
我的Redis学习笔记(四)——几种数据结构
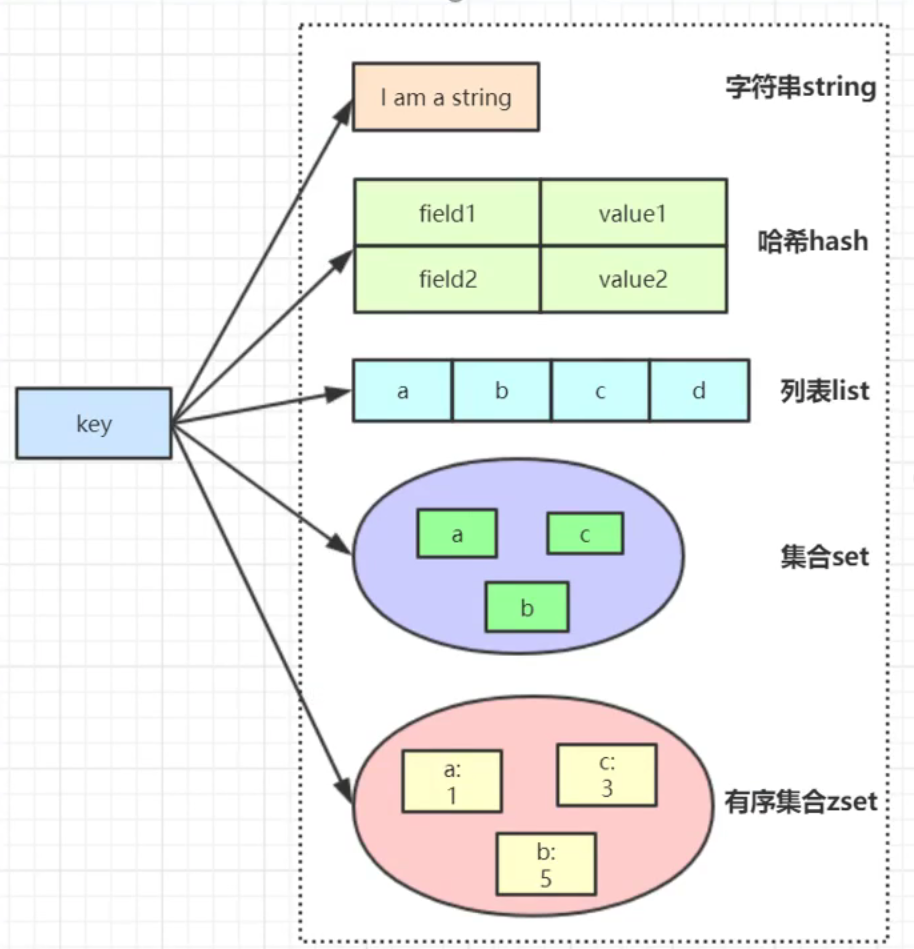
string (字符串)
字符串 string 是 Redis 最简单的数据结构。Redis 所有的数据结构都是以唯一的 key字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结构的差异就在于 value 的结构不一样。
list (列表)
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为O(n)。
当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
作用场景:微博、微信公众号等发布消息可以使用
hash (字典)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典。内部实现结构上同Java 的 HashMap 也是一致的,同样的数组 + 链表二维结构。第一维 hash 的数组位置碰撞时,就会将碰撞的元素使用链表串接起来。
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
1)过期功能不能使用在field上,只能用在key上
2) Redis集群架构下不适合大规模使用
set (集合)
Redis 的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的唯一的。它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值 NULL。
使用举例:微信抽奖小程序
1)点击参与抽奖加入集合 SADD key {userlID}
2)查看参与抽奖所有用户 SMEMBERS key
3)抽取count名中奖者 SRANDMEMBER key [count] / SPOP key [count]
zset (有序列表)
zset 可能是 Redis 提供的最为特色的数据结构,它也是在面试中面试官最爱问的数据结
构。它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部
value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权
重。它的内部实现用的是一种叫着「跳跃列表」的数据结构。
简图如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号