
03 2023 档案
摘要://快速排序 void quick_sort(int q[], int l, int r) { if (l >= r) return; int i = l - 1, j = r + 1, x = q[l + r >> 1]; while (i < j) { do i ++ ; while (q[i]
阅读全文
摘要: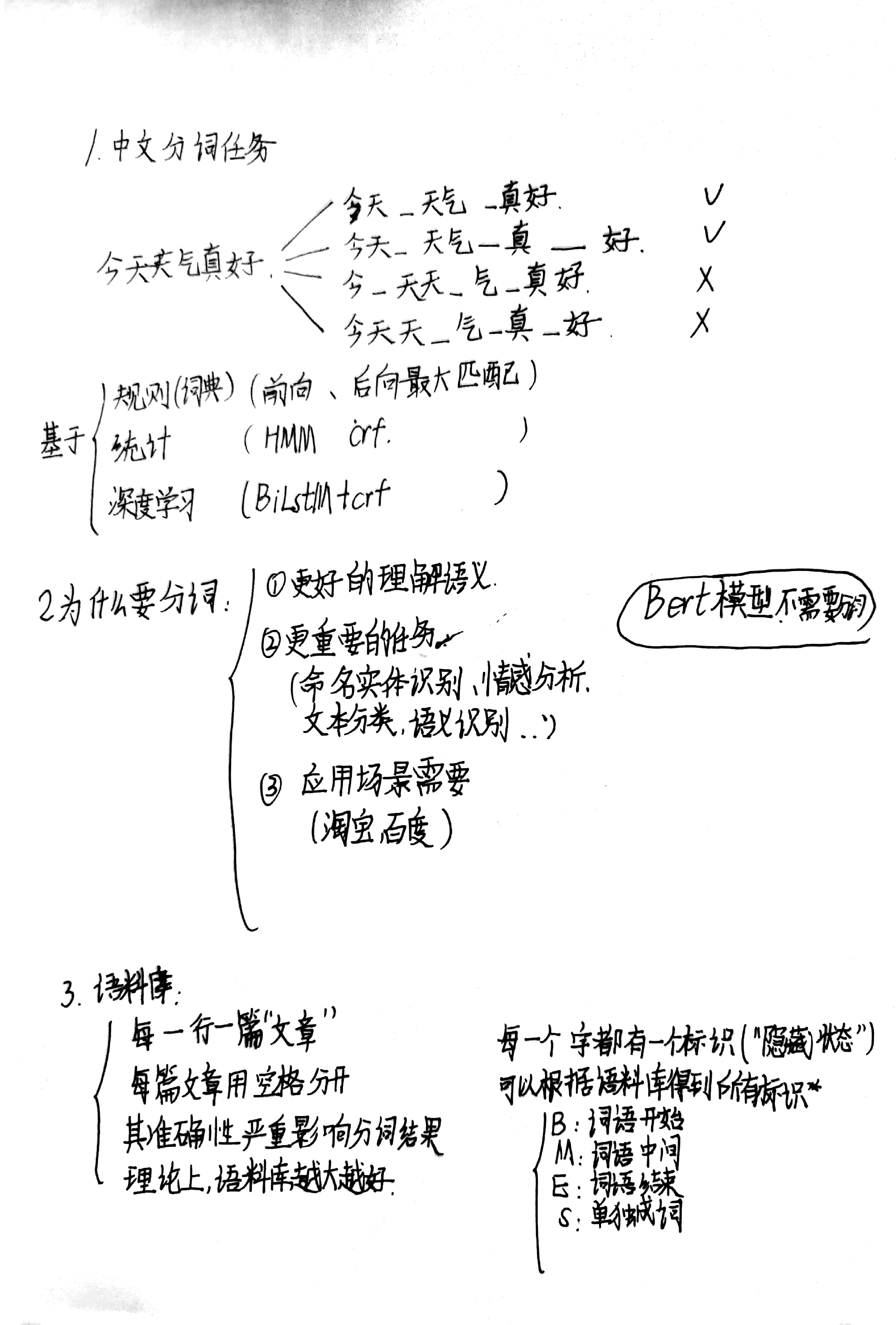 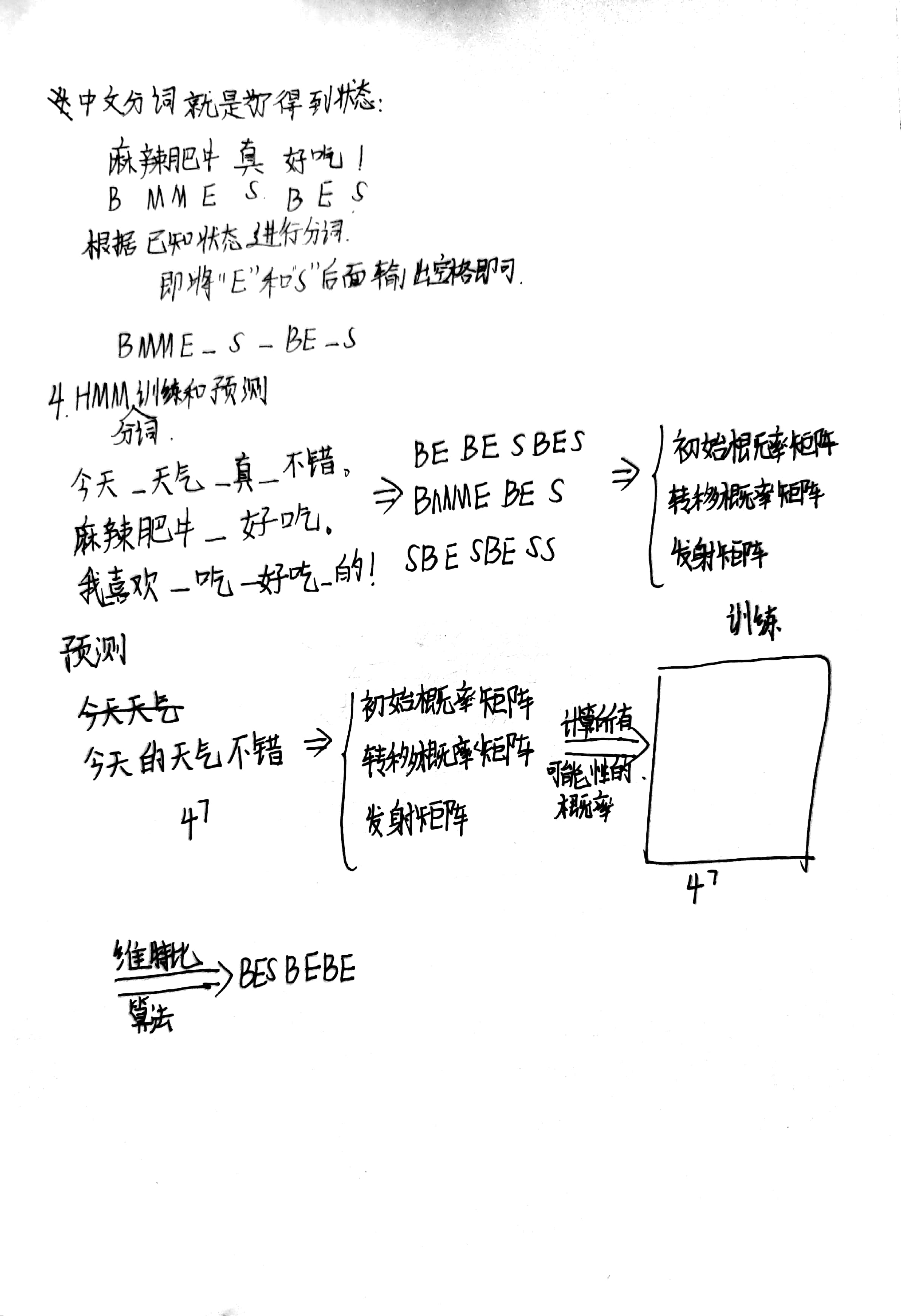 : ''' 初始化逻辑回归模型 θ向量 '
阅读全文
摘要:1.使用WSL的优点: (1)与在虚拟机下使用 Linux 相比,WSL 占用资源更少,更加流畅 (2)WSL 可以对 Windows 文件系统下的文件直接进行读写,文件传输更方便; (3)剪贴板互通,可以直接在 Windows 下其它地方复制文本内容,粘贴到 WSL; 2.开启WSL支持: 使用管
阅读全文
摘要:import numpy as np example_dict = {(1, 0): 1, (1, 1): 2, (2, 0): 3, (2, 1): 4} np.save('filename', example_dict) loaded_dict = np.load('filename.npy',
阅读全文
摘要:1、 基于训练语料,训练一个基于字的Bigram语言模型。当用户输入某个字序列,程序可以自动推荐该序列的后一个字(依次列出概率最大的5个可能字选项),根据提示用户选择某个字后,程序可以继续推荐下一个字的列表。例如:输入“长江大”,程序猜测下一个可能的字为“桥”、“河”、“学”、“道”等。 要求:(1
阅读全文
摘要:1.概要 在这篇文章中,将探讨一种比较两个概率分布的方法,称为Kullback-Leibler散度(通常简称为KL散度)。通常在概率和统计中,我们会用更简单的近似分布来代替观察到的数据或复杂的分布。KL散度帮助我们衡量在选择近似值时损失了多少信息。 2.公式 KL散度起源于信息论。信息论的主要目标是
阅读全文
摘要:实现方法 神经元(Neurons):它是神经网络的基本单元。神经元先获得输入,然后执行某些数学运算后,再产生一个输出。比如一个2输入神经元的例子:
阅读全文
摘要:注意力机制是一种在深度学习中常用的机制,可以在处理变长输入序列时,让模型更加关注与当前任务相关的信息。下面是注意力机制的数学证明。 假设我们有一个输入序列$x = (x_1, x_2, ..., x_T)$,其中每个$x_t$都是一个向量,$y$是输出序列。我们需要在每个时间步$t$选择适当的$x_
阅读全文
摘要:循环神经网络(RNN)是一种特殊类型的神经网络,它在输入之间保持一种状态,并使用该状态来处理序列数据。下面是RNN的数学推导。 假设我们有一个输入序列$x = (x_1, x_2, ..., x_T)$,其中每个$x_t$都是一个向量,$y$是输出序列,$h_t$是RNN在处理$x_t$时的隐藏状态
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号