


chatTTS源码版本地部署踩的坑
打包版直接下载release版本后解压点击app.exe运行即可,首次会下载模型,时间会比较久一些,下载完成后就自动打开网站了,没啥难点,讲一下源码部署,
首先在github下载源码:https://github.com/jianchang512/ChatTTS-ui
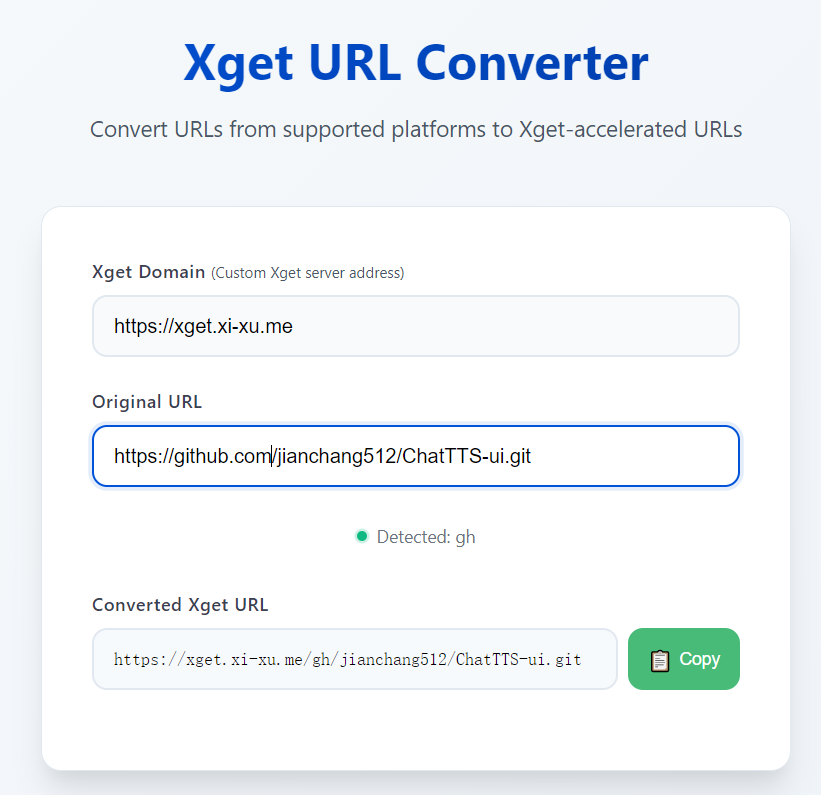
下载慢的可以从镜像站https://github.com/jianchang512/ChatTTS-ui或者xget网站进行下载:https://xuc.xi-xu.me/
下载完成后解压,然后去https://github.com/BtbN/FFmpeg-Builds/releases的最后一页
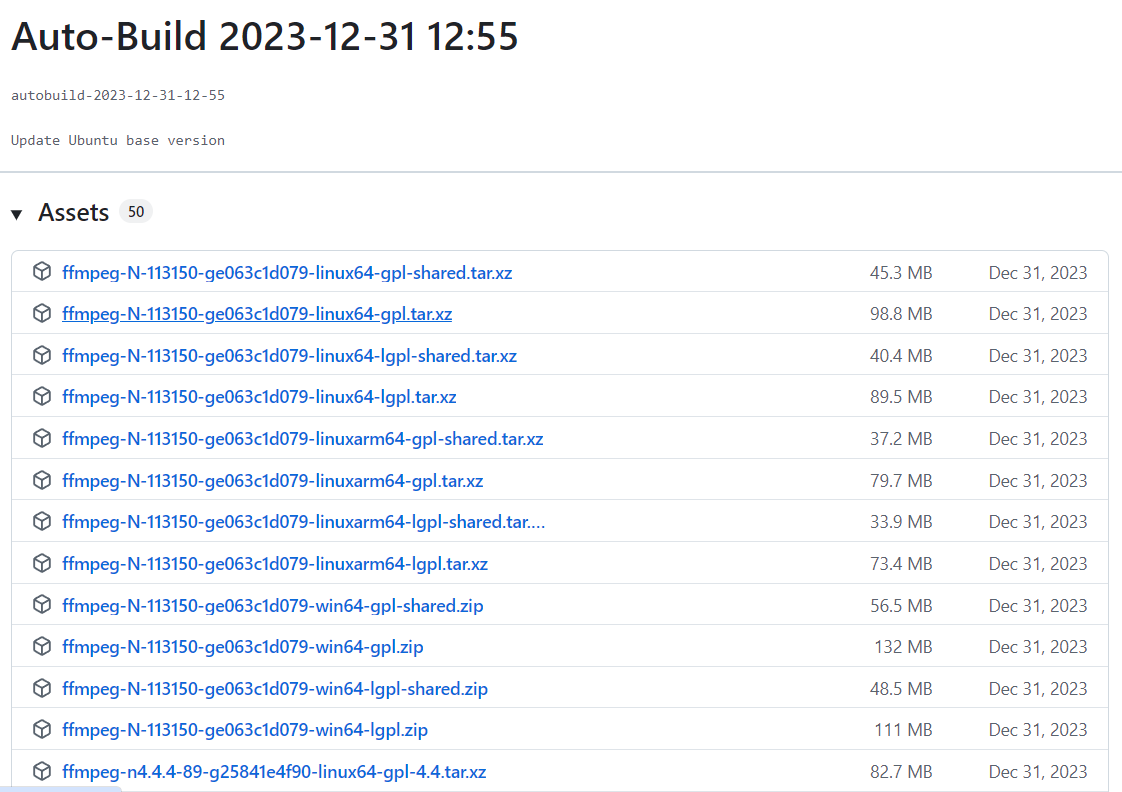
我这里是windows系统,所以下载的是windows版本
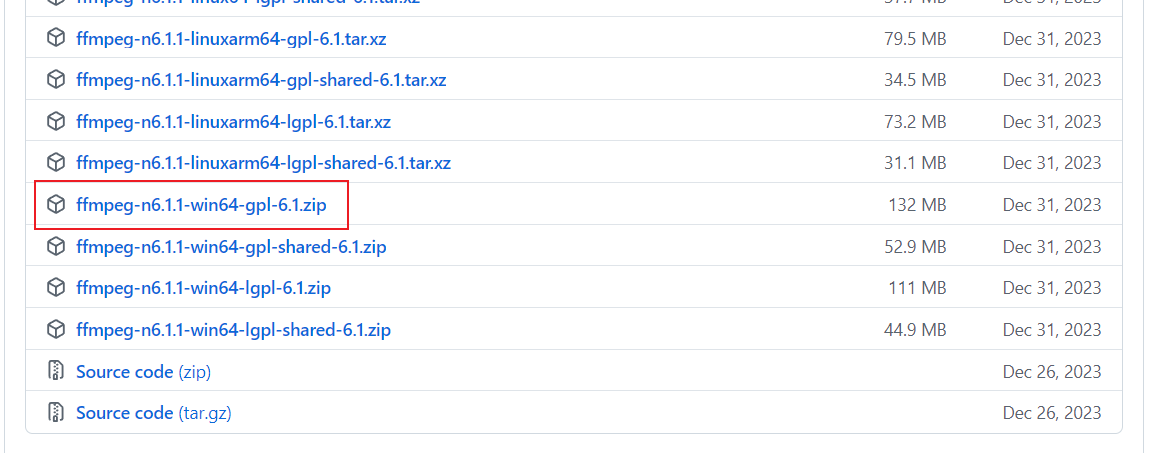
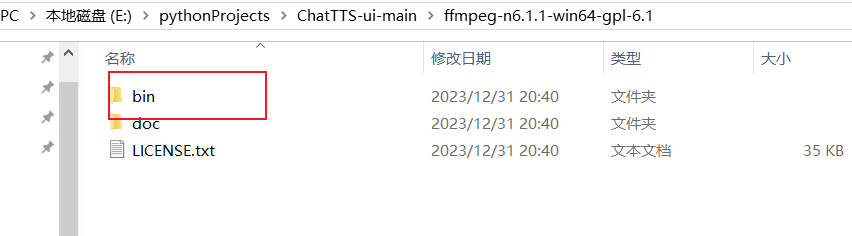
下载完ffmpeg解压,并将对应bin目录设置为环境变量,比如我的位置是E:\pythonProjects\ChatTTS-ui-main\ffmpeg-n6.1.1-win64-gpl-6.1\bin,就配置到path即可,并且将ffmpeg.exe复制到ffmpeg文件夹里
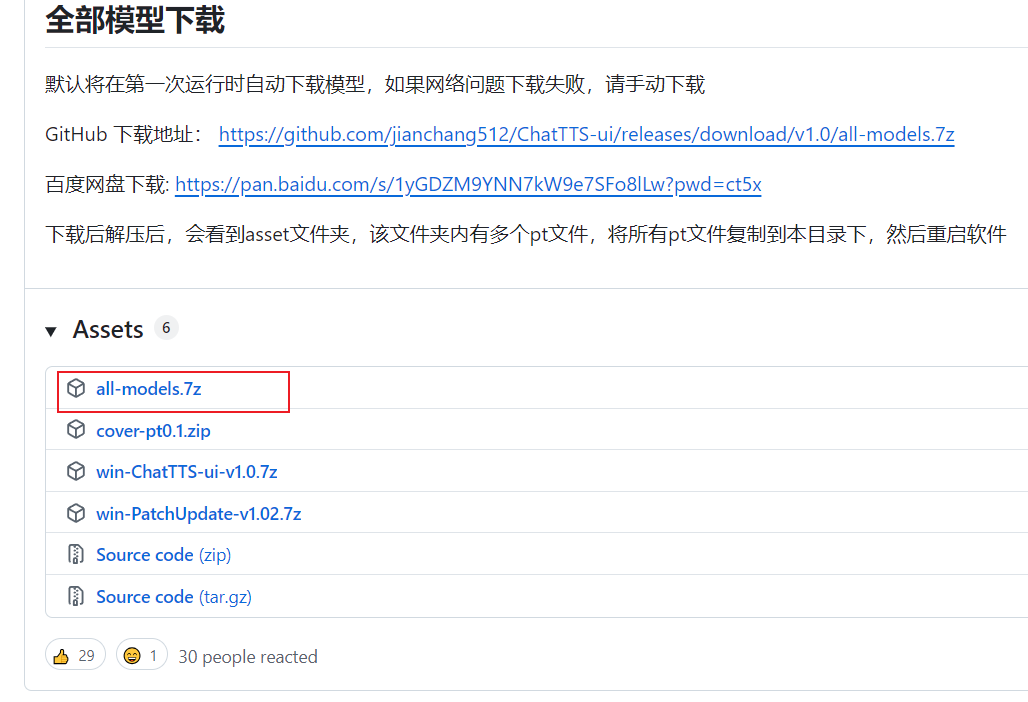
然后模型的话,可以去https://github.home/jianchang512/ChatTTS-ui/releases/tag/v1.0下载all-model.7z
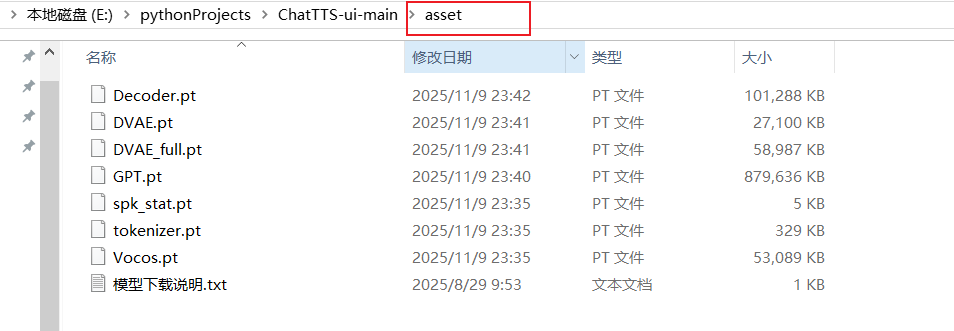
解压到本地chatTTS下对应的asset文件夹里
然后再chatTTS目录进入cmd,python -m venv venv 创建一个虚拟环境(推荐)
执行venv\Scripts\activate进入虚拟环境后,执行pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple下载环境依赖
下载完成后,我这里运行报了错,pytorch没有FILE_LIKE,所以要修改对应源码,一共三处需要修改,core.py有两处,tokenizer.py有一处
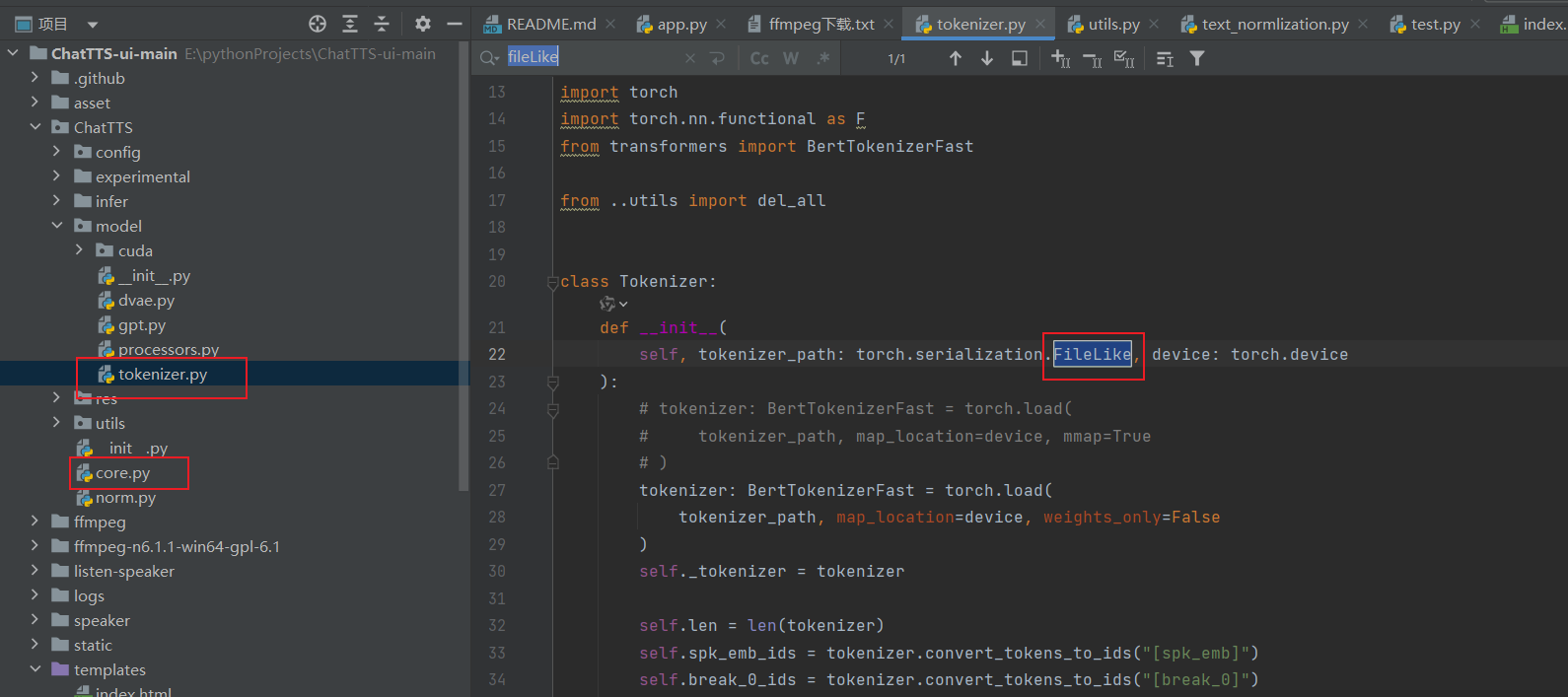
修改完成后就可以通过python app.py运行了
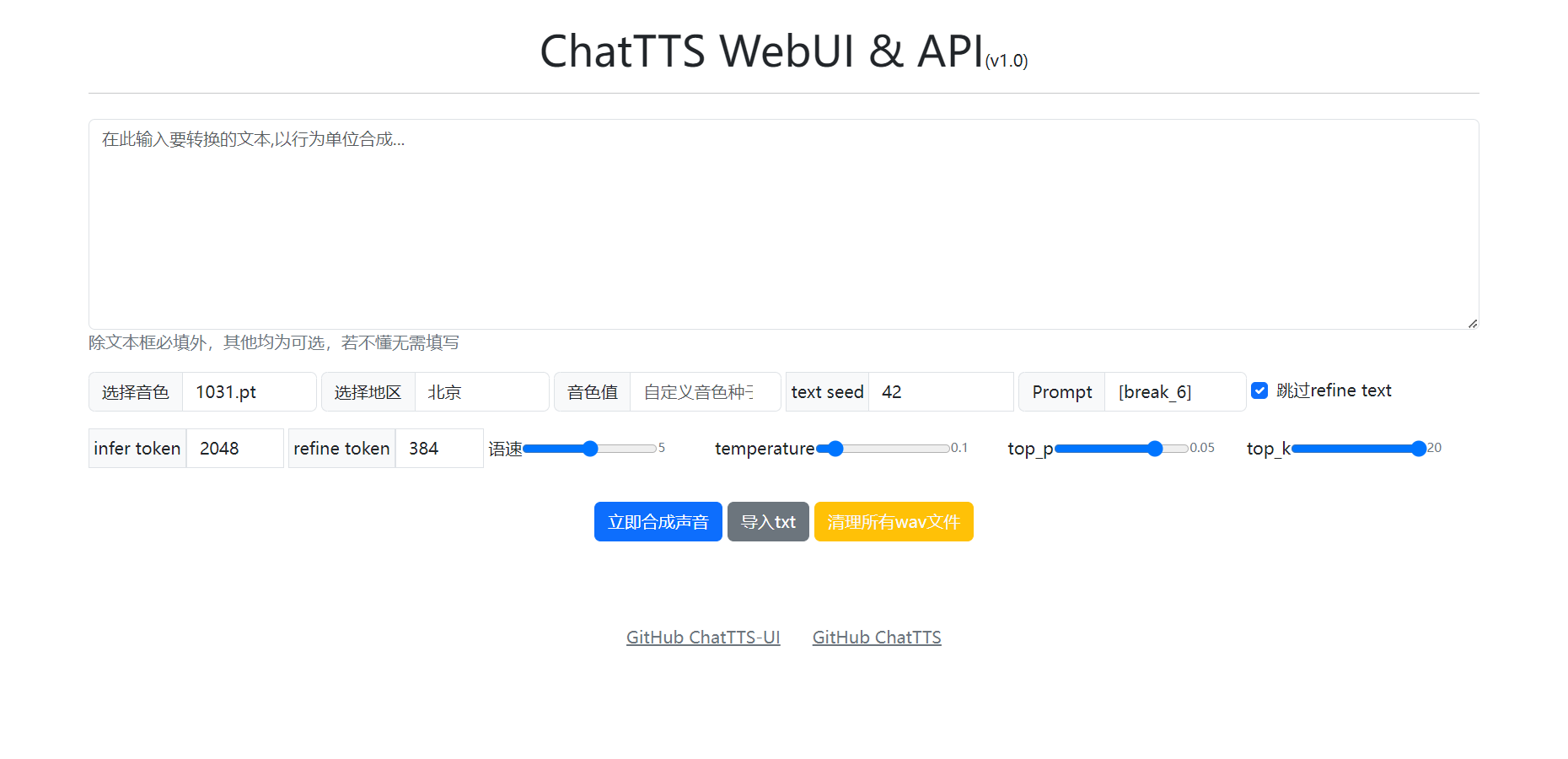
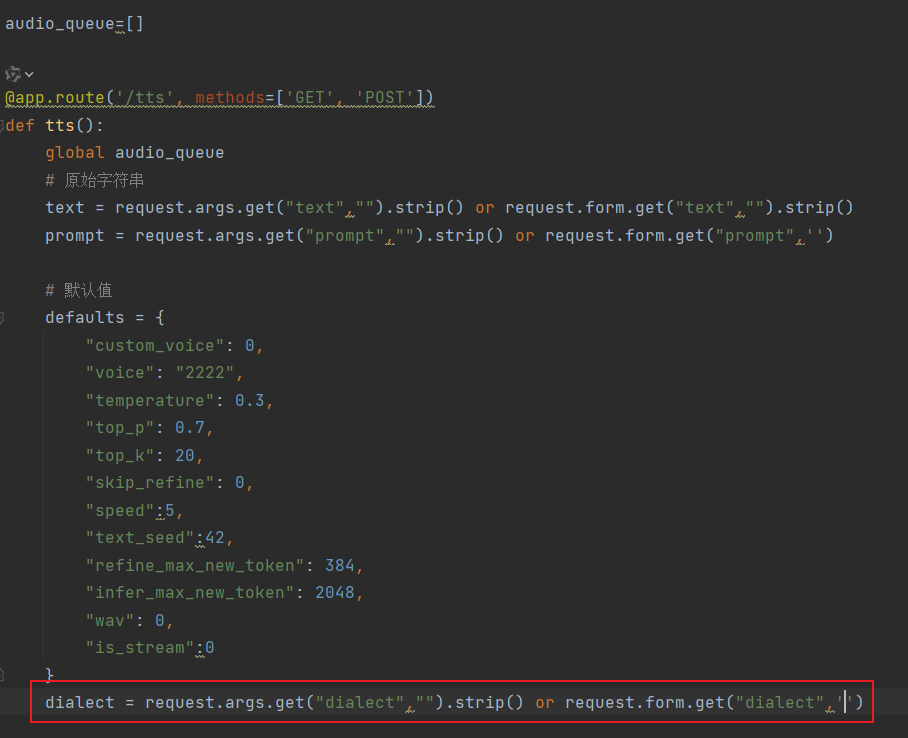
这里我加了个地区,想做方言TTS相关的,目前是没有这个功能的
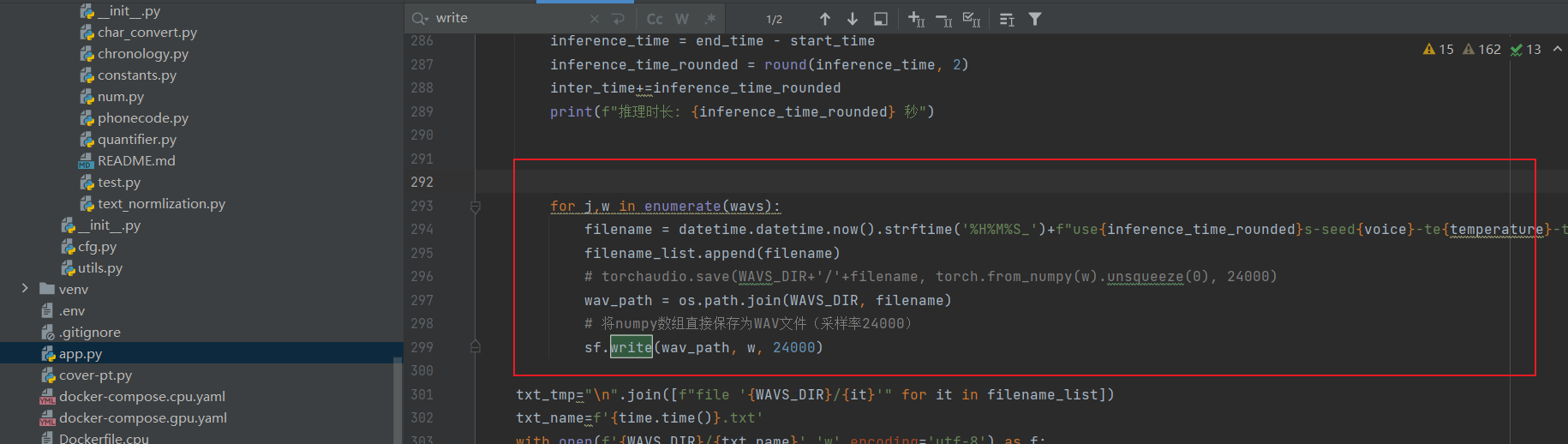
但是在生成音频后会报错,也是pytorch相关的,在app.py的288行处,我直接改成用soundfile去保存音频了,成功运行
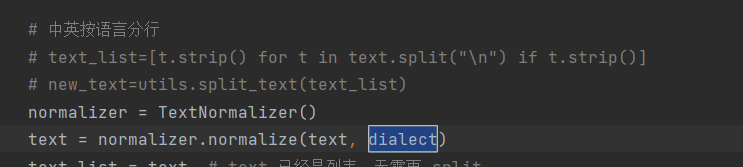
方言的逻辑也是在app.py文件修改,前端传入一个地区传给后端并在调用函数时根据地区判断是否要做方言,目前俺只能做到这个地步了,还是寄希望于开源大佬们吧
题外话:
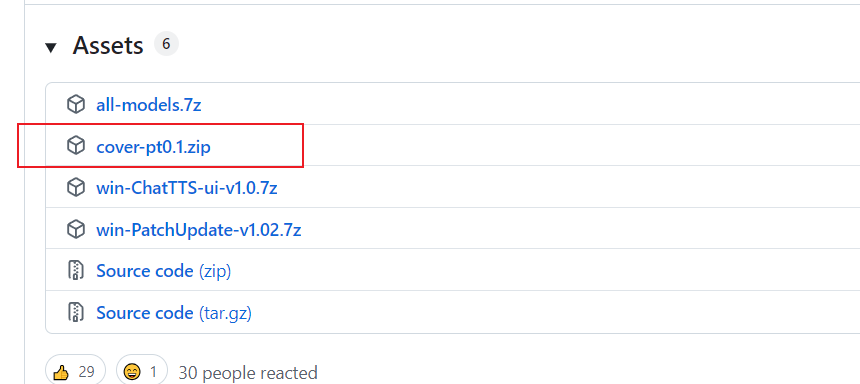
这个软件是用来转换模型的,如图所示,解压后将convert-pt.py放在和app.py同级目录下
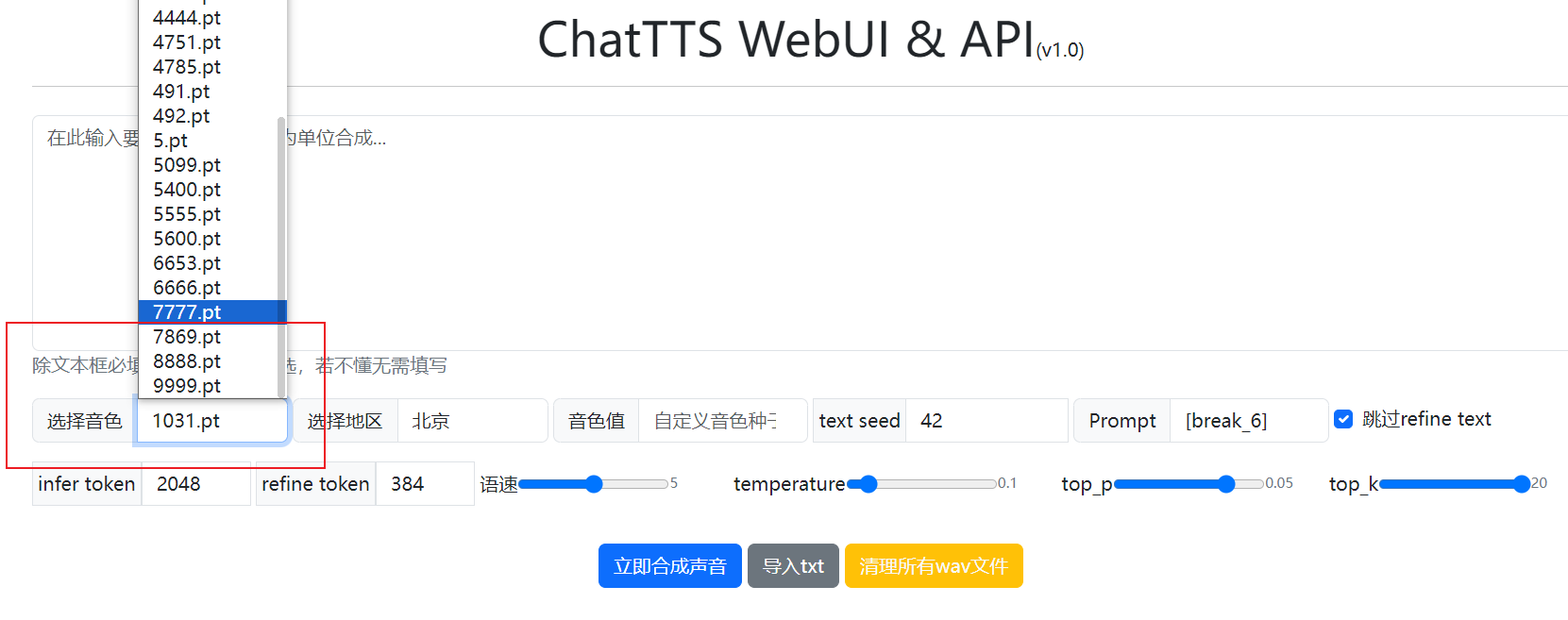
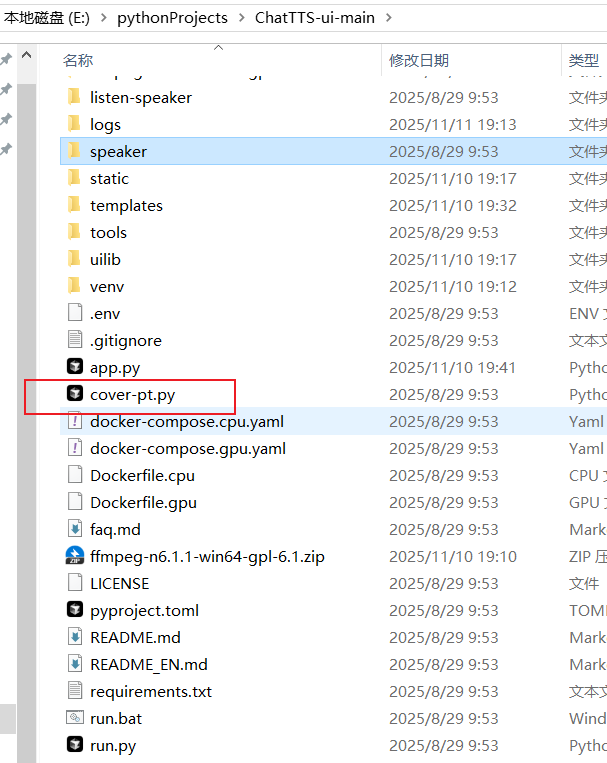
在这个网站https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker/summary可以进行ChatTTS模型的下载
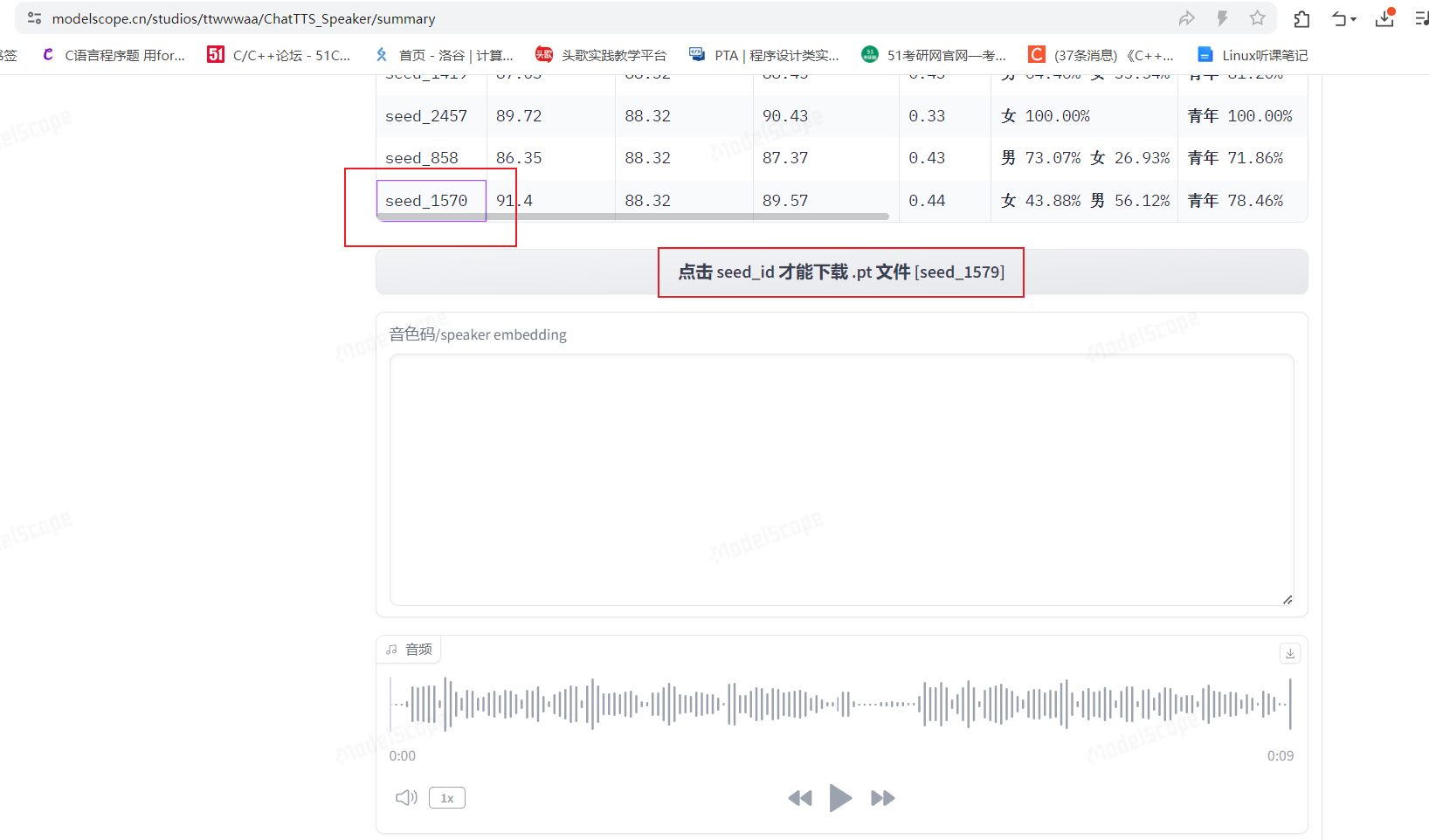
下载完成后放在ChatTTS的speaker目录下
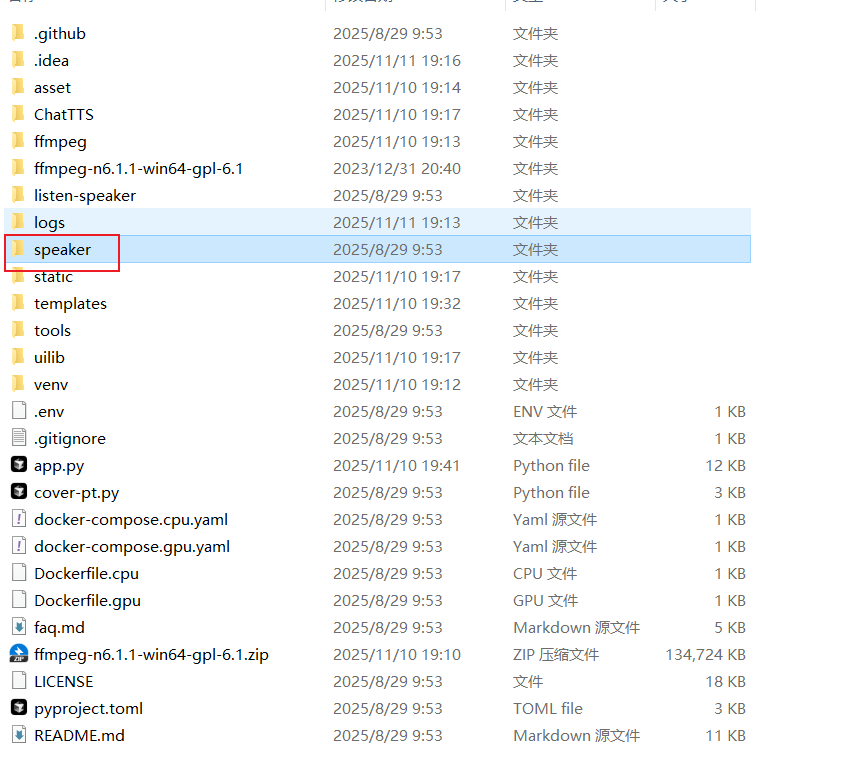
运行python cover-pt.py
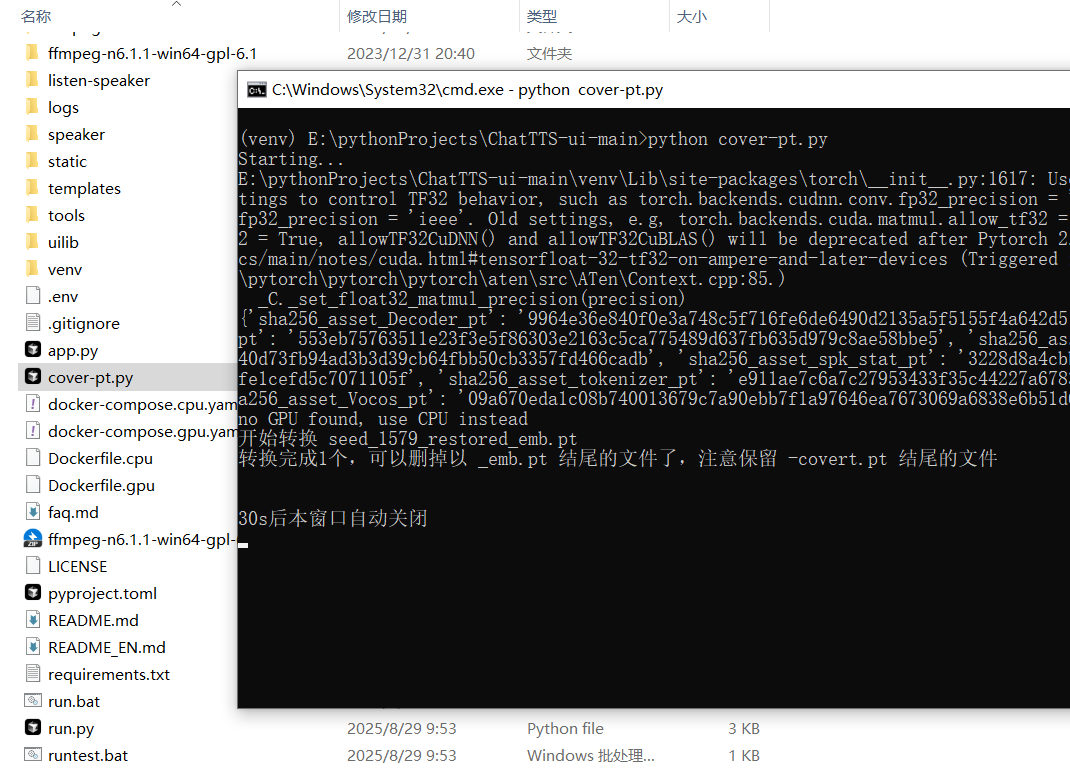
可以看到转化后的模型,并且没有cover后缀的就可以删除了
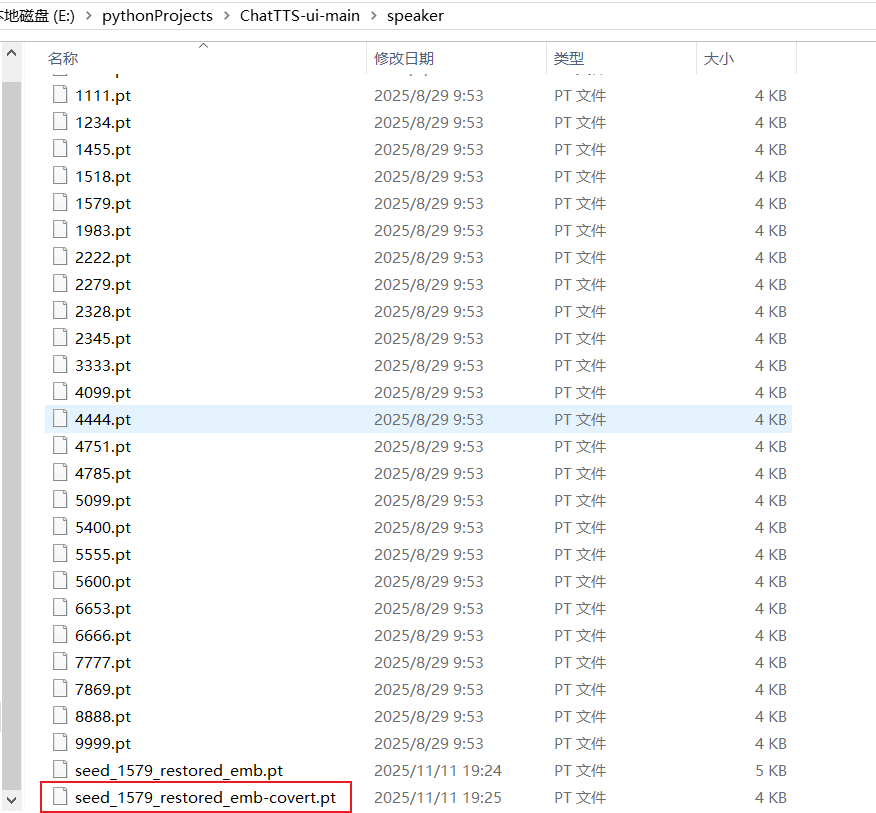
重启app.py就可以用下载的模型了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号