

深度学习(五)-transformer概述
一、引入
1、机器翻译中,seq2seq,输入和输出都是序列,且输出长度不确定
2、RNN作为编码器和解码器,不能并行计算,效率低
3、2017年提出基于注意力机制的Transformer模型,解决RNN的问题
二、注意力机制
1、类似人类视觉,把注意力放在关键信息上,忽略不重要的信息
2、注意力机制模型有3个字段:Q:query,要去查询的;K:key,等着被查询的;V:value,实际的特征信息
3、计算步骤:
a.query和key进行相似度计算,得到权值
b.权值归一化
c.把权值和value进行加权求和
三、Transformer架构
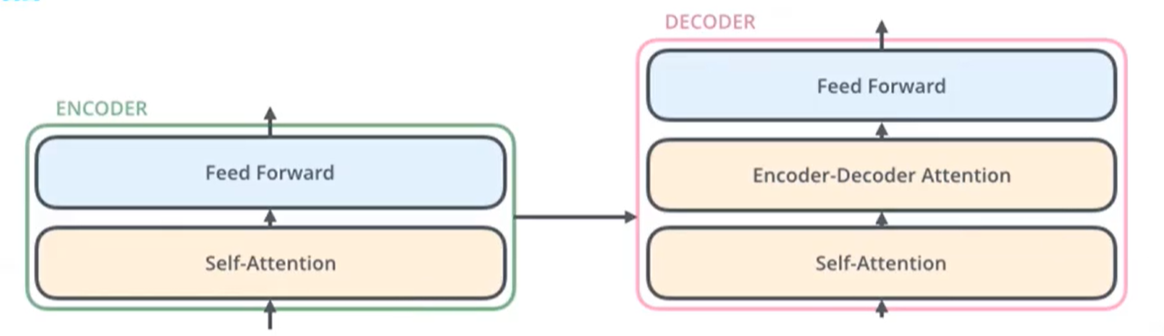
1、Transformer架构由多个编码器和解码器组成

2、编码器由自注意力层和前馈神经网络层组成
解码器由自注意力层、编解码注意力层、前馈神经网络层组成
四、Transformer算法过程
1、在最底层的编码器中,原始单词->词嵌入算法->词向量,512维
2、每个编码器接收词向量,先经过自注意力层,再经过前馈神经网络层
3、从每个编码器的输入向量,拆分成Q、K、V3个向量

4、多头注意力机制
五、图像处理Vision Transformer(ViT,2020年提出)
1、Transformer代替CNN做特征提取和图像分类,挑战AlexNet的地位,打破了NLP和CV的壁垒,可以应用于多模态
2、核心是把图像,转换为Transformer需要的token向量,即二维矩阵[num_token,token_dim],而图片是三维矩阵,需要做预处理转换
3、算法流程
a.把图片切分为patch
b.patch转化为embedding
c.位置的embedding和token embedding相加
d.输入到Transformer
e.CLS输出做多分类任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号