数据散布度量(上)
对于连续数据,往往需要采用一种度量来描述这个数据的弥散程度。
给定属性x,它具有m个值
\(\{x_1,x_2,...,x_m\}\)
关于散布度量就有以下这些
| 散布度量名称—————— | 散布度量定义————————————————————————— |
|---|---|
| 极差 range |
\(range(x)=max(x)-min(x)\) |
| 方差 variance |
\(variance(x)=s^2_x=\frac{1}{m-1} \sum_{i=1}^{m} (x_i- \overline{x})^2\) |
| 标准差 standard deviation |
\(std(x)=s_x=\sqrt{\frac{1}{m-1} \sum_{i=1}^{m} (x_i- \overline{x})^2}\) |
| 变异系数 coefficient of variation |
\(cv(x)=\frac{std(x)}{avg(x)}\) |
| 绝对平均偏差 absolute average deviation AAD |
\(AAD(x)=\frac{1}{m} \sum_{i=1}^{m} \mid x_i-\overline{x}\mid\) |
| 中位数绝对偏差 median absolute deviation MAD |
\(MAD(x)=median(\{\mid x_1-\overline{x}\mid,...,\mid x_m-\overline{x}\mid\})\) or \(MAD(x)=median(\{\mid x_1-median(x)\mid,...,\mid x_m-median(x)\mid\})\) |
| 四分位数极差 interquartile range IQR |
\(IQR(x)=x_{75\%}-x_{25\%}\) |
其中,极差跟方差是较为简单的度量,简单粗暴,描述的是整个值集的散布情况。
但是这两种度量不好衡量,比如说你发现了今年学生的身高极差是2.0,或者方差是2.0,于是你告诉别人,别人一脸懵逼,因为不知道这是散布还是集中。
标准差一定程度上解决了这个问题,因为标准差与x具有相同的单位,你可以跟别人说,今年学生的身高标准差是2.0cm。
其实别人还是会一脸懵逼,因为仅仅知道了身高标准差是2.0cm,别人还是不会有一个大概的印象。
归根到底,是因为不知道2.0cm的标准差意味着什么,是很集中,还是参差不齐?
变异系数在一定程度上又解决了这个问题,拿标准差与均值比一比,得到一个无量纲的值,就大概知道偏差的程度占均值的多少了,然后就可以开始比较萝莉与JK女生不同两种样本的2.0cm标准差的区别。
上面说道的5个度量,都都依赖于整个值集,所以不可避免的会受到离群值的影响。
如果可以预见到值集存在比较多的离群值,就需要用比值集散布更加稳健的估计。ADD、MAD、IQR就是这样的度量。
这些度量,都可以在《数据挖掘导论》中看到详细定义。
特别的《数据挖掘导论》里面对于中位数绝对偏差MAD的定义是“离均差绝对值的中位数”,对于大部分人理解的MAD“离中位数差绝对值的中位数”不太一样。
对于主流说法的MAD(即后者),各种资料中都提及可以用来代替标准差,所以这里采用后者表述的MAD。
毫无意外地,看到这里,你应该像我一样依然是一脸懵逼!
因为《数据挖掘导论》里面没有具体说这些度量会受什么影响?在什么目的下、什么数据集下适合用什么样的度量?
作为一个学渣,我决定自己模拟一些数据集来测试一下。。。
首先自定义一个函数measure,给定一维数组作为数据集,输出上面所提到的所有度量:
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
#输出七种度量的函数
def measure(x):
range_x=max(x)-min(x) #极差
variance_x=1/(m-1)*sum((x-x.mean())**2) #方差
std_x=variance_x**0.5 #标准差
cv_x=std_x/x.mean() #变异系数
aad_x=(abs(x-x.mean())).mean() #绝对平均偏差
mad_x=np.percentile(abs(x-x.mean()),0.5) #中位数绝对偏差
iqr_x=np.percentile(x,0.75)-np.percentile(x,0.25) #四分位数极差
return range_x,std_x,cv_x,aad_x,mad_x,iqr_x
一、平均分布的数据集
设一个数据集,这个数据集是均值为mean,波动幅度为scale的随机分布的数据集,数据集的大小为m。 接下来将模拟一下数据集的各种特征,然后看看各个度量有都有什么性质。 由于方差是标准差的平方,而且实际应用中标准差使用的更多,所以这里就不展示方差,大家看着图可以自行脑补。measure_list=['极差','标准差','变异系数','AAD','MAD','IQR']
#生成画布与坐标轴
fig,axs=plt.subplots(nrows=2,ncols=2)
fig.set_size_inches((22,12))
#各参数说明
ax=axs[0,0]
#确定参数
m=50 #数据集大小
mean=0 #模拟均值
scale=1 #模拟广度
x=(np.random.random(m)+mean*scale) #随机数据集
ax.scatter(range(50),x)
ax.set_ylim(bottom=-0.5,top=1.5)
ax.plot([-5,55],[0.5,0.5],color='red',linestyle='--',label='mean')
ax.plot([-5,55],[1,1],color='green',linestyle='--',label='mean+scale')
ax.plot([-5,55],[0,0],color='orange',linestyle='--',label='mean-scale')
ax.text(x=-5,y=0.52,s='mean',color='red',size=16)
ax.text(x=-5,y=1.02,s='mean+scale',color='green',size=16)
ax.text(x=-5,y=0.02,s='mean-scale',color='orange',size=16)
ax.set_title('参数说明')
#数据集大小的影响
m_list=range(5,105,5) #数据集大小,从5到100
mean=1 #模拟均值
scale=1 #模拟广度
result_list=[]
ax=axs[0,1]
for m in m_list:
x=(np.random.random(m)+mean)*scale #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(m_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('数据集大小的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟数据集大小')
#模拟均值的影响
m=50 #数据集大小
mean_list=np.linspace(1,10,18) #模拟均值
scale=1 #模拟广度
result_list=[]
ax=axs[1,0]
for mean in mean_list:
x=(np.random.random(m)+mean)*scale #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(mean_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('均值的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟均值')
#模拟广度的影响
m=50 #数据集大小
mean=1 #模拟均值
scale_list=np.linspace(1,20,20) #模拟广度
result_list=[]
ax=axs[1,1]
for scale in scale_list:
x=(np.random.random(m)+mean)*scale #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(scale_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('广度的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟广度')
fig.tight_layout()
fig.savefig('001_random.png')
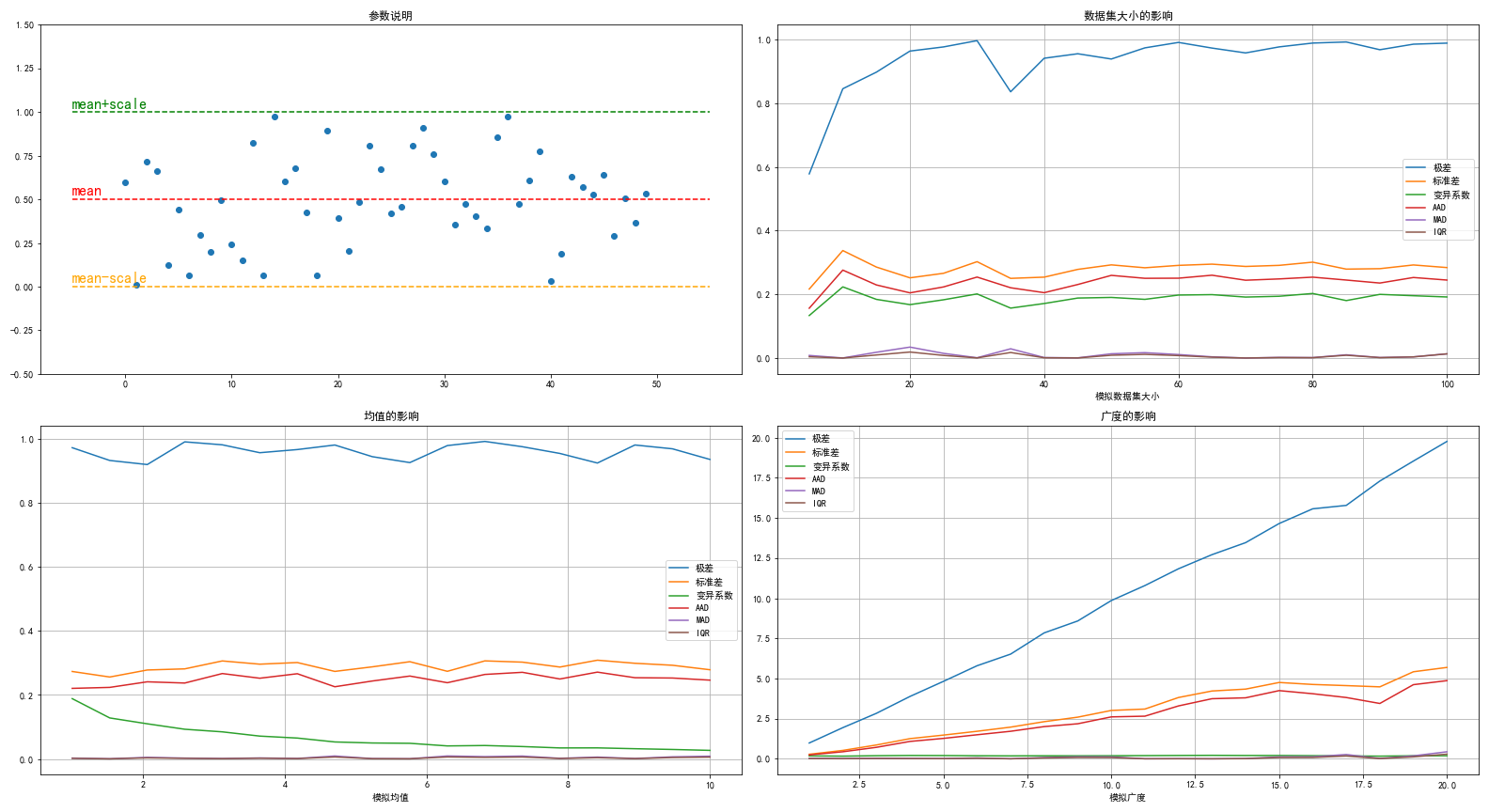
因为是比较接近平均分布,可以看到中位数绝对偏差与四分位数偏差都非常低,比较接近0。
随着数据集的变化,方差、标准差与绝对平均偏差则稳定在某个值,这三者的变化趋势几乎相同。
而极差跟变异系数相对比较高。
而如果数据集比较小,极差、中位数绝对偏差跟变异系数可能存在较大的失真,其他的度量都比较鲁棒。
均值仅影响了变异系数,毕竟变异系数是用了均值来校正标准差。
其他的每一种度量其实都跟均值没啥关系。
广度对于极差的影响是极大的(呈线性影响),然后是标准差、中位数绝对偏差。
变异系数与四分位数偏差几乎不会受到广度的影响。
二、正态分布的数据集
设一个数据集,这个数据集是均值为mean,标准差为scale的随机正态分布的数据集,数据集的大小为m。
measure_list=['极差','标准差','变异系数','AAD','MAD','IQR']
#生成画布与坐标轴
fig,axs=plt.subplots(nrows=2,ncols=2)
fig.set_size_inches((22,12))
#各参数说明
ax=axs[0,0]
#确定参数
m=10000 #数据集大小
mean=1 #模拟均值
scale=1 #模拟标准差
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集
ax.hist(x,bins=30)
ax.plot([mean,mean],[900,0],linestyle='--',color='yellow')
ax.text(x=mean+0.1,y=100,s='mean',color='yellow')
ax.set_title('随机数据集分布图示例')
#数据集大小的影响
m_list=range(10,10000,100) #数据集大小,从5到100
mean=1 #模拟均值
scale=1 #模拟广度
result_list=[]
ax=axs[0,1]
for m in m_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(m_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('数据集大小的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟数据集大小')
#模拟均值的影响
m=1000 #数据集大小
mean_list=np.linspace(1,10,18) #模拟均值
scale=1 #模拟广度
result_list=[]
ax=axs[1,0]
for mean in mean_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(mean_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('均值的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟均值')
#模拟标准差的影响
m=1000 #数据集大小
mean=1 #模拟均值
scale_list=np.linspace(1,20,20) #模拟标准差
result_list=[]
ax=axs[1,1]
for scale in scale_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集生成
result_list.append(measure(x)) #各种度量结果的扩充
for i in range(6):
ax.plot(scale_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('标准差的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟标准差')
fig.tight_layout()

对于正态分布的数据集,数据集大小对极值的影响非常大,只有数据集大小>100的时候极值才趋向于稳定。
(总体的)均值仅对变异系数有影响,与平均分布的一致。
(总体的)标准差应该是直接影响散布情况的唯一参数,随着标准差的变化,变异情况极度不稳定。
特别的,MAD在正态分布的数据集中都非常趋向于0。
据说MAD非常的鲁棒,比标准差更能适应数据集中的异常值。对于标准差,使用的是数据到均值的距离平方,所以大的偏差权重更大,异常值对结果也会产生重要影响。对于MAD,少量的异常值不会影响最终的结果。
而且,MAD可以适用于均值与标准差不起作用的分布(如柯西分布)。
接下来测试一下各种度量的鲁棒性质。
三、带噪音点的正态分布的数据集
设一个数据集,这个数据集是均值mean=1,标准差为scale=1的随机正态分布的数据集,数据集的大小为m=1000。(与上面相同)
在这个数据集的基础上,增加噪音集,这个噪音集是正态随机分布,均值为mean_n,标准差为scale_n。
这次不讨论极差(因为一般都是线性,且随着噪音的增多飞速上升)。
measure_list=['极差','标准差','变异系数','AAD','MAD','IQR']
#生成画布与坐标轴
fig,axs=plt.subplots(nrows=2,ncols=2)
fig.set_size_inches((22,12))
#各参数说明
ax=axs[0,0]
#确定参数
m=10000 #数据集大小
mean=1 #模拟均值
scale=1 #模拟标准差
n=100 #噪音集大小
mean_n=5 #模拟噪音均值
scale_n=1 #模拟噪音标准差
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集
xn=np.random.normal(loc=mean_n,scale=scale_n,size=n) #随机噪音集
ax.scatter(range(m),x)
ax.scatter(range(0,m,int(m/len(xn))),xn)
ax.set_title('随机数据集分布图示例')
#噪音集大小的影响
m=10000 #数据集大小
mean=1 #模拟均值
scale=1 #模拟标准差
n_list=range(10,10000,100) #噪音集大小,从5到100
mean_n=5 #模拟均值
scale_n=1 #噪音模拟标准差
result_list=[]
ax=axs[0,1]
for n in n_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机数据集生成
xn=np.random.normal(loc=mean_n,scale=scale_n,size=n) #随机噪音集生成
result_list.append(measure(np.append(x,xn))) #各种度量结果的扩充
for i in range(1,6):
ax.plot(n_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('噪音集大小的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟噪音集大小')
#模拟噪音均值的影响
m=10000 #数据集大小
mean=1 #模拟均值
scale=1 #模拟标准差
n=1000 #噪音集大小
mean_n_list=np.linspace(1,10,18) #模拟噪音均值
scale_n=1 #噪音模拟标准差
result_list=[]
ax=axs[1,0]
for mean_n in mean_n_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机噪音集生成
xn=np.random.normal(loc=mean_n,scale=scale_n,size=n) #随机噪音集生成
result_list.append(measure(np.append(x,xn))) #各种度量结果的扩充
for i in range(1,6):
ax.plot(mean_n_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('噪音均值的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟噪音均值')
#模拟噪音标准差的影响
m=10000 #数据集大小
mean=1 #模拟均值
scale=1 #模拟标准差
n=1000 #噪音集大小
mean_n=5 #噪音模拟均值
scale_n_list=np.linspace(0.1,2,20) #噪音模拟标准差
result_list=[]
ax=axs[1,1]
for scale_n in scale_n_list:
x=np.random.normal(loc=mean,scale=scale,size=m) #随机噪音集生成
xn=np.random.normal(loc=mean_n,scale=scale_n,size=n) #随机噪音集生成
result_list.append(measure(np.append(x,xn))) #各种度量结果的扩充
for i in range(1,6):
ax.plot(scale_n_list,np.array(result_list)[:,i],label=measure_list[i]) #画出图片
ax.set_title('噪音标准差的影响')
ax.grid()
ax.legend()
ax.set_xlabel('模拟噪音标准差')
fig.tight_layout()
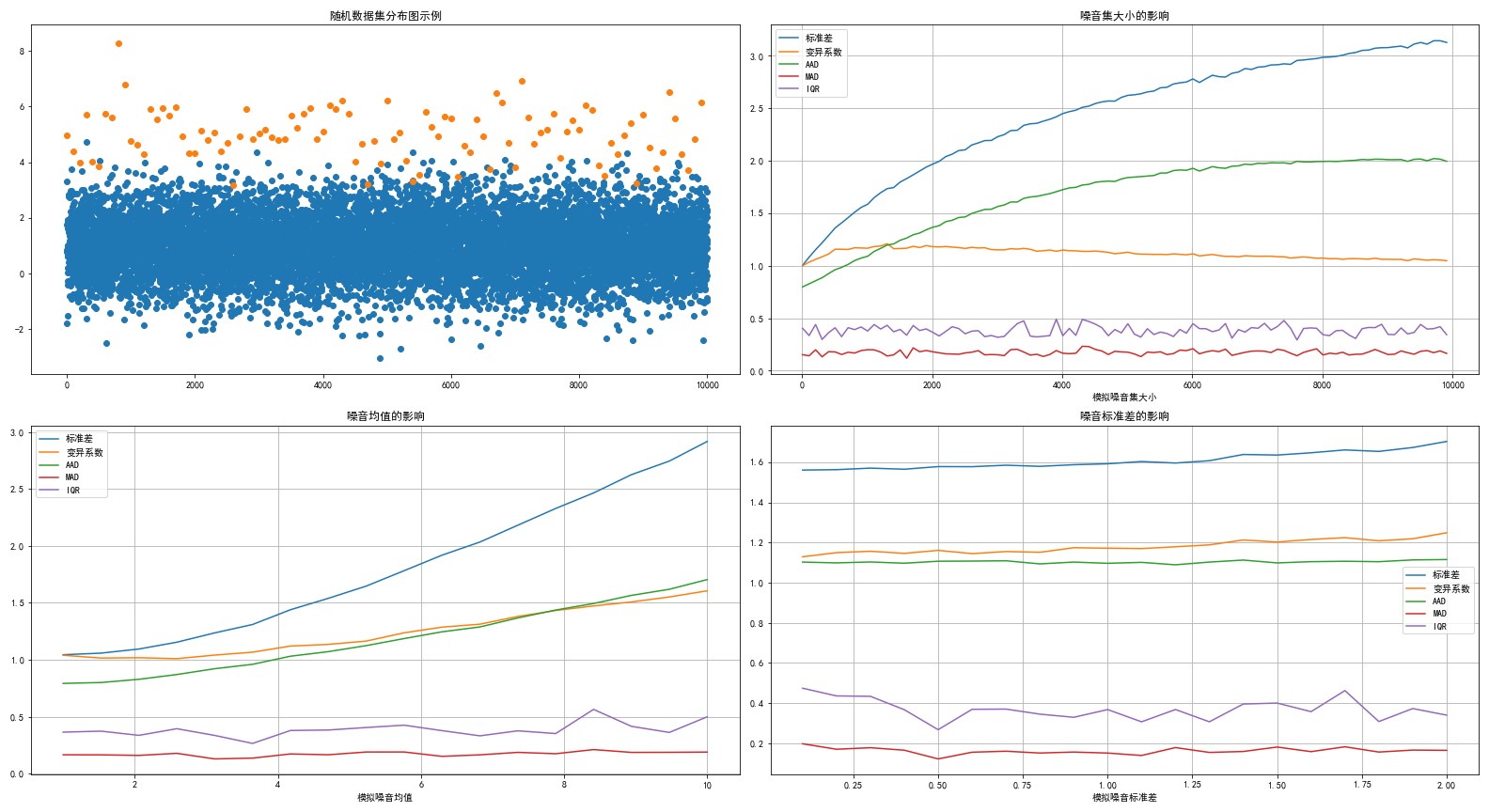
从图中可以看出,标准差、变异系数与AAD都会随着噪音的增多、增强而变大。
而MAD与IOR则变化较少。中位数与四分位数带给了这两个度量极大的鲁棒性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号