
python-day1
一、python介绍
1.计算机基础
2.python历史
3.编程语言的种类
3.1 编译型与解释型
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
而解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
3.2动态语言和静态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
(1)动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
(2)静态类型语言:静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
3.3强类型定义语言和弱类型定义语言
(1)强类型定义语言:强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
(2)弱类型定义语言:数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言); JAVA是静态语言,是强类型定义语言(类型安全的语言)。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。
4.python的类型
二、python基础
1.运行第一个py文件(hello world)
print 'hello world' (低版本) print ('hello world')(2.7以后)
Linux python解释器的地址:
#!/user/bin/env python(python解释器的路径 Linux) 指明这条代码之后 : #python h.py 改为文件的地址 如./h.py #并加上文件的访问权限 chmod 755 h.py
2.内容编码
-
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。 显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
-
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536, 注:此处说的的是最少2个字节,可能更多
-
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
1 #!/usr/bin/env python 2 3 print "你好,世界"
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:(python2.7)
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*-//只需要在python2中用 python3默认utf-8 3 4 print "你好,世界"
3.注释
4.输入 (用户交互) input
1 #!/usr/bin/env python 2 # -*-coding :utf-8 -*- 3 4 import getpass 5 6 # 将用户输入的内容赋值给 i1 变量 7 //name=input('请输入你的名字:') 8 //age=input('请输入你的年龄') 9 //print('我的名字是'+name,'我的年龄是'+age+'岁') 10 i1 = input("UserName:")//2.7是raw_input 用于和用户交互,等待用户输入内容, i1 则是用户输入的东西 11 i2 = getpass.getpass('PassWord:')利用getpass 模块中的 getpass方法 //在window上不显示密码 但在idle上显示密码 12 print(i1) 13 print(i2) 14
5.变量
1、声明变量
1 name = "wupeiqi"
上述代码声明了一个变量,变量名为: name,变量name的值为:"wupeiqi"
2.变量定义的规则:
-
变量名只能是 字母、数字或下划线的任意组合
-
变量名的第一个字符不能是数字
- 具有可描述性,不能用中文,也不能用拼音
-
以下关键字不能声明为变量名
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 name1 = "wupeiqi" 5 name2 = "alex" //name2 = name1
6.常量
常量即指不变的量,如pai 3.141592653..., 或在程序运行过程中不会改变的(不可更改)
在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量
AGE_OF_OLDBOY = 56 #一旦定义为常量,更改即会报错
7.基础数据类型(初始)
7.1 整数类型(int)。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
1 >>> a= 2**64 2 >>> type(a) #type()是查看数据类型的方法 3 <type 'long'> 4 >>> b = 2**60 5 >>> type(b) 6 <type 'int'>
7.2 字符串类型(str)
在Python中,加了引号的字符都被认为是字符串!
那单引号、双引号、多引号有什么区别呢? 让我大声告诉你,单双引号木有任何区别,只有下面这种情况 你需要考虑单双的配合
msg = "My name is Alex , I'm 22 years old!"
多引号什么作用呢?作用就是多行字符串必须用多引号
1 msg = ''' 2 今天我想写首小诗, 3 歌颂我的同桌, 4 你看他那乌黑的短发, 5 好像一只炸毛鸡。 6 ''' 7 print(msg)
7.2.1 字符串拼接
注意,字符串的拼接只能是双方都是字符串,不能跟数字或其它类型拼接
1 >>> name 2 'Alex Li' 3 >>> age 4 '22' 5 >>> 6 >>> name + age #相加其实就是简单拼接 7 'Alex Li22' 8 >>> 9 >>> name * 10 #相乘其实就是复制自己多少次,再拼接在一起 10 'Alex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex LiAlex Li'
7.3 布尔值(True,False)
8. 格式化输出
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式
1 ------------ info of Alex Li ----------- 2 Name : Alex Li 3 Age : 22 4 job : Teacher 5 Hobbie: girl 6 ------------- end -----------------
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
1 name = input("Name:") 2 age = input("Age:") 3 job = input("Job:") 4 hobbie = input("Hobbie:") 5 6 info = ''' 7 ------------ info of %s ----------- #这里的每个%s就是一个占位符,本行的代表 后面拓号里的 name 8 Name : %s #代表 name 9 Age : %s #代表 age 10 job : %s #代表 job 11 Hobbie: %s #代表 hobbie 12 ------------- end ----------------- 13 ''' %(name,name,age,job,hobbie) # 这行的 % 号就是 把前面的字符串 与拓号 后面的 变量 关联起来 14 15 print(info)
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
age : %d
我们运行一下,但是发现出错了。。
input接收的所有输入默认都是字符串格式!
要想程序不出错,那怎么办呢?简单,你可以把str转成int
age = int( input("Age:") )
print(type(age))
肯定没问题了。相反,能不能把字符串转成数字呢?必然可以,str( yourStr )
9. 基本运算符
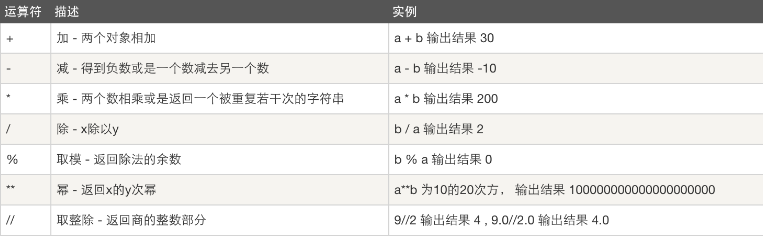
9.1 算数运算
9.2 比较运算![]()

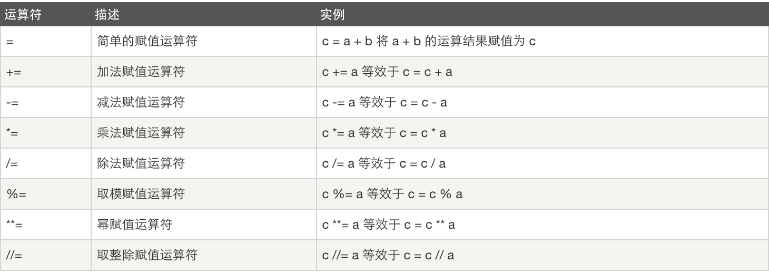
9.3 赋值运算
![]()
9.4 逻辑运算
![]()

1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
in,not in :
判断子元素是否在原字符串(字典,列表,集合)中:
10.流程控制之--if
10.1.单分支
if 条件:(冒号用来提示条件) 满足条件后要执行的代码(tab或四个空格 一个if中只能使用一种,上面的if代码里,每个条件的下一行都缩进了4个空格) '''这就是Python的一大特色,强制缩进,目的是为了让程序知道,每段代码依赖哪个条件,如果不通过缩进来区分,程序怎么会知道,当你的条件成立后,去执行哪些代码呢?'''
10.2.双分支
1 """ 2 if 条件: 3 满足条件执行代码 4 else: 5 if条件不满足就走这段 6 """ 7 AgeOfOldboy = 48 8 9 if AgeOfOldboy > 50 : 10 print("Too old, time to retire..") 11 else: 12 print("还能折腾几年!") 13 14 num=input('请输入您的数字')
10.3.多分支
1 if 条件: 2 满足条件执行代码 3 elif 条件: 4 上面的条件不满足就走这个 5 elif 条件: 6 上面的条件不满足就走这个 7 elif 条件: 8 上面的条件不满足就走这个 9 else: 10 上面所有的条件不满足就走这段 11 12 例子: 13 age_of_oldboy = 48 14 15 guess = int(input(">>:"))//类型转换 16 17 if guess > age_of_oldboy : 18 print("猜的太大了,往小里试试...") 19 20 elif guess < age_of_oldboy : 21 print("猜的太小了,往大里试试...") 22 23 else: 24 print("恭喜你,猜对了...")
10.4.嵌套
name=input('请输入名字:') age=input('请输入年龄:') if name=='小二': if age=='18': print('请你喝酒') else: print('喝什么酒')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号