

文章目录
前言
本文将介绍 BEVFormer —— 一种基于时空 Transformer 的多摄像头 Bird’s-Eye-View (BEV) 表示学习方法。该工作发表于 ECCV 2022,由 Haidong Zhang, Yinhao Li, Yuexin Ma, Xinyu Cai, Haofei Xu, Yilun Chen, Tai Wang, Xinggang Wang, Wenyu Liu, Hongyang Li, Yu Qiao, Wenqi Shao 等研究者提出,主要来自 华中科技大学、商汤科技、上海人工智能实验室 等机构。
- 论文地址:arXiv:2203.17270
- 代码实现:GitHub - fundamentalvision/BEVFormer
- ️ 发表年份:2022
这篇论文是 camera-only 自动驾驶感知的重要里程碑工作,在 nuScenes 基准上大幅提升了基于相机的 3D 检测性能,并提出了统一的时空 Transformer 框架。
说明
关于 BEVFormer 论文本身的翻译与综述在社区中已经有许多优秀的文章,因此本文不再重复逐段介绍或翻译论文内容。本文将把重点放在 源码实现的拆解与解析 上,结合官方开源仓库,从工程实践的角度来深入理解 BEVFormer 的设计思路。我们会围绕以下几个方面展开:数据流向、整体框架、关键模块源码解析,并通过代码级的分析来帮助大家更直观地掌握该方法的实现细节与运行机制。
- 由于作者时间有限,后续再慢慢完善
- 作者基于原始代码实现和自己的数据集调试,绘制了详细的网络结构图,图中标出详细的数据流向、数据shape变化等
框架结构
总体架构(来源于论文中)
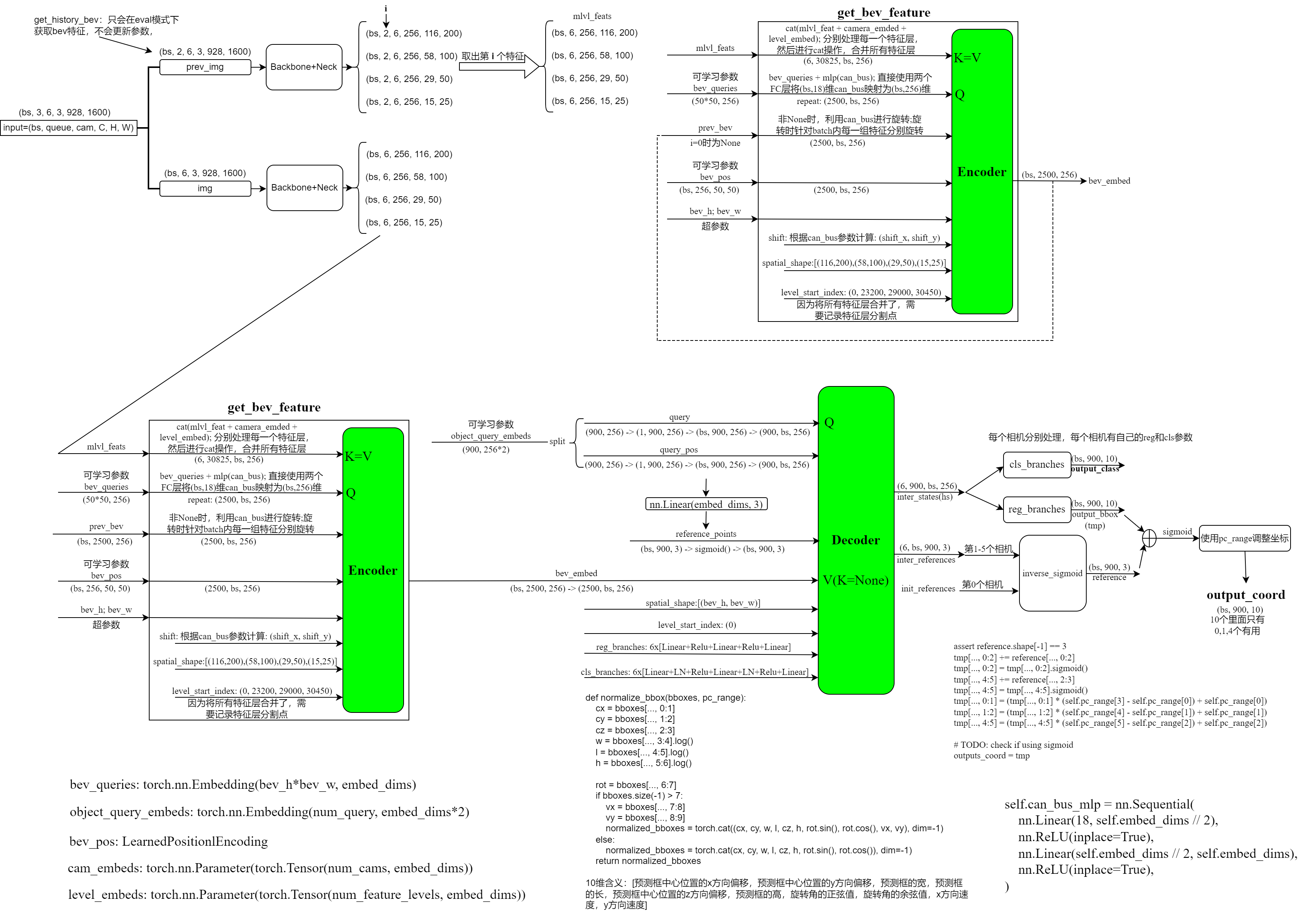
完整架构详细图示(包含数据shape)
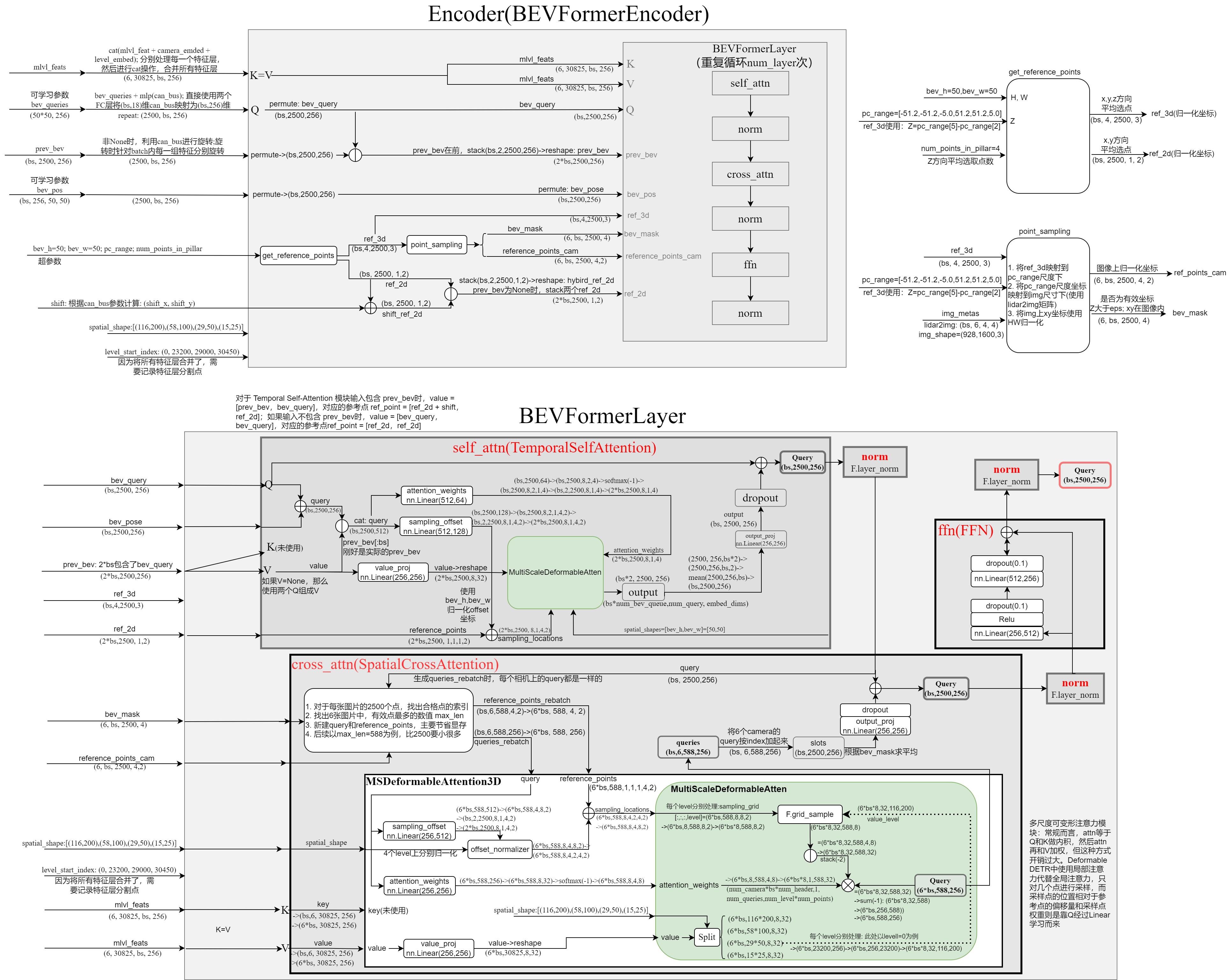
Encoder完整结构详细图示(包含数据shape)
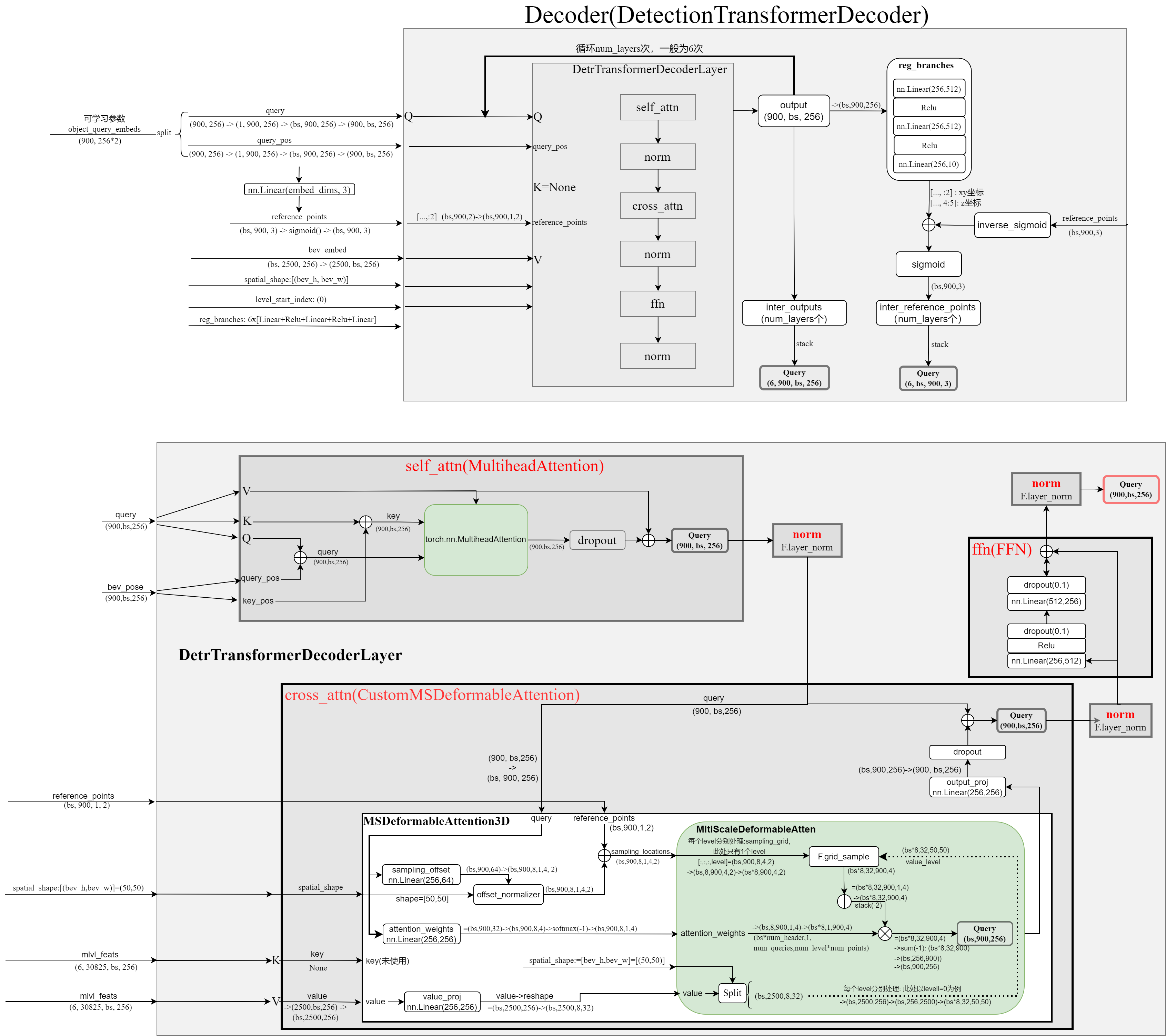
Decoder完整结构详细图示(包含数据shape)
核心源码详解
使用传统的CNN网络提取图像特征
# projects/mmdet3d_plugin/bevformer/detectors/bevformer.py 输出的图像特征为:(bs, len_queue, num_cam, channel, img_h, img_w) 即:torch.Size([1, 3, 6, 3, 480, 800]) 其中len_queue=3, 表示包含了过去的两组图片+当前的一组图片根据过去的图片信息获取prev_bev特征
# projects/mmdet3d_plugin/bevformer/detectors/bevformer.py def obtain_history_bev(self, imgs_queue, img_metas_list): """Obtain history BEV features iteratively. To save GPU memory, gradients are not calculated. """ self.eval() # imgs_queue: torch.Size([1, 2, 6, 3, 480, 800]), 第二维为除去当前图片后,过去的2张图片 with torch.no_grad(): prev_bev = None bs, len_queue, num_cams, C, H, W = imgs_queue.shape imgs_queue = imgs_queue.reshape(bs*len_queue, num_cams, C, H, W) # imgs_queue: torch.Size([2, 6, 3, 480, 800]) # 特征提取很简单(中间会使用GridMask数据增强:针对信息保留与删除之间的平衡问题): # torch.Size([2, 6, 3, 480, 800]) -> torch.Size([12, 3, 480, 800]) # backbone输出:tuple, len()=1, shape=torch.Size([12, 2048, 15, 25]), 即去了stride=32的输出特征 # 经过FPN层后的输出(tiny模型只用了一个特征层,base的话使用了3个特征层,输出就会有三个特征层):shape=torch.Size([12, 256, 15, 25]),维度将为256维了 # 最后再将特征恢复为输入类型: # torch.Size([12, 256, 15, 25]) -> torch.Size([1, 2, 6, 256, 15, 25]) img_feats_list = self.extract_feat(img=imgs_queue, len_queue=len_queue) # 这个循环的作用其实很简单: # 比如我们的len(queue)=2, 即过去时刻有2组图片,特征shape均为torch.Size([1, 6, 256, 15, 25]) # 对于第0组图片,提取bev特征(prev_bev=None):bev_0 # 对于第1组图片,提取bev特征(prev_bev=bev_0):bev_1 # 最终输出bev_1作为历史bev特征 for i in range(len_queue): img_metas = [each[i] for each in img_metas_list] if not img_metas[0]['prev_bev_exists']: prev_bev = None # img_feats = self.extract_feat(img=img, img_metas=img_metas) # 取出每一时刻的图像,即 # torch.Size([1, 2, 6, 256, 15, 25]) -> torch.Size([1, 6, 256, 15, 25]) img_feats = [each_scale[:, i] for each_scale in img_feats_list] # 提取当前时刻的bev特征,详见BEVFormerHead说明 prev_bev = self.pts_bbox_head( img_feats, img_metas, prev_bev, only_bev=True) self.train() return prev_bevBEVFormerHead
class BEVFormerHead(DETRHead): def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False): """Forward function. Args: mlvl_feats (tuple[Tensor]): Features from the upstream network, each is a 5D-tensor with shape (B, N, C, H, W). prev_bev: previous bev featues only_bev: only compute BEV features with encoder. Returns: all_cls_scores (Tensor): Outputs from the classification head, \ shape [nb_dec, bs, num_query, cls_out_channels]. Note \ cls_out_channels should includes background. all_bbox_preds (Tensor): Sigmoid outputs from the regression \ head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \ Shape [nb_dec, bs, num_query, 9]. """ bs, num_cam, _, _, _ = mlvl_feats[0].shape dtype = mlvl_feats[0].dtype # self.query_embedding = nn.Embedding(self.num_query, self.embed_dims * 2) # self.num_query=900, 为超参数 # self.embed_dims=256,超参数 # object_query_embeds: torch.Size([900, 256*2]) object_query_embeds = self.query_embedding.weight.to(dtype) # self.bev_embedding = nn.Embedding(self.bev_h * self.bev_w, self.embed_dims) # self.bev_h=50, self.bev_w=50, 均为超参数 # bev_queries: torch.Size([2500, 256]) bev_queries = self.bev_embedding.weight.to(dtype) # bev_mask: torch.Size([1, 50, 50]), shape=(bs, bev_h, bev_w) bev_mask = torch.zeros((bs, self.bev_h, self.bev_w), device=bev_queries.device).to(dtype) # bev_pos: torch.Size([1, 256, 50, 50]) # 此处使用的是 LearnedPositionalEncoding bev_pos = self.positional_encoding(bev_mask).to(dtype) if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround # PerceptionTransformer return self.transformer.get_bev_features( mlvl_feats, bev_queries, self.bev_h, self.bev_w, grid_length=(self.real_h / self.bev_h, self.real_w / self.bev_w), bev_pos=bev_pos, img_metas=img_metas, prev_bev=prev_bev, ) else: outputs = self.transformer( mlvl_feats, bev_queries, object_query_embeds, self.bev_h, self.bev_w, grid_length=(self.real_h / self.bev_h, self.real_w / self.bev_w), bev_pos=bev_pos, reg_branches=self.reg_branches if self.with_box_refine else None, # noqa:E501 cls_branches=self.cls_branches if self.as_two_stage else None, img_metas=img_metas, prev_bev=prev_bev ) bev_embed, hs, init_reference, inter_references = outputs hs = hs.permute(0, 2, 1, 3) outputs_classes = [] outputs_coords = [] for lvl in range(hs.shape[0]): if lvl == 0: reference = init_reference else: reference = inter_references[lvl - 1] reference = inverse_sigmoid(reference) outputs_class = self.cls_branches[lvl](hs[lvl]) tmp = self.reg_branches[lvl](hs[lvl]) # TODO: check the shape of reference assert reference.shape[-1] == 3 tmp[..., 0:2] += reference[..., 0:2] tmp[..., 0:2] = tmp[..., 0:2].sigmoid() tmp[..., 4:5] += reference[..., 2:3] tmp[..., 4:5] = tmp[..., 4:5].sigmoid() tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0]) tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1]) tmp[..., 4:5] = (tmp[..., 4


 浙公网安备 33010602011771号
浙公网安备 33010602011771号