
NJUPT南京邮电大学数据结构实验四(各种内排序算法的实现及性能比较)
仅提供思路,请勿照抄 !!!
一、实验目的和要求
实验目的:
1.掌握各种内排序算法的实现方法。
2.学会分析各种内排序算法的时间复杂度。
实验内容:
1、已知待排序序列以顺序表结构实现,数据元素以及表结构定义如下:
typedef struct entry //数据元素
{
KeyType key; //排序关键字,KeyType应该为可比较类型
DataType data; //data包含数据元素中的其他数据项
};
typedef struct list{ //顺序表
int n; //待排序数据元素数量
EntryD[MaxSize]; //静态数组存储数据元素
}List;
参照程序10.1~10.7,编写算法,分别实现顺序表的简单选择排序、直接插入排序、冒泡排序、快速排序、两路合并排序以及堆排序。
2、编写算法,利用随机函数,在文件中随机产生n个关键字。(关键字定义为整型数据)
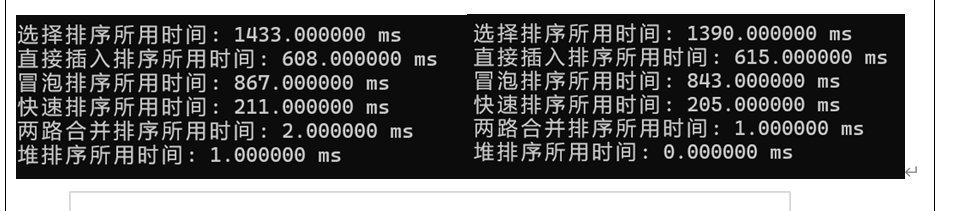
3、编写程序,分别验证在简单选择排序、直接插入排序、冒泡排序、快速排序、两路合并排序以及堆排序,在待排序关键字个数为500、10000、50000、100000时,完成排序所需要的时间。(单位为:毫秒)。
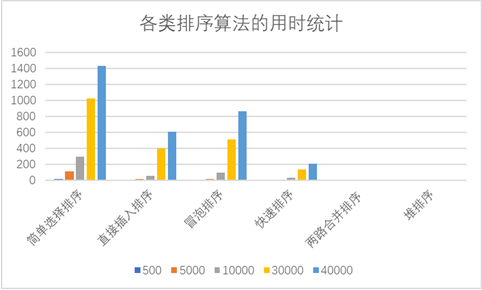
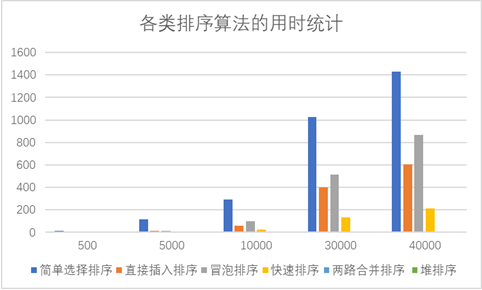
4、将排序结果存放于Excel工作表中,并以图表(簇状柱形图)的方式显示。
二、实验原理及内容
1、算法设计
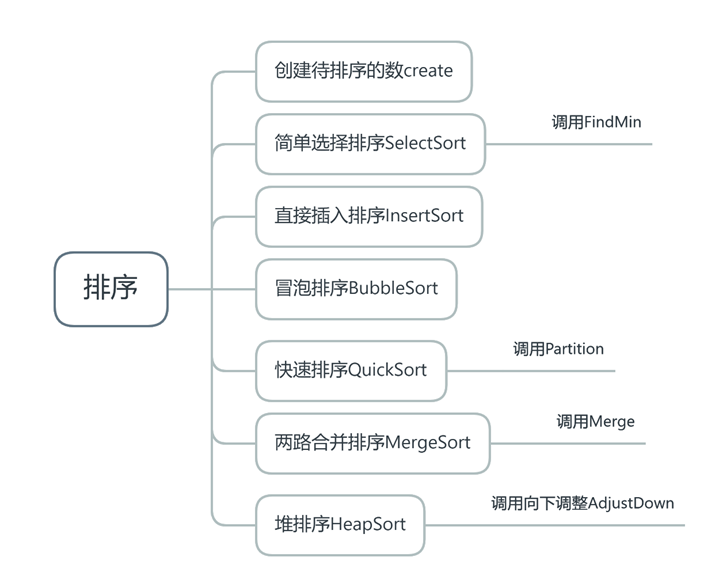
①创建待排序的数create
使用rand()函数生成随机数,并且运用文件相关知识,使用fprintf存入文件file.txt中
②简单选择排序SelectSort
每趟排序调用FindMin找到最小的数据与第一个位置的元素交换
③直接插入排序InsertSort
每趟排序将一个元素插入到已排序好的序列里面,直到所有元素都插完
④冒泡排序BubbleSort
书本的说法:每一趟从前往后不断地比较元素大小,然后交换前面比后面大的元素
通俗的说法:像小鱼吐泡泡一样,大的泡泡会浮上来,第一趟趟排序把最大的元素放到最后面,第二趟趟排序把最大的元素放到倒数第二后面……
⑤快速排序QuickSort
书本的说法:每趟排序调用Partition选择一个分割元素并将比它小的元素放到左边,大的放到右边,然后分别对左边和右边的序列进行同样的操作,递归执行
实质上就是分治的思想,分而治之,一直分割着排序
⑥两路合并排序MergeSort
将一开始的元素每个都看成一个只含有一个元素的序列,调用Merge合并相邻的两个序列,使其有序,重复合并过程直至合并成一个序列
我觉得快速排序和合并排序正好是相反的,一个是分割,一个是合并,一个是最终所有的序列都只含有一个元素,一个是最终只有一个序列
⑦堆排序HeapSort
借助堆数据结构,调用向下调整AdjustDown调整成最大堆,输出堆顶元素,然后继续将剩余元素调整成堆
分析各类排序算法的时间复杂度,空间复杂度和是否稳定
| 排序 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 直接插入排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(logn) | 不稳定 |
| 两路合并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
3、实验结果与结论
n=500时

n=5000时

n=10000时

n=30000时

n=40000时
三、实验小结(包括问题和解决方法、心得体会、意见与建议等)
(一)实验中遇到的主要问题及解决方法
(1)如何随机生成数据?
我查阅了相关资料,发现使用c/c++随机生成数可使用 ①rand() 和 srand()生成伪随机数或②
最终为了便利我采用最常用的①rand()函数生成随机数。
(2)如何统计时间?
我查阅了相关资料,发现统计时间可以①使用<time.h>里的clock()或time()或②使用< windows.h >里的函数GetTickCount()或QueryPerformanceCounter()、QueryPerformanceFrequency()
最终我选择使用使用<time.h>里的clock()来统计时间
(3)如何保证后续的时间统计精准?
我原本打算的方法是每次排序前随机生成一个序列,然后统计排序的时间,但是这样做的问题在于没有控制单一变量,没有保证每次排序前的序列都一样,这样就无法保证实验的精准性。一种解决方案是生成一个序列,然后再复制五个序列,分别进行排序和统计时间,但是这样比较麻烦。于是我选择采用将随机生成出来的序列存入到文件当中,然后每次排序之前读取文件,然后统计时间。
(4)统计时间为0
在程序中,如果写成(double)((end - start) / CLOCKS_PER_SEC)这种形式,最终输出的结果为0.0000,最后我查阅资料发现原因是:end,start,CLOCKS_PER_SEC均为long型变(常)量,若end-start < 1000,则(end - start) / CLOCKS_PER_SEC = 0,再将其强制转换为double型数据,得到0.0000。而如果写成(double)(end - start) / CLOCKS_PER_SEC,先会将end - start转换成double型数据,然后执行"/"操作,则编译器自动将CLOCKS_PER_SEC提升为double型,故而是两个double数据相除能得到正确结果。
(5)程序运行崩溃
原本我打算按照书上的方法分别验证关键字个数为500、10000、50000、100000时所需的时间,但是我发现这样的问题在于当n=50000时程序就崩溃了,所有最大值只能设定为40000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号