NJUPT南京邮电大学数据结构实验二(二叉树的基本操作及哈夫曼编码/译码系统的实现)
仅提供思路,请勿照抄 !!!
一、实验目的:
1、掌握二叉树的二叉链表存储表示及遍历操作实现方法。
2、实现二叉树遍历运算的应用:求二叉树中叶子结点个数、结点总数、二叉树的高度、交换
二叉树的左右子树等。
3、掌握二叉树的应用——哈夫曼编码的实现。
实验内容及要求:
1、已知二叉树二叉链表结点结构定义如下:
typedef struct btnode{
ElemType element;
struct btnode *lChild;
struct btnode *rChild;
}BTNode;
参照程序 5.1~5.4,编写程序,完成二叉树的先序创建、先序遍历、中序遍历、后序遍历等操作。
2、以第1题所示二叉链表为存储结构,编写程序实现求二叉树结点个数、叶子结点个数、二叉树的高度以及交换二叉树所有左右子树的操作。
3、已知哈夫曼树结点结构定义如下:
typedef struct hfmTNode{
ElementType element; //结点的数据域
int w; //结点的权值
struct hfmTNode *lChild; //结点的左孩子指针
struct hfmTNode *rChild; //结点的右孩子指针
}HFMTNode;
编写程序,实现哈夫曼树的创建、哈夫曼编码以及解码的实现。
二、实验原理及内容
1、算法设计
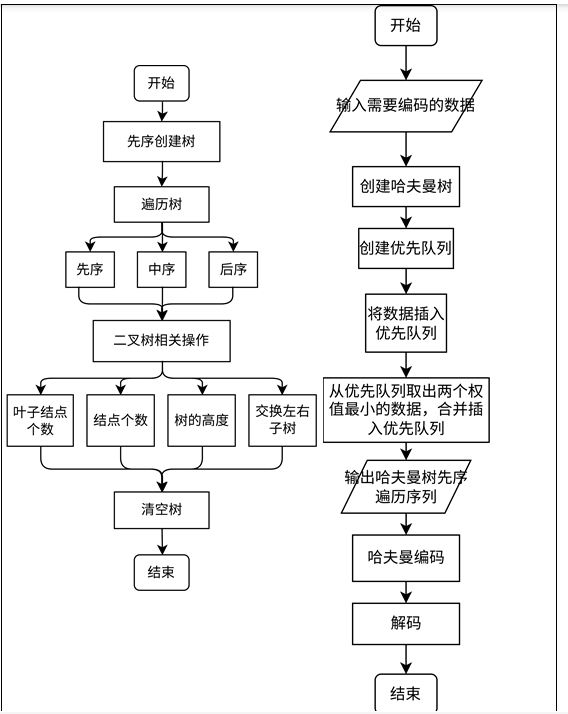
(1)算法整体思路—函数调用关系
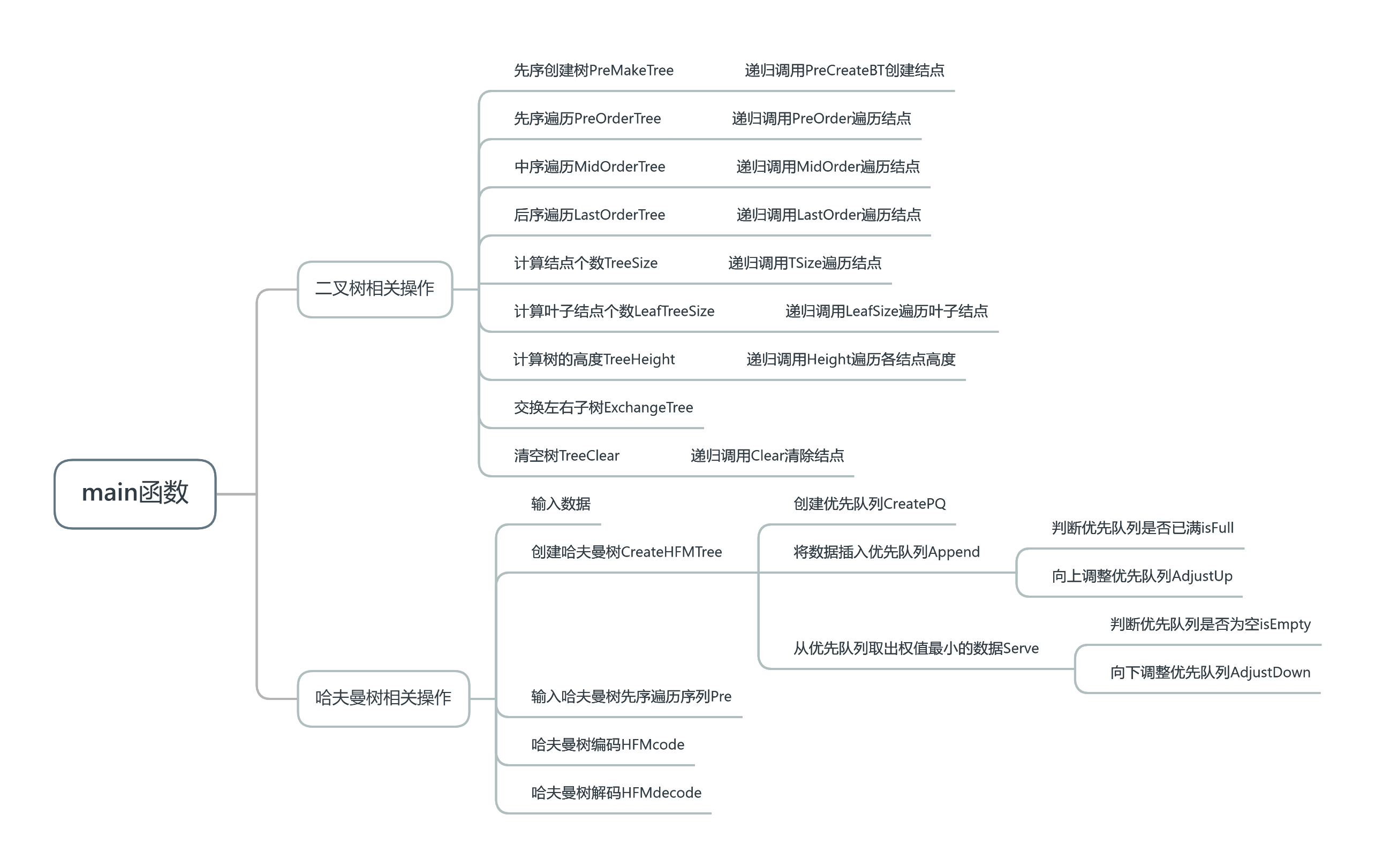
(2)二叉树的相关操作
(3)哈夫曼树编码和解码的相关操作
(2)算法的详细分析及时间复杂度的分析
①二叉树相关操作
基本都是书上的代码 有一点点修改
先序创建树PreMakeTree—递归调用PreCreateBT创建结点——时间复杂度O(n)
先序遍历PreOrderTree—递归调用PreOrder遍历结点——时间复杂度O(n)
中序遍历MidOrderTree—递归调用MidOrder遍历结点——时间复杂度O(n)
后序遍历LastOrderTree—递归调用LastOrder遍历结点——时间复杂度O(n)
计算结点个数TreeSize—递归调用TSize遍历结点——时间复杂度O(n)
计算叶子结点个数LeafTreeSize—递归调用LeafSize遍历叶子结点——时间复杂度O(n)
计算树的高度TreeHeight—递归调用Height遍历各结点高度——时间复杂度O(n)
交换左右子树ExchangeTree——时间复杂度O(n)
清空树TreeClear—递归调用Clear清除结点——时间复杂度O(n)
②哈夫曼树相关操作
输入数据——时间复杂度O(n)
创建哈夫曼树CreateHFMTree——时间复杂度O(n log n)
—创建优先队列CreatePQ——时间复杂度O(n)
—将数据插入优先队列Append——时间复杂度O(log n)
——判断优先队列是否已满isFull——时间复杂度O(1)
——向上调整优先队列AdjustUp时间复杂度O(log n)
—从优先队列取出权值最小的数据Serve——时间复杂度O(log n)
——判断优先队列是否为空isEmpty——时间复杂度O(1)
——向下调整优先队列AdjustDown——时间复杂度O(log n)
输出哈夫曼树先序遍历序列Pre——时间复杂度O(n)
哈夫曼编码HFMcode——时间复杂度O(n)
哈夫曼解码HFMdecode——时间复杂度O(m)
2、实验结果与结论
(1)测试数据及运行结果

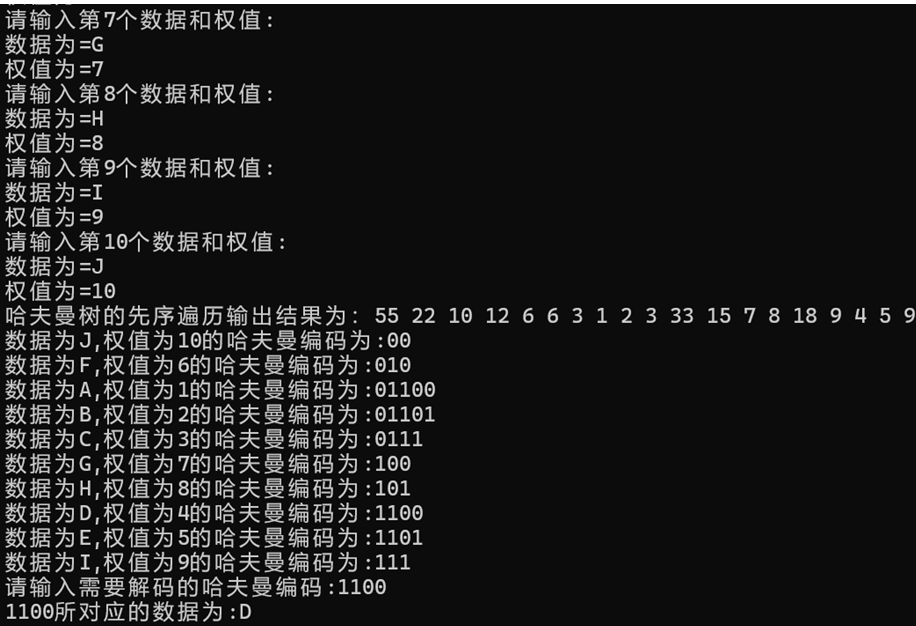
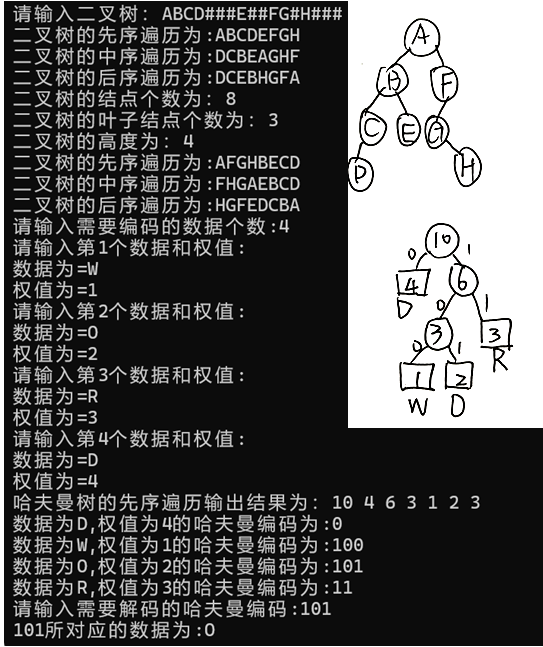
(2)实验相关结论
哈夫曼树的构建过程中使用了优先权队列,建堆,向上调整,向下调整相关算法,最终整个建树的时间复杂度为O(n log n)
三、实验小结(包括问题和解决方法、心得体会、意见与建议等)
实验中遇到的主要问题及解决方法
(1)二叉树相关操作
代码主要来源于书上的代码,其中有函数的返回值是bool类型需要加上头文件<stdbool.h>,或者改成int类型,否则会报错,书上介绍了两种建树方法,一种是对每一个结点给它值,左子树和右子树来建树,另一种是先序建树方法,更加方便
(2)哈夫曼树构建、编码相关操作
优先权代码主要参考的是书上的,但是这一块总是报错,要么就是构建错误:
①哈夫曼树的构建
在构建哈夫曼树CreateHFMTree的函数内,将新创建的二叉树插入优先权队列的Append函数里直接写PQ->elements[PQ->n]=x;的话会把优先队列里的所有数都全部替换为新插入的数,而改成PQ->elements[PQ->n]->element=x->element;PQ->elements[PQ->n]->w=x->w;PQ->elements[PQ->n]->lChild=x->lChild; PQ->elements[PQ->n]->rChild=x->rChild;之后就可以正常插入了,可能是因为修改前队列里的所有元素都存放的是x的地址,修改之后只存放了值。同理,在取出优先级最高的元素,利用参数x返回,并在优先权队列中删除该元素的Serve函数里,不能直接写PQ->elements[0]= PQ->elements[PQ->n-1];而是也要把elements里的每个元素对应的数据域element,权值w,左孩子lchild,右孩子rchild都分别赋值。
②哈夫曼编码
我使用的编码方法是在结构体定义时就将data变量(int数据类型)添加到struct hfmTNode哈夫曼结点里面,然后先序递归遍历哈夫曼树,左孩子的编码是双亲结点的10倍,右孩子的编码是双亲结点的10倍再加1,遍历完哈夫曼树即编码好了每一个叶子结点。但是这样有一个问题,就是因为我是用int去存储编码,所以无法区分00和000,001和1,010和10……以此类推,在int里面它们是一样的,都是0,1,10……,因为我采用了将0替换为8的方法,于是编码变成了88和888,881和1,818和18……这样存储到结点里面,然后在最终输出的时候再把8替换为0即可。
③哈夫曼解码
解码没什么问题,将输入的字符串存储到char数组里面,然后逐个读取依次遍历哈夫曼树即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号