements.txt
3.2 核心模块一:智能化知识库构建(knowledge_base.py)
文本分块是RAG效果的第一个关键点。我们采用递归分割法,优先按段落、标题等自然边界进行分割。
import os
import re
from chromadb import Documents, EmbeddingFunction, Client
from sentence_transformers import SentenceTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 更健壮的Embedding函数
class BGEEmbeddingFunction(EmbeddingFunction):
def __init__(self, model_name='BAAI/bge-large-zh-v1.5', device='cpu'):
self.model = SentenceTransformer(model_name, device=device)
# 指令模型,为检索任务优化
self.query_instruction = "为这个句子生成表示用于检索相关文章:"
def __call__(self, input: Documents):
# 对存储的文档,正常编码
return self.model.encode(input, normalize_embeddings=True).tolist()
def encode_queries(self, queries: Documents):
# 对查询,可以添加指令
instructed_queries = [self.query_instruction + q for q in queries]
return self.model.encode(instructed_queries, normalize_embeddings=True).tolist()
def smart_text_splitter(text):
"""使用递归字符分割,优先保持段落完整性"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 目标块大小
chunk_overlap=80, # 块间重叠大小,保持上下文
length_function=len,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", "、", ""] # 分割优先级
)
return text_splitter.split_text(text)
def build_knowledge_base(docs_dir="./docs", persist_directory="./chroma_db"):
"""构建知识库并持久化到磁盘"""
# 初始化ChromaDB客户端,指定持久化目录
client = Client(persist_directory=persist_directory)
# 创建或获取集合。注意:生产环境应使用本地部署的embedding模型。
collection = client.get_or_create_collection(
name="knowledge_base",
embedding_function=BGEEmbeddingFunction()
)
# 支持多种文档格式
supported_extensions = ('.txt', '.pdf', '.md')
for filename in os.listdir(docs_dir):
if filename.endswith(supported_extensions):
filepath = os.path.join(docs_dir, filename)
print(f"正在处理文档: {filename}")
try:
# 文本文件处理
if filename.endswith('.txt'):
with open(filepath, 'r', encoding='utf-8') as f:
text = f.read()
# 此处可扩展PDF、Markdown解析器
# elif filename.endswith('.pdf'):
# text = extract_text_from_pdf(filepath)
else:
continue
# 智能文本分割
chunks = smart_text_splitter(text)
if not chunks:
continue
# 生成唯一ID
doc_ids = [f"{filename}_chunk_{i}" for i in range(len(chunks))]
# 元数据,记录来源
metadatas = [{"source": filename, "chunk_index": i} for i in range(len(chunks))]
# 批量添加到向量数据库
collection.add(
documents=chunks,
ids=doc_ids,
metadatas=metadatas
)
print(f"成功加载 {filename},分割为 {len(chunks)} 个块。")
except Exception as e:
print(f"处理文档 {filename} 时出错: {e}")
continue
# 持久化数据到磁盘
client.persist()
print("知识库构建与持久化完成!")
return collection
if __name__ == "__main__":
kb_collection = build_knowledge_base()3.3 核心模块二:FastAPI服务与增强的RAG链(main.py)
我们实现一个更健壮、功能更丰富的API服务。
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import List, Optional
import uvicorn
import torch
from transformers import AutoTokenizer, AutoModel
from knowledge_base import build_knowledge_base, BGEEmbeddingFunction
from chromadb import Client
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = FastAPI(
title="智能知识库问答系统 API",
description="基于RAG架构的本地知识问答系统",
version="2.0"
)
# 全局变量
knowledge_collection = None
tokenizer = None
model = None
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化ChatGLM3模型(简化版,实际需按官方文档加载)
def load_chatglm_model():
"""加载ChatGLM3模型和分词器"""
global tokenizer, model
try:
model_path = "THUDM/chatglm3-6b"
logger.info(f"正在从 {model_path} 加载模型...")
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16, # 半精度加载,节省显存
device_map="auto" # 自动分配至多GPU
).eval()
logger.info("ChatGLM3模型加载成功!")
except Exception as e:
logger.error(f"模型加载失败: {e}")
raise e
class QuestionRequest(BaseModel):
question: str
top_k: Optional[int] = 5
temperature: Optional[float] = 0.1 # 控制生成多样性
class QuestionResponse(BaseModel):
answer: str
relevant_sources: List[str]
retrieved_contexts: List[str] # 返回检索到的上下文,增强可解释性
class HealthCheckResponse(BaseModel):
status: str
model_loaded: bool
knowledge_base_ready: bool
def construct_prompt(question, contexts):
"""构建高质量的提示词模板"""
context_str = "\n\n".join([f"[出处: {ctx['source']}]\n{ctx['text']}" for ctx in contexts])
prompt = f"""你是一个专业的AI助手,需要严格根据提供的背景信息来回答问题。
请遵循以下规则:
1. 答案必须基于提供的背景信息生成。
2. 如果背景信息不足以回答问题,请明确告知用户并说明原因。
3. 保持答案的准确性和专业性,避免编造信息。
4. 如果问题与背景信息无关,请礼貌地表示你无法回答。
【背景信息】
{context_str}
【用户问题】
{question}
【答案】
"""
return prompt
def rag_qa(question: str, top_k: int = 5) -> tuple:
"""增强版的RAG问答流程"""
if not knowledge_collection:
raise HTTPException(status_code=503, detail="知识库未就绪")
# 1. 检索:从知识库中查找相关片段
try:
results = knowledge_collection.query(
query_texts=[question],
n_results=top_k,
include=['documents', 'metadatas'] # 返回文档和元数据
)
retrieved_docs = results['documents'][0]
metadatas = results['metadatas'][0]
# 组织上下文信息
contexts = [{"text": doc, "source": meta['source']} for doc, meta in zip(retrieved_docs, metadatas)]
except Exception as e:
logger.error(f"检索过程出错: {e}")
raise HTTPException(status_code=500, detail=f"检索失败: {str(e)}")
# 2. 增强:构建提示词
prompt = construct_prompt(question, contexts)
# 3. 生成:调用ChatGLM3生成答案
try:
if model is None:
# 降级方案:使用模拟响应或简单拼接
answer = "[模拟模式] 已成功检索到相关信息,但模型未加载。检索到的关键内容如下:\n" + "\n".join(retrieved_docs[:2])
else:
# 使用ChatGLM3生成
inputs = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(**inputs, max_length=2048, temperature=0.1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取模型生成部分,去除提示词
answer = answer.split("【答案】")[-1].strip()
except Exception as e:
logger.error(f"生成过程出错: {e}")
raise HTTPException(status_code=500, detail=f"答案生成失败: {str(e)}")
# 提取唯一来源
sources = list(set([ctx['source'] for ctx in contexts]))
context_texts = [ctx['text'] for ctx in contexts]
return answer, sources, context_texts
@app.on_event("startup")
async def startup_event():
"""服务启动时初始化模型和知识库"""
background_tasks = BackgroundTasks()
background_tasks.add_task(initialize_services)
return background_tasks
async def initialize_services():
"""异步初始化服务"""
global knowledge_collection
try:
# 先加载知识库
knowledge_collection = build_knowledge_base()
# 然后加载模型(耗时长)
load_chatglm_model()
except Exception as e:
logger.error(f"服务初始化失败: {e}")
@app.get("/health", response_model=HealthCheckResponse)
async def health_check():
"""健康检查端点"""
return HealthCheckResponse(
status="healthy",
model_loaded=model is not None,
knowledge_base_ready=knowledge_collection is not None
)
@app.post("/ask", response_model=QuestionResponse)
async def ask_question(request: QuestionRequest):
"""核心问答接口"""
try:
answer, sources, contexts = rag_qa(request.question, request.top_k)
return QuestionResponse(
answer=answer,
relevant_sources=sources,
retrieved_contexts=contexts
)
except HTTPException:
raise
except Exception as e:
logger.error(f"问答接口异常: {e}")
raise HTTPException(status_code=500, detail="内部服务器错误")
@app.get("/")
async def root():
return {"message": "智能知识库问答系统已启动,请访问 /docs 查看API文档"}
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000, reload=True)3.4 核心模块三:集成Gradio打造友好Web界面(gradio_ui.py)
提供一个无需编程即可测试的界面。
import gradio as gr
import requests
import json
# FastAPI服务地址
API_URL = "http://127.0.0.1:8000"
def predict(question, top_k):
"""调用后端API"""
try:
response = requests.post(
f"{API_URL}/ask",
json={"question": question, "top_k": int(top_k)}
)
if response.status_code == 200:
result = response.json()
# 格式化显示结果
answer = result["answer"]
sources = "\n".join([f"- {source}" for source in result["relevant_sources"]])
contexts = "\n\n".join([f"[上下文 {i+1}]: {ctx}" for i, ctx in enumerate(result["retrieved_contexts"])])
full_output = f"""## 答案
{answer}
## 参考来源
{sources}
## 检索到的上下文
{contexts}"""
return full_output
else:
return f"错误: {response.text}"
except Exception as e:
return f"请求失败: {str(e)}"
# 创建Gradio界面
with gr.Blocks(title="智能知识库问答系统", theme=gr.themes.Soft()) as demo:
gr.Markdown("""
# 智能知识库问答系统
基于RAG技术,为您提供准确可靠的问答服务。
""")
with gr.Row():
with gr.Column(scale=1):
question = gr.Textbox(
label="请输入您的问题",
placeholder="例如:RAG技术的核心优势是什么?",
lines=3
)
top_k = gr.Slider(
minimum=1,
maximum=10,
value=3,
step=1,
label="检索上下文数量 (top_k)"
)
submit_btn = gr.Button("提交问题", variant="primary")
with gr.Column(scale=2):
output = gr.Markdown(label="问答结果")
# 绑定事件
submit_btn.click(fn=predict, inputs=[question, top_k], outputs=output)
question.submit(fn=predict, inputs=[question, top_k], outputs=output)
# 示例问题
gr.Examples(
examples=[
["什么是RAG?它的主要优势有哪些?", 3],
["本文中提到了哪些技术栈?", 5],
["如何优化检索效果?", 4]
],
inputs=[question, top_k]
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860, share=False)四、 进阶优化:从“能用”到“好用”的策略
4.1 检索质量提升方案
- 重排序(Re-Ranking):
# 伪代码示例:在检索后增加重排序步骤 from sentence_transformers import CrossEncoder # 加载交叉编码器(精度高但速度慢) reranker = CrossEncoder('BAAI/bge-reranker-large') def rerank_documents(query, documents, top_n=3): # 构建查询-文档对 pairs = [[query, doc] for doc in documents] # 计算相关性分数 scores = reranker.predict(pairs) # 按分数排序并返回top_n ranked_indices = np.argsort(scores)[::-1][:top_n] return [documents[i] for i in ranked_indices] - 混合检索(Hybrid Search):结合基于关键词的BM25检索和向量检索,取长补短。
4.2 提示词工程优化
角色设定:为模型设定更明确的角色,如“你是一位资深的技术专家”。
分步思考:要求模型先复述检索到的信息,再基于此生成答案。
引用格式:要求模型在答案中标注引用的具体来源。
五、 部署与使用指南
- 项目结构:
rag-assistant/ │ ├── docs/ # 存放知识库文档 ├── chroma_db/ # 向量数据库持久化目录 ├── knowledge_base.py # 知识库构建模块 ├── main.py # FastAPI主服务 ├── gradio_ui.py # Web界面 └── requirements.txt - 启动步骤:
# 1. 安装依赖 pip install -r requirements.txt # 2. 将您的文档(PDF、TXT)放入 docs/ 文件夹 # 3. 启动FastAPI服务(后台运行) python main.py & # 4. 启动Gradio Web界面 python gradio_ui.py访问
http://localhost:7860即可开始使用。
六、 总结与开源
本文深入探讨了RAG系统的完整实现路径,从技术选型、代码实现到优化策略,提供了一个生产可用的解决方案。通过本项目,你可以:
✅ 掌握RAG架构的核心原理与实现
✅ 搭建本地化的知识问答系统,保障数据隐私
✅ 获得一个可二次开发的开源项目基础
✅ 了解检索效果优化的多种实用技巧
七、 互动与未来展望
技术交流是进步的阶梯,欢迎在评论区留下你的想法和问题:
实践反馈:在部署过程中遇到了什么困难?性能如何
功能建议:你希望下一个版本增加什么功能?(如:多轮对话、联网搜索、多模态支持)
技术探讨:对于RAG的优化,你有哪些独到的见解?


 浙公网安备 33010602011771号
浙公网安备 33010602011771号