mysql 索引原理—索引的数据结构
MySQL为什么选择B+Tree索引
快速查找的数据类型大致有hash表,二叉树,平衡二叉树,B-Tree,B+Tree。
hash表 ![]()
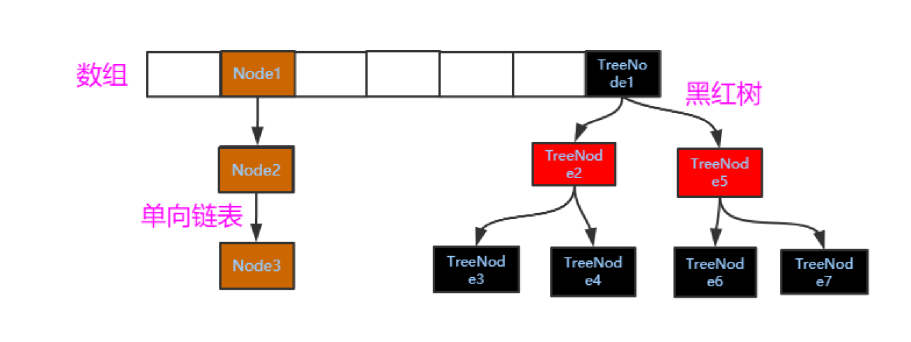
hash表查找方式是基于数据的Key的hashcode得到数组下标,如果存储的为链表,则遍历链表进行value比较;如果存储的为红黑树,则用二分查找法。
所以hash表在数量量不大,并且进行等值查找的时候效率较高,但不能范围查询。
二叉树 ![]()
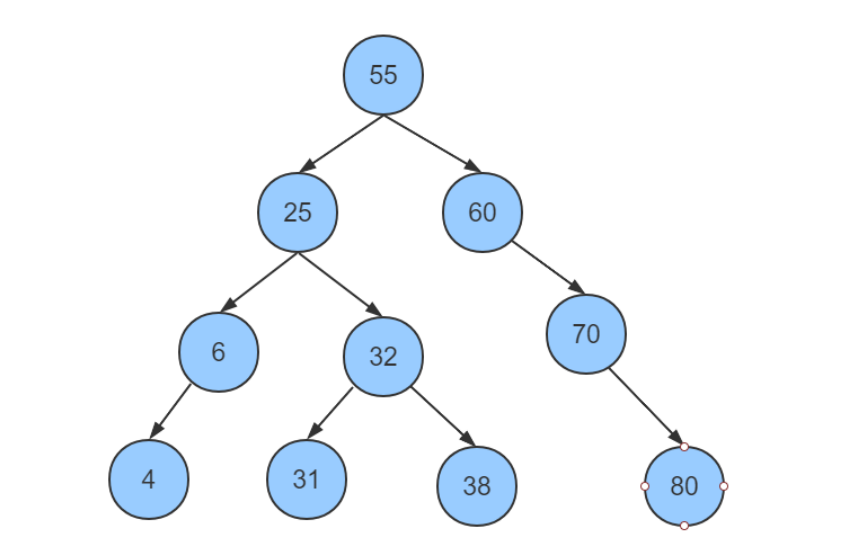
二叉树数据的组织方式是左小右大:即当前存入的数据比当前节点的关键字小,递归左子节点;若当前存入数据比当前节点的关键字大.递归右子节点。
如果我们用自增序列作为主键建立索引,则会形成
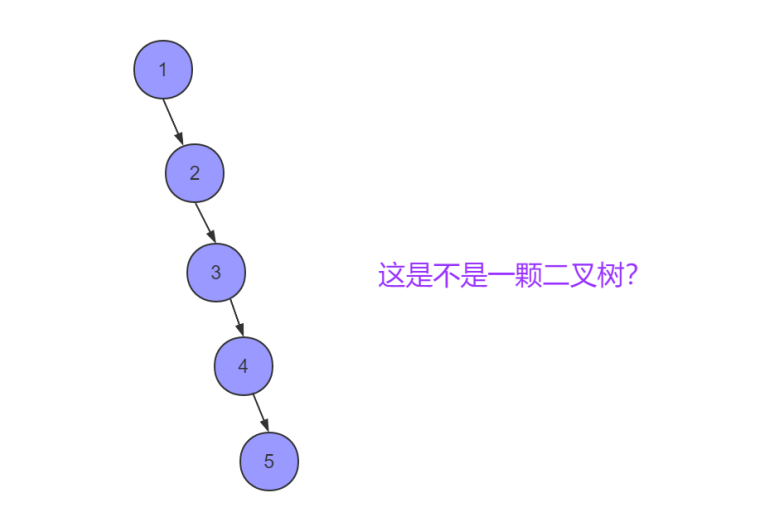
所以就衍生平衡二叉树
平衡二叉树
平衡二叉树为了保证树的平衡性,在数据的插入和删除的过程中,会进行一系列的计算.将树进行左/右旋转满足树的平衡性
但是平衡二叉树在数量大的时候树高会很高,再查询末端节点会递归多次才能找到数据,并且每个阶段只存一个数据会有多次的IO操作才能找到数据。
操作系统与磁盘的交互是采用页为基本的交换单位.一页数据大小是4KB,再加上操作系统的预读能力[空间局部性原理],一次磁盘的IO交互将会带来N页的数据返回,而一个节点只要一个数据,完全没法填满,一次IO只能有少量的有效数据
B-Tree
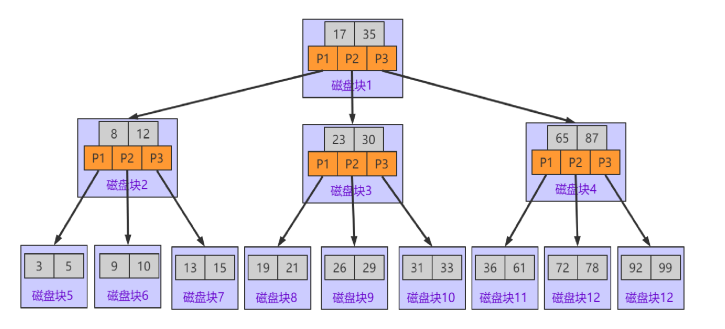
B-Tree的优势
1.将磁盘IO的低效操作通过内存中数据比较进行替换
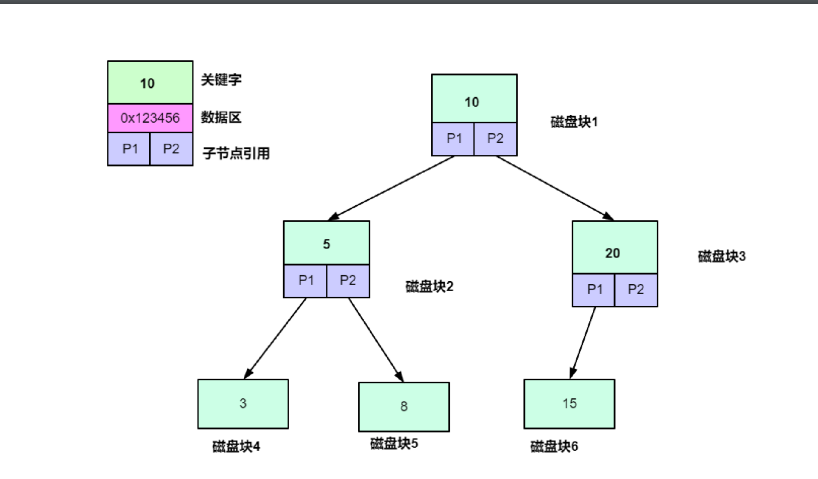
在二叉树中,我们一次只能加载一个关键字进行匹配.但是在B-树,我们一次可以加载N个关键字,若我们将磁盘块(节点)的空间大小固定(MySQL中定义为16KB).磁盘块能存储的关键字个数就会与单个关键字内容占用的空间相关.基于预读和操作系统磁盘交互特性.我们磁盘IO一次加载的内容正好都是我们需要比对的内容.讲内容的多次IO加载转换成在内存中进行数据的比较
2.合理的降低树的高度,减少IO的次数
假如一个节点则可以放入1000个有效数据,二层则有10011000,三层就要(10011000+1)*1000。则B-tree只需要三层就能存储超过10亿的数据。
B+Tree
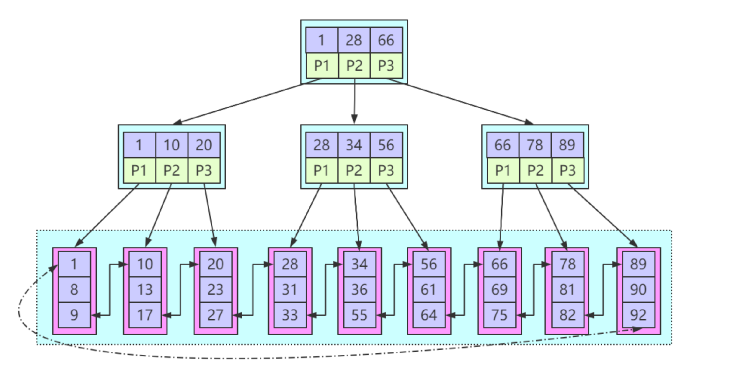
B+树是基于B-树结构的加强版树形结构.
B-树拥有的特性B+树都拥有.
B+树的数据匹对规则采用闭合区间的方式
B+树的非叶子节点上不保存关键字对应的数据区
B+树的叶子节点上保存数据区
在叶子节点上的数据产生形成首尾相连的链式结构带来更高效的数据排序
基于以上你的结构特点B+树相较于B-树又哪些优势呢?
B-树拥有的特性,B+树都拥有
B+树拥有更强劲的磁盘IO能力.
在非叶子节点不存在数据区,将大大降低节点的空间占用.能存储更多的关键字.一次磁盘IO带回来的有效数据将更多更精准
B+树拥有更好的数据排序能力
这是B+树的天然优势,在最末尾的叶子节点这一层天然即有序的链式结构
基于B+树的扫表能力更强
在B+树的数据结构中,若需要扫表,只需要扫描最末尾的叶子节点即可.
基于B+树结构的索引的查询,更趋于稳定
在B-树结构中,我们发现,我们的关键字在某一个节点进行匹对成功就完成数据区内容的返回.但是在B+树结构中,我们采用的是闭合区间的比对方式即数据的最终加载一定会在叶子节点上.在B-树结构中,有可能针对一张表的查询,有些数据需要3次IO.有些只需要1次IO.前后的查询效率跌跌宕宕不稳定.但是在B+树结构中一定恒定的IO次数,带来更稳定的查询效率.基于以上的对比和总结,MySQL最终选择了B+Tree作为了索引的数据结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号