
hadoop(四)
二、MapReduce架构特点
MapReduce1.x
JobTracker
主节点,单点,负责调度所有的作用和监控整个集群的资源负载。
TaskTracker
从节点,自身节点资源管理和JobTracker进行心跳联系,汇报资源和获取task。
Client
以作业为单位,规划作业计算分布,提交作业资源到HDFS,最终提交作业到JobTracker。
Slot(槽):
属于JobTracker分配的资源(计算能力、IO能力等)。
不管任务大小,资源是恒定的,不灵活但是好管理。
Task(MapTask-->ReduceTask):
开始按照MR的流程执行业务。
当任务完成时,JobTracker告诉TaskTracker回收资源。
MapReduce1.x的弊端
1.JobTracker负载过重,存在单点故障。
2.资源管理和计算调度强耦合,其它计算框架难以复用其资源管理。
3.不同框架对资源不能全局管理。
MapReduce2.x
Client: 客户端发送MR任务到集群,其中客户端有很多种类,例如hadoop jar
ResourceManager: 资源协调框架的管理者,分为主节点和备用节点(防止单点故障,主备的切换基于ZK的管理),它时刻与NodeManager保持心跳,接受NodeManager的汇报(NodeManager当前节点的资源情况)。
当有外部框架要使用资源的时候直接访问ResourceManager即可。
如果是有MR任务,先去ResourceManager申请资源,ResourceManager根据汇报分配资源,例如资源在NodeManager1,那么NodeManager1要负责开辟资源。
Yarn(NodeManager): Yarn(Yet Another Resource Negotiator,另一种资源协调者),统一管理资源。以后其他的计算框架可以直接访问yarn获取当前集群的空闲节点。
每个DataNode上默认有一个NodeManager,NodeManager汇报自己的信息到ResourceManager。
Container: 它是动态分配的,2.X资源的代名词。
ApplicationMaster: 我们本次任务的主导者,负责调度本次被分配的资源Container。当所有的节点任务全部完成,applicaion告诉ResourceManager请求杀死当前ApplicationMaster线程,本次任务的所有资源都会被释放。
Task(MapTask--ReduceTask): 开始按照MR的流程执行业务,当任务完成时,ApplicationMaster接收当前节点的反馈。
YARN【Yet Another Resource Negotiator】:Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的。
核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现:
ResourceManager:负责整个集群的资源管理和调度。
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
YARN的引入,使得多个计算框架可运行在一个集群中 每个应用程序对应一个ApplicationMaster 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm等。
三、Hadoop搭建yarn环境
四、扑克牌的问题
你想数出一摞牌中有多少张黑桃,红桃,方块,梅花。直观方式是一张一张检查并且数出分别有多少张。 MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几张是黑桃,然后把这个数目汇报给你 3.你把所有玩家告诉你的数字加起来,得到最后的结论
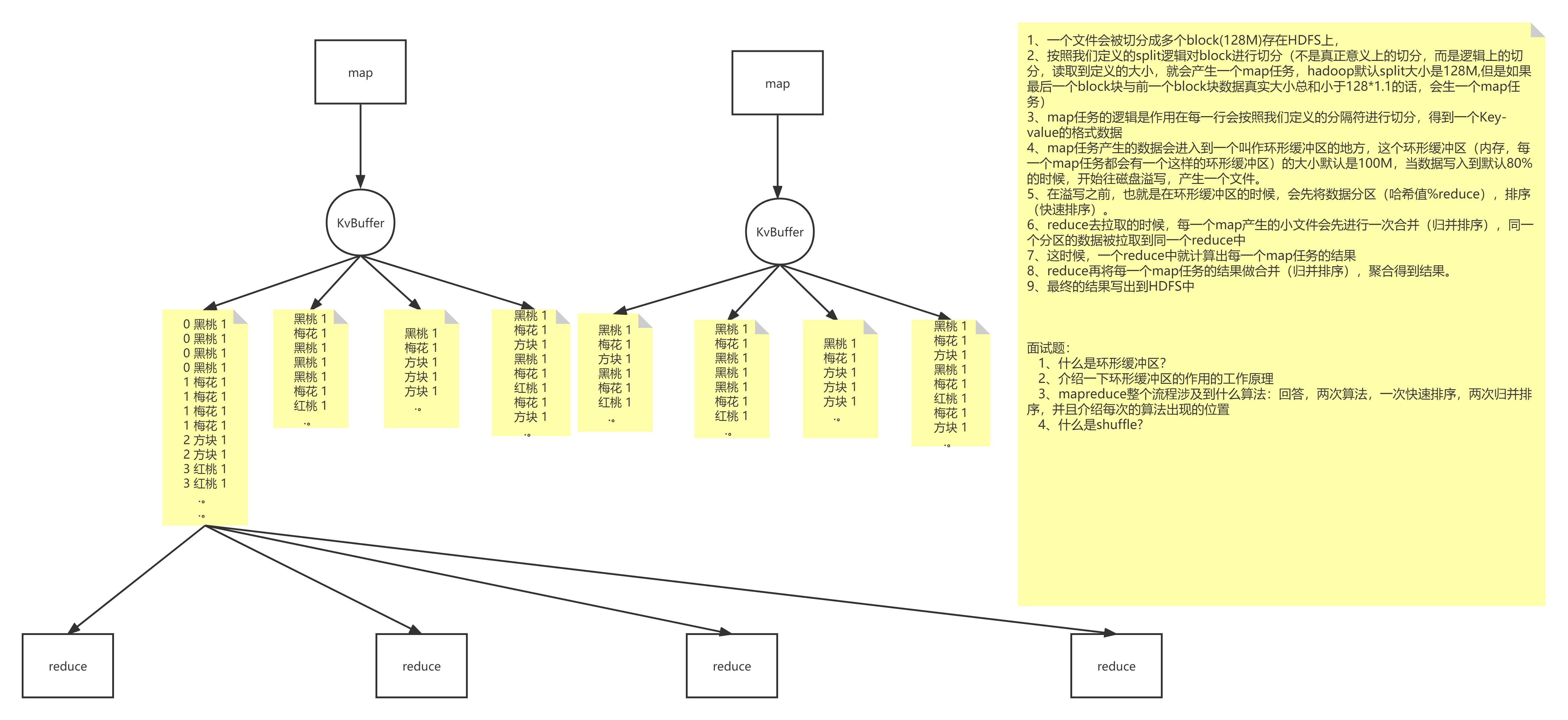
五、MR的计算流程
计算1T数据中每个单词出现的次数---->wordcount
5.1 原始数据File
The books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger, all of whom are students at Hogwarts School of Witchcraft and Wizardry.
1T数据被切分成块存放在HDFS上,每一个块有128M大小
5.2 数据块Block
block块是hdfs上数据存储的一个单元,同一个文件中块的大小都是相同的
因为数据存储到HDFS上不可变,所以有可能块的数量和集群的计算能力不匹配
我们需要一个动态调整本次参与计算节点数量的一个单位
我们可以动态的改变这个单位–-->参与的节点
5.3 切片Split
目的:动态地控制计算单元的数量
切片是一个逻辑概念
在不改变现在数据存储的情况下,可以控制参与计算的节点数目
通过切片大小可以达到控制计算节点数量的目的
有多少个切片就会执行多少个Map任务
一般切片大小为Block的整数倍(2 1/2)
防止多余创建和很多的数据连接
如果Split大小 > Block大小 ,计算节点少了
如果Split大小 < Block大小 ,计算节点多了
默认情况下,Split切片的大小等于Block的大小 ,默认128M,如果读取到最后一个block块的时候,与前一个blokc块组合起来的大小小于128M*1.1的话,他们结合生一个split切片,生成一个map任务
一个切片对应一个MapTask
5.4 MapTask
map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中(map种的逻辑作用在每一行上)
我们可以根据自己书写的分词逻辑(空格,逗号等分隔),计算每个单词出现的次数(wordcount)
这时会产生(Map<String,Integer>)临时数据,存放到内存中
the books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger, all of whom are students at Hogwarts School of Witchcraft and Wizardry
the 1
books 1
chronicle 1
the 1
adventures 1
of 1
...
Wizardry 1
但是内存的大小是有限的,如果每个任务随机的去占用内存,会导致内存不可控。多个任务同时执行有可能内存溢出(OOM)
如果把数据都直接放到硬盘,效率太低
所以想个方案,内存和硬盘结合,我们要做的就是在OOM和效率低之间提供一个有效方案,可以先往内存中写入一部分数据,然后写出到硬盘
5.5 环形缓冲区(KV-Buffer)
可以循环利用这块内存区域,减少数据溢写时map的停止时间
每一个Map可以独享的一个内存区域
在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M
设置缓冲区的阈值为80%(设置阈值的目的是为了同时写入和写出),当缓冲区的数据达到80M开始向外溢写到硬盘
溢写的时候还有20M的空间可以被使用效率并不会被减缓
而且将数据循环写到硬盘,不用担心OOM问题
说完这个先说溢写,合并,拉取(分析出问题得到结论),再说中间的分区排序
5.6 分区Partition(环形缓冲区做的)
根据Key直接计算出对应的Reduce
分区的数量和Reduce的数量是相等的
hash(key) % partation(reduce的数量) = num
默认分区的算法是Hash然后取余
Object的hashCode()—equals()
如果两个对象equals,那么两个对象的hashcode一定相等
如果两个对象的hashcode相等,但是对象不一定equlas
5.7 排序Sort(环形缓冲区做的,快速排序,对前面分区后的编号进行排序,使得相同编号的在一起)
对要溢写的数据进行排序(QuickSort)
按照先Partation后Key的顺序排序–>相同分区在一起,相同Key的在一起
我们将来溢写出的小文件也都是有序的
5.8 溢写Spill
将内存中的数据循环写到硬盘,不用担心OOM问题
每次会产生一个80M的文件
如果本次Map产生的数据较多,可能会溢写多个文件
5.9 合并Merge
因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定
后面向reduce传递数据带来很大的问题
所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
合并小文件的时候同样进行排序(归并 排序),最终产生一个有序的大文件
5.10 组合器Combiner
a. 集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间的数据传输,hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数(如同map函数和reduce函数一般),其逻辑一般和reduce函数一样,combiner的输入是map的输出,combiner的输出作为reduce的输入,很多情况下可以i直接将reduce函数作为conbiner函数来试用(job.setCombinerClass(FlowCountReducer.class))。
b. combiner属于优化方案,所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner,但是要保证不管调用多少次,combiner函数都不影响最终的结果,所以不是所有处理逻辑都可以i使用combiner组件,有些逻辑如果试用了conbiner函数会改变最后reduce的输出结果(如求几个数的平均值,就不能先用conbiner求一次各个map输出结果的平均值,再求这些平均值的平均值,那样会导致结果的错误)。
c. combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量:
原先传给reduce的数据时a1 a1 a1 a1 a1
第一次combiner组合后变成a(1,1,1,1,1)
第二次combiner后传给reduce的数据变为a(5,5,6,7,23,...)
5.11 拉取Fetch
我们需要将Map的临时结果拉取到Reduce节点
第一种方式:两两合并
第二种方式:相同的进一个reduce
第三种对第二种优化,排序
第四种对第三种优化:如果一个reduce处理两种key,而key分布一个首一个尾,解决不连续的问题,给个编号,这个编号怎么算呢,`回到分区,排序`原则(用统计姓氏的例子画图理解)
相同的Key必须拉取到同一个Reduce节点
但是一个Reduce节点可以有多个Key
未排序前拉取数据的时候必须对Map产生的最终的合并文件做全序遍历
而且每一个reduce都要做一个全序遍历
如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需的即可
5.12 合并Merge
因为reduce拉取的时候,会从多个map拉取数据
那么每个map都会产生一个小文件,这些小文件(文件与文件之间无序,文件内部有序)
为了方便计算(没必要读取N个小文件),需要合并文件
归并算法合并成2个(qishishilia)
相同的key都在一起
5.13 归并Reduce
将文件中的数据读取到内存中
一次性将相同的key全部读取到内存中
直接将相同的key得到结果–>最终结果
5.14 写出Output(说完这个后再画两个案例图总结)
每个reduce将自己计算的最终结果都会存放到HDFS上
5.15 MapReduce过程截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号