MongoDB分片集群和Collection分片
MongoDB Sharding
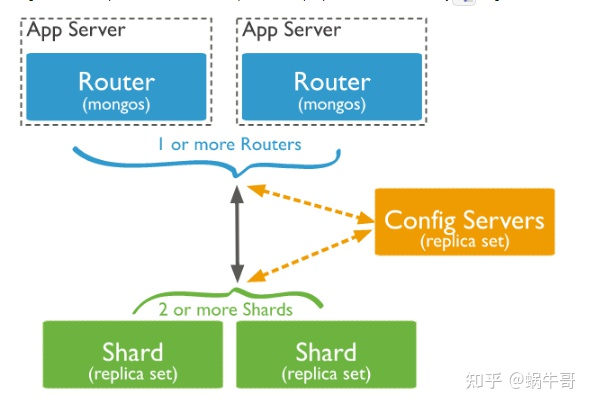
角色说明
- A.数据分片(Shards)
- 用来保存数据,保证数据的高可用性和一致性。可以是一个单独的mongod实例,也可以是一个副本集。在生产环境下Shard一般是一个Replica Set,以防止该数据片的单点故障。所有Shard中有一个PrimaryShard,里面包含未进行划分的数据集合:
- B.配置服务器(Config servers)
- 保存集群的元数据(metadata),包含各个Shard的路由规则。
- 元数据 名词解释:元数据是关于数据的组织、数据域及其关系的信息,简言之,元数据就是关于数据的数据
- C.查询路由(Query Routers)
- Mongos是Sharded cluster的访问入口,其本身并不持久化数据(Sharded cluster所有的元数据都会存储到Config Server,而用户的数据则会分散存储到各个shard)
- Mongos启动后,会从config server加载元数据,开始提供服务,将用户的请求正确路由到对应的Shard Sharding集群可以有一个mongos,也可以有多mongos以减轻客户端请求的压力。
这里的分片是集群部属方式,类似于Redis的cluster模式。
Primary shard
使用 MongoDB sharding 后,数据会以 chunk 为单位(默认64MB)根据 shardKey 分散到后端1或多个 shard 上。
每个 database 会有一个 primary shard,在数据库创建时分配(不同的database的primary shard不同,比如database1的primary shard在 shard1,而database2的primary shard在shard2),这里的shard是一个mongoDb的服务器实例,或者复制集实例。
- database 下启用分片(即调用
shardCollection命令)的集合,刚开始会生成一个[minKey, maxKey] 的 chunk,该 chunk 初始会存储在primary shard上,然后随着数据的写入,不断的发生 chunk 分裂及迁移,整个过程如下图所示。 - database 下没有启用分片的集合,其所有数据都会存储到
primary shard
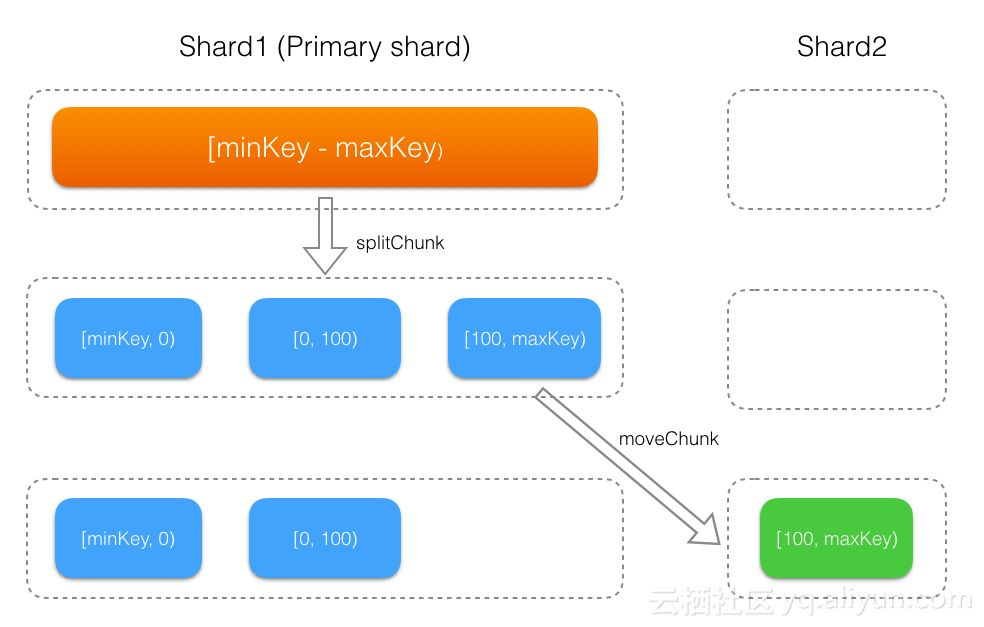
小结:一个新的collection开始时只会往primary sharding所在的shard上写数据,直到发生chunk迁移后,才会写入到其他shard
Chunk 分裂
上面提到了一个概念chunk,mongos 上有个 sharding.autoSplit 的配置项,可用于控制是否自动触发 chunk 分裂,默认是开启的。如无专业人士指导,强烈建议不要关闭 autoSplit,更好的方式是使用「预分片」的方式来提前分裂,后面会详细介绍。
mongoDB 的自动 chunk 分裂只会发生在 mongos 写入数据时,当写入的数据超过一定量时,就会触发 chunk 的分裂,具体规则如下。
| 集合chunk数量 | 分裂阈值 |
|---|---|
| 1 | 1024B |
| [1, 3) | 0.5MB |
| [3, 10) | 16MB |
| [10, 20) | 32MB |
| [20, max) | 64MB |
分裂后,chunk增多,同时每个chunk中数据量减半。chunk只会分裂,不会合并。
数据分片的方式有两种
哈希分片
哈希分片使用hash索引来在分片集群中对数据进行划分。哈希索引计算某一个字段的哈希值作为索引值,这个值被用作片键。哈希分片以减少定向操作和增加广播操作为代价。分片集群内的数据更加均衡。从MongoDB4.0开始,mongo shell提供了convertShardKeyToHashed()方法,用于查看键的hash值。选择作为hash分片键的字段应该有良好的基数或者该字段包含大量不同的值,hash分片非常适合选取具有像objectId或时间戳那样单调更改的字段作为片键。
使用sh.shardCollection()方法,来对集合进行hash分片
sh.shardCollection("database.collection",{<field> : "hashed" } )
范围分片
基于范围的分片会将数据划分为由片键值确定的连续范围。在范围分片模型中,具有“接近”片键的文档可能位于相同的chunk或者shard中,连续范围读取文档将变得高效,但是如果片键选择不佳,则读取和写入的想你将会降低。
如果未选择其它选项(如hash分片或者zone),则基于范围的分片是默认的分片方式。
范围分片片键的选择:
- 基数大
- 频率低
- 非单调变化
使用sh.shardCollection()方法,来对集合进行范围分片,可以选择单字段或者多字段
sh.shardCollection("database.collection",{<shard key>})
Chunk迁移
在分片+复制集的架构中,当某个服务器上的数据记录不停的增多,它上面分割的chunk就会变多,当集群中每个服务器上的chunk数量严重失衡的时候,mongodb会自动进行chunk的迁移工作,这个自动迁移的工作,是通过balancer来进行的。如果balancer发现各个shard之间的chunk数差异超过了提前规定的阈值,则会进行chunk的迁移工作,如下:
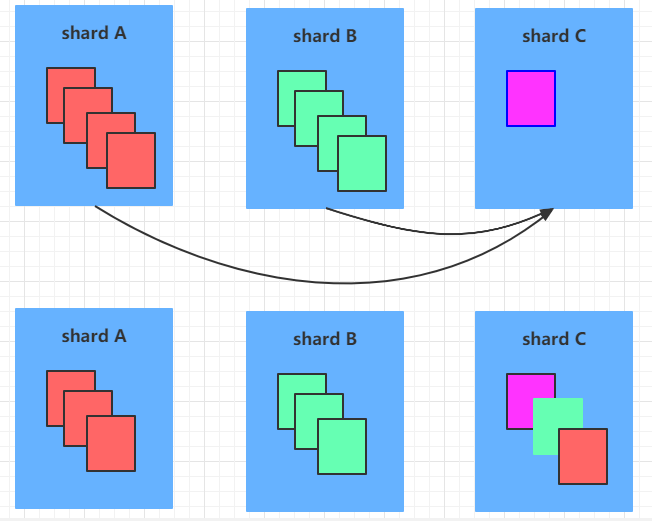
MongoDB默认情况下会开启一个balancer模块用于定期检测各个shard上的chunk数量分布,当检测到各个shard上的chunk数量存在分布不均匀的情况时,就会触发chunk迁移。如下图,三个shard的chunk数量分别为3、3、1,此时balancer认为chunk数量分布不均,于是会将shard B上的chunk迁移一个到shard C上,这样三个shard的chunk数量分布最终就会变为3、2、2,分布更为均匀。
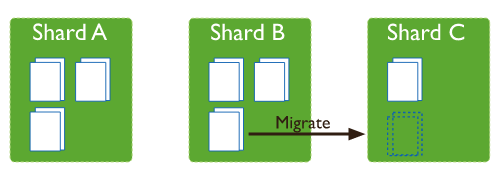
(1)根据shard tag迁移
MongoBD sharding支持shard tag特性,用户可以给shard打上标签,然后给集合的某个range打上标签,MongoDB会通过balancer的数据迁移来保证「拥有tag的range会分配到具有相同tag的shard上」。
(2)根据shard间chunk数量迁移
int threshold = 8; if (balancedLastTime || distribution.totalChunks() < 20) threshold = 2; else if (distribution.totalChunks() < 80) threshold = 4;
| 集合 chunk 数量 | 迁移阈值 |
|---|---|
| [1, 20) | 2 |
| [20, 80) | 4 |
| [80, max) |
8
|
针对所有启用分片的集合,如果「拥有最多数量chunk的shard」与「拥有最少数量chunk的shard」的差值超过某个阈值,就会触发chunk迁移; 有了这个机制,当用户调用addShard添加新的shard,或者各个shard上数据写入不均衡时,balancer就会自动来均衡数据。
(3)removeShard触发迁移
还有一种情况会触发迁移,当用户调用removeShard命令从集群里移除shard时,Balancer也会自动将这个shard负责的chunk迁移到其他节点,
Chunk迁移具体过程

完成一次chunk迁移需要进行以下7个步骤:
1)发送方发起迁移: configsvr向发送方请求进行指定chunk的迁移任务(同一时刻只能执行一个chunk迁移)。如果此时发现已有一个相同的chunk的迁移任务,跳过此次迁移,否则会新发起一个迁移任务。
2)接收方发起chunk拷贝: 发送方进行迁移参数的校验,校验通过后,向接收方发送recvChunkStart命令,接收方进行一些传送文档数据的初始化工作后,会不断重复地向发送方发送migrateClone命令批量拉取chunk中的文档并将拉取的文档进行批量插入,即进行文档的全量拷贝。
3)接收方拉取增量修改: 文档全量拷贝完成后,接收方通过不断重复发送transferMods命令拉取chunk的增量修改(包括插入、更新、删除),并将其应用到自身。(迁移开始一段时间内的,不可能有增量就一直同步)
4)发送方等待接收方chunk拷贝完成: 发送方不断向接收方发送recvChunkStatus命令查询文档增量同步是否完成或超时,当增量同步完成时,表示此时接受方已进入“steady”状态,可以进行接下来的流程。
5)发送方进入临界区: 一旦当接收方的文档数据同步完成,发送方就会进入临界区(critical section),此时发送方接下来的操作不可被打断,并且所有发送方的写操作将被挂起,直到发送方退出临界区。
6)接收方执行commit: 发送方进入临界区后,接下来会同步地调用recvChunkCommit命令给接收方,接收方再一次进行chunk文档的增量同步,同步完成后,向接收方返回同步完成的结果,接收方退出临界区。
7)configsvr执行commit: 接收方收到同步完成的结果后,向configsvr发送configsvrCommitChunkMigration命令,表示迁移完成。(configsvrCommitChunkMigration命令返回前,发送方的读操作会被挂起)
然后会进入到临界区
- 本地更新迁移的metaData,阻塞写操作
-
发送者增大已迁移的chunk元数据的version(相当于标记为旧数据)
-
读操作挂起
-
向configsvr发送commit请求,刷新路由
-
等待configsvr的secondary同步刷新路由操作完成
-
上述过程若出错(如发送者stepDown、configsvr异常),则尽量保留现场用于恢复迁移任务
-
执行chunk的删除或延迟删除
-
恢复写操作


 浙公网安备 33010602011771号
浙公网安备 33010602011771号