
那个执事,腾云:记一次某大型医院的同城双数据中心上云过程
摘要
本文介绍了我曾经的一个雇主给全国排行前 5 的某公立医院上私有云 + 容器云的过程。包括普通 Web 系统的迁移,也包括商业网络、存储设备的纳管,以及异构计算(GPU、FPGA)的支持。
医院及其信息系统状况
经过医院提供的信息和我们的调查,医院当时的信息系统的状况如下:
一、主要应用
- 医疗信息系统(HIS)(C-S 架构,数据库为 Oracle 11g RAC);
- 电子病历(数据库为 Oracle 11g RAC);
- 病历无纸化系统;
- PACS;
- 移动医护系统;
- 证书颁发(CA);
- 临床决策支持系统;
- 手麻系统;
- 合理用药系统;
- 院感系统;
- 绩效管理系统;
- 实验室信息系统(LIS);
- ESB(即古老的企业服务总线);
- OA;
- 各种前置服务系统(医保、预约挂号、卫建委平台等)。
二、部署架构
医院的物理服务器上安装 VMware 虚拟化软件。上述应用均以双活共享存储的方式运行在 VM 中。VM 实例数为 80 余个。
数据中心中有一些商业网络设备(F5)和商业存储设备。
某些应用(如影像系统)需要显卡(GPU),某些应用(如基因分析)需要 FPGA。
三、新数据中心问题
新的院区即将建设完毕,需要考虑双数据中心(每个院区一个数据中心)的容灾问题。新老院区在同一个城市。
四、其他
- 医院的各个应用均以源码(托管到内网 gitlab) + 构建脚本 + 部署手册的方式交付,且文档比较完善(很幸运!)
- 医院有内网 DNS 服务器,所有的系统均用内网域名互相访问(也很幸运!这会极大减少上云的难度)
医院的疑问
- 是否所有的应用都上容器?
- 上云之后,双数据中心的容灾怎样实现?
- 两个数据中心的网络如何建设有利于顺利上云?
- 上云之后,医院的应用改造涉及哪些方面?
上云思路分析
先挑出不上容器的应用(如 gitlab 服务器,CA)。
由于医院已经购买了 VMware 的永久授权,而且版本还比较新,所以将 VMware 作为虚拟机的后端实现(产品支持两种虚拟机:KVM 和 VMware)。
对于上云的应用,必须进行分类(哪些是普通 Web 软件,哪些是大内存的,哪些是高 CPU 负载的,哪些必须高可用,哪些要运行在 Windows 上,哪些需要特殊硬件),给这些应用规划标签(Kubernetes 的 label)。
给节点也要规划标签,标识它是否有某种设备,配置的高低,在哪个数据中心等信息。
另外,启用配额管理(产品功能),防止某个应用占用资源过多把别的应用挤爆。
由于应用中有很多云原生的反模式,所以要进行一些修改,用 DevOps 的方式部署的云。
上云方案和过程
网络建设
这部分与研发关系不大。简略叙述。
结果是医院找人在两个数据中心之间架设了高可用的专线,两个数据中心在一个局域网中。
(如此一来,不必为每个数据中心部署一个 Kubernetes 集群,而是只部署一个集群,大大简化了问题;双数据中心容灾也被简化为相当于一间机房的左、右半边容灾。)
云的部署
设备位置调整
在安装云之间,要调整机器的位置。把带 GPU 的机器、带 FPGA 的机器均分到两个数据中心,使得两边的 GPU、FPGA 数分别相当。
6 台 F5,其中 2 台当作 Kubernetes 的 apiserver 的负载均衡(每个数据中心放一个,配相同的内网域名);2 台有公网 IP,当作访问入口(每个数据中心放一个,配相同的内网和公网域名);2 台当作内网访问的入口(每个数据中心放一个,配相同的内网域名)。
Oracle 使用的商业存储设备也移动一下,均分到两边。
安装云软件
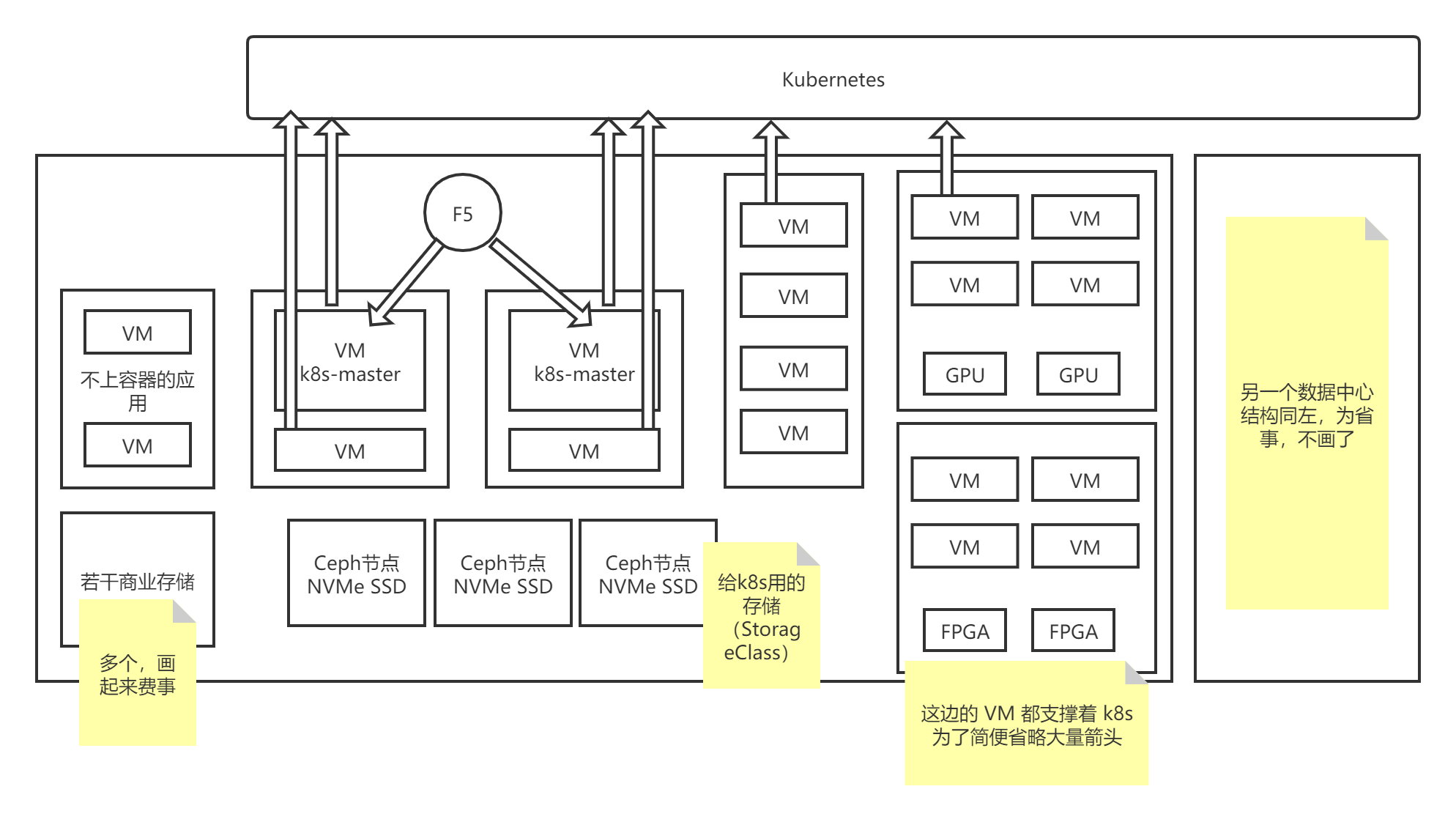
Kubernetes 集群的 master 4 个节点;etcd 3 个节点(一个数据中心 2 个,另一个 1 个,这其实是个隐患或缺陷,因为 2 个节点的数据中心被摧毁,etcd 就会坏掉)。
这里需要指出,有人所说的 Kubernetes 的 master 节点数必须为奇数是错的,master 的组件中,只有 etcd 是有状态的,其他组件(如 apiserver)根本无状态,自然不存在奇偶性的要求。
云提供了跨数据中心的高可用基础设置(如 PubSub、镜像中心、Redis、云数据库),这部分自带跨数据中心容灾。
Kubernetes 里面的负载不用考虑双数据中心容灾,就算一个负载的 Pod 全部在一个数据中心而这个数据中心被摧毁,Kubernetes 也会再别处(也就是另一数据中心)把 Pod 启动或恢复。由于两边的资源(如 GPU)是对称的,所以不存在在另一边无法启动的情况。
处理不上容器的应用和服务
Gitlab 、CA 放到配置比较高的 VM 上,和原来一样。
OA 不上容器,因为它的技术栈特别老旧,而且用到了很难上云的 WebLogic,所以它的 OA 没有合适的容器化方案。
HIS 整个(包括它的数据库)还在 VM 上,不上容器。
电子病历的数据库部分不上容器。
这是因为 Oracle 上容器的坑太多,业界没啥好办法。
Oracle + 商业存储的双机热备有官方的方案,照着配即可。只需要注意把计算节点的多个 VM 副本实例分到不同的数据中心。
标签规划
节点标签:
x-has-vgpu: [yes|no] # 是否有 vGPU
x-has-vfpga: [yes|no] # 是否有 vFPGA
(注:在我们的云软件中,GPU 是通过虚拟化技术虚拟出多个 vGPU 分别给多个 VM,然后容器独占 vGPU 的方式,而且让容器共享 GPU。FPGA 类似。)
需要相应资源的负载要设置 nodeSelector
nodeSelector:
x-has-vfpga: yes
值得注意的是,Kubernetes 会在每个节点上自动增加
kubernetes.io/os: [windows|linux]
的标签。
由于 Windows 容器只能在 Windows 上运行,而 Linux 容器只能在 Linux 上运行,所以需要给 Windows 节点抹上污点 os=windows:NoSchedule。
所有需要运行在 Windows 上的负载均加上 nodeSelector 和污点容忍:
nodeSelector:
kubernetes.io/os: windows
tolerations:
- key: "os"
operator: "Equal"
value: "windows"
effect: "NoSchedule"
应用的云原生改造
由于医院现有应用的开发时间远近不一,多多少少存在着云原生的反模式。
日志方面:由输出到文件改成到 stdout(会被日志采集服务自动采走)。所幸原来的开发人员素养还行,没有把日志输出目标写死。
配置文件方面:由 ConfigMap 和 Secret 管理。
监控支持:Spring Boot 项目添加了比较完整的 Prometheus 支持,老项目(用 Struts2)捏着鼻子好歹添加了几个支持 Prometheus 查询的指标。Django 项目添加 Prometheus 支持。
其他细节:程序配置的数据库地址从原来的内网域名改为了 Service 名;开关类的配置改为由环境变量获取。
为应用提供云的支持
DevOps:在改造程序并准备好云环境后,就可以将应用通过 DevOps 功能部署到云。在操作界面新建流水线,编写构建、部署流程,设置好触发方式(手动、定时、Gitlab 的 WebHook),应用就被部署到了 Kubernetes 集群中。
监控与告警:部署完应用之后,就可以在监控界面看到节点、Kubernetes 集群、负载(各个应用)的各项指标,如 CPU 使用、内存占用、网络占用、应用的健康程度、调度器的频率、etcd 的大小与吞吐、数据库的连接情况等等。然后给部分指标设置了告警,如内存占用超过一定数值就发送钉钉消息,JVM 内存中对象数突然升高发送邮件,等等。
日志支持:云提供的日志服务可以方便地查询、搜索、筛选日志,供排查问题用。比看那个黑窗口或日志文本好用多了。后续(开发中)还会有机器学习日志分析功能,用来推断故障出在哪。
结束语
以上便是这家医院上云的全过程。对医院疑问的解答也包含在上述过程中。
上云过程的难点就是在折腾的过程中要顶一下来自医院的压力和质疑。而在医院看到上云后物理机使用数减少约 1/3 后,态度则转变为欣喜和信任。云的强大功能(监控、日志、DevOps、微服务与服务网格、中间件等)又进一步给产品添彩。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号