Lora:大模型轻量级微调
技术背景
随着ChatGPT的爆火,很多公司都退出了自己的开源大模型,但是对于一些小公司来说,训练一个ChatGPT级别的大模型成本太过高昂。
所以需要一个低成本,可以在自己的数据集上低成本进行微调大模型的技术。
目前主流的方法包括
- 在2019年Houlsby N等人推出的Adapter Tuning ---增加模型难度,引入额外的推理延迟
- 2021年微软提出的LORA ---比较合适
- 斯坦福提出的Prefix-tuning ---难于训练,切预留个Prompt的序列基站了下游任务的输入序列空间,影响模型性能。
- 谷歌提出的Prompt Tuning ---很容易导致旧知识以往,微调之后的模型,在之前的任务上表型变差。
- 2022年清华提出的Ptuning V2
LoRA(Low Rank Adaptive 低秩自适应)允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持训练训练的权重不变。
LoRA介绍
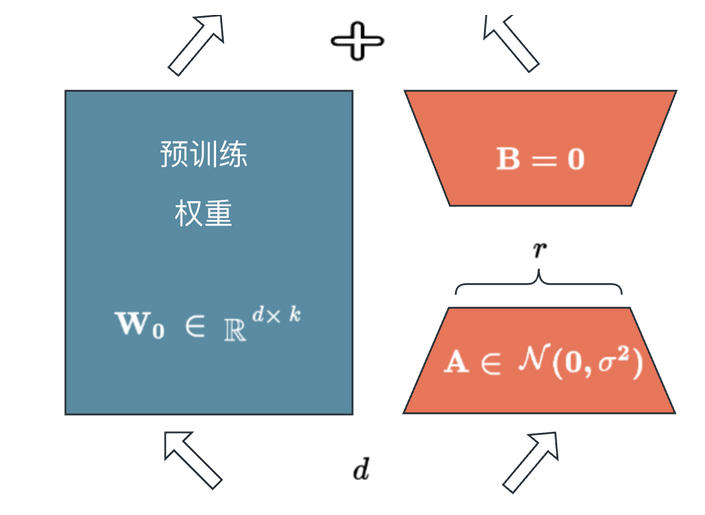
左侧的预训练权重是需要微调的模型的参数,这个是[d x k]维度的参数,参数量有d x k个,对于大一些的模型,这些参数量通常是几十万几百万级别的。
现在不训练左侧的预训练权重,使用A B 两个矩阵,其中W = A @ B,@是矩阵乘法,也就是将W分解成了两个矩阵的乘积。其中AB维度为A[d x r] (初始化为随机值), B[r x k] (初始化为0),r为超参数。
通过训练AB两个矩阵,减少参数量(参数量为(d x r + r x k) << (d x k)),最终将训练好的AB矩阵相乘为w0(还原W矩阵)w0和W相加,最终实现了对原模型的微调。
总结:LoRA & QLoRA(量化LoRA,减少AB矩阵参数精度)
LoRA使用场景是模型的高效微调
- 使用LorA高效地模型微调, 重点是保持参数尺寸最小化
- 使用PEFT(Parameter Effective tuning)库来使用LoRA,避免复杂的编码需求
- 将LoRA使用扩展到所有线性层,增强整体模型的能力。
- 保持偏置和层归一化可训练,因为他们对模型的适应性至关重要,并且不寻常低秩适应。
- 应用量化低秩适应(QLoRA)以介绍GPU现存并训练模型,从而能够训练更大的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号