
kubernetes集群故障恢复
前提概要:该k8s集群为测试集群
故障报错1:

排障:
[root@novel-master ~]# crictl --runtime-endpoint=unix:///var/run/cri-dockerd.sock ps -a|grep api
2193829141eb7 9dc6939e7c573 14 hours ago Running kube-apiserver 2 18ead36dfb7b0 kube-apiserver-novel-master
a8f6069063087 9dc6939e7c573 4 days ago Exited kube-apiserver 1 2e7669cd71112 kube-apiserver-novel-master
查询kube-apiserver服务状态:

可以看出cni使用了docker和cri-dockerd两种,所以涉及:unix:///run/containerd/containerd.sock unix:///var/run/cri-dockerd.sock两个
查询etcd服务状态:

etcd的数据文件损坏了,要做数据恢复,而我这是实验环境,没搞etcd备份就只能重置集群了
需要在每台机器上执行:
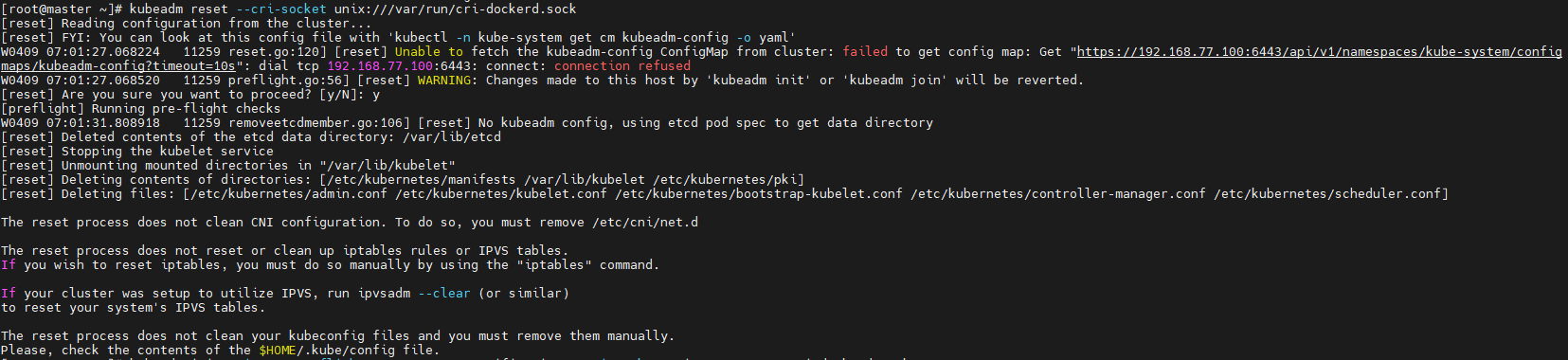
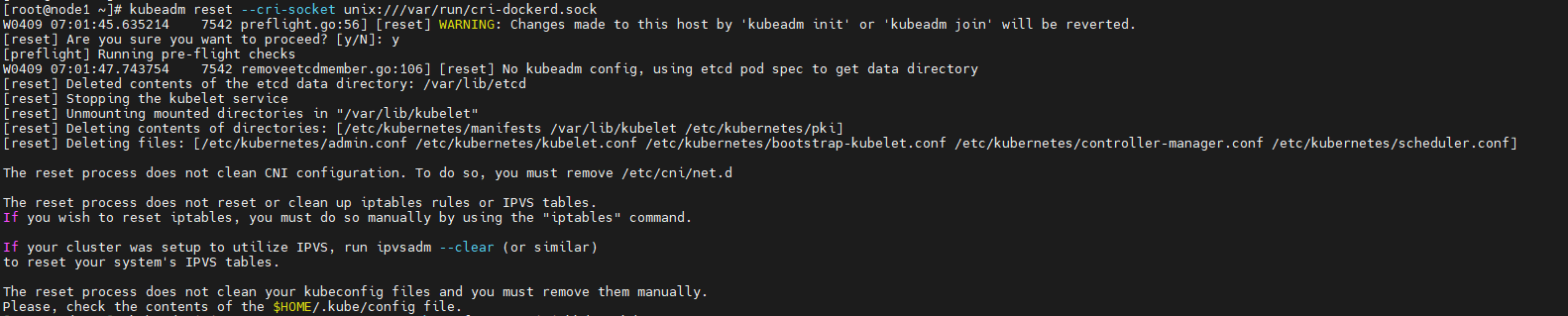

然后初始化集群:
在master节点执行:
[root@master ~]# kubeadm init --ignore-preflight-errors=SystemVerification --cri-socket unix:///var/run/cri-dockerd.sock I0409 07:02:10.310074 11794 version.go:256] remote version is much newer: v1.29.3; falling back to: stable-1.28 [init] Using Kubernetes version: v1.28.8 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
如果遇到报错:
[ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables contents are not set to 1
解决办法:# echo "1">/proc/sys/net/bridge/bridge-nf-call-iptables
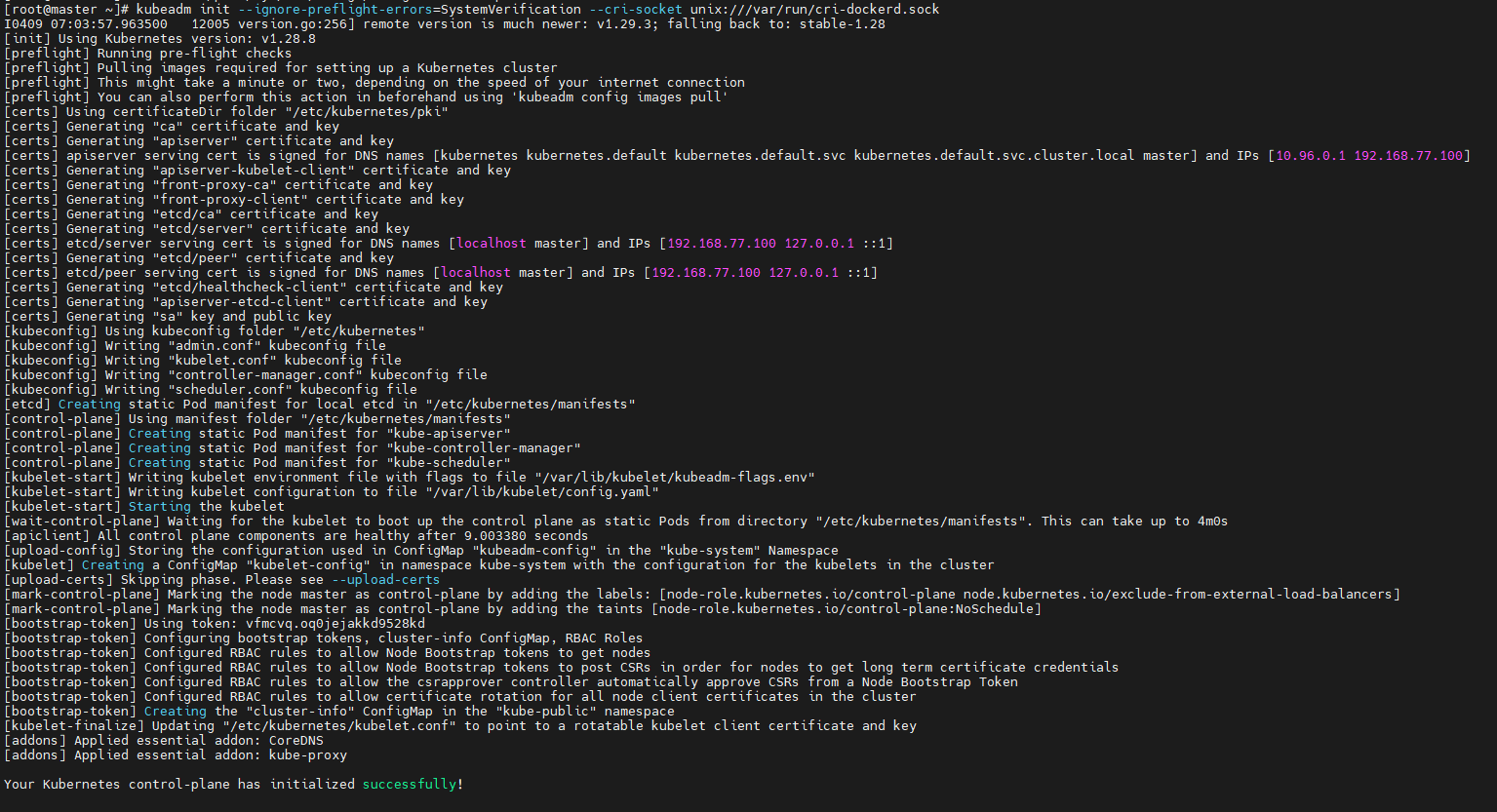
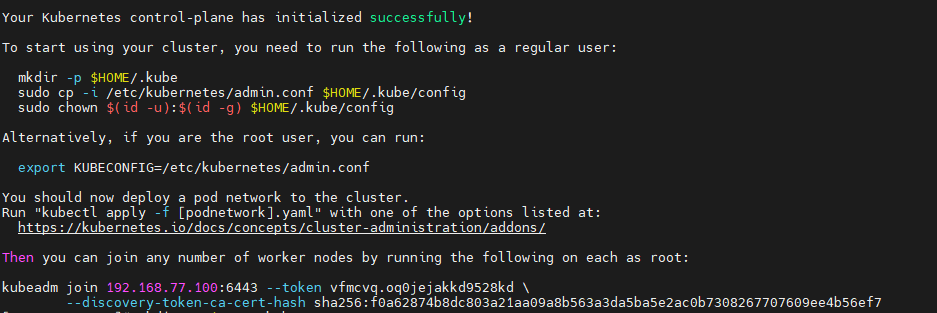
当出现上面信息时,表示init初始化成功,然后在node1、node2节点进行加入到节点:
[root@master ~]# mkdir -p $HOME/.kube [root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config [root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane 82s v1.28.2 node1 Ready <none> 17s v1.28.2 node2 Ready <none> 6s v1.28.2
但是执行kubectl apply -f kube-flannel.yml一直报错:

Error registering network: failed to acquire lease: node "master" pod cidr not assigned
报错信息是cidr没有分配,于是继续reset,然后init的时候加上该参数:
[root@master ~]# kubeadm init --ignore-preflight-errors=SystemVerification --cri-socket unix:///var/run/cri-dockerd.sock --service-cidr=10.96.0.0/16 --pod-network-cidr=10.244.0.0/16
然后node1、node2继续join:
[root@node1 ~]# kubeadm join 192.168.77.100:6443 --token caidkf.z5ygdrotujz09y1z \ > --discovery-token-ca-cert-hash sha256:a753ca9b794a43912b3bfca5e52a788ca222e672a3630879b585f2eb841fc65e --cri-socket unix:///var/run/cri-dockerd.sock [root@node2 ~]# kubeadm join 192.168.77.100:6443 --token caidkf.z5ygdrotujz09y1z \ > --discovery-token-ca-cert-hash sha256:a753ca9b794a43912b3bfca5e52a788ca222e672a3630879b585f2eb841fc65e --cri-socket unix:///var/run/cri-dockerd.sock
然后master节点做一些config配置:
[root@master ~]# rm -rf /root/.kube/* [root@master ~]# mkdir -p $HOME/.kube [root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
集群状态,pod状态如下:
[root@master ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION master Ready control-plane 59s v1.28.2 node1 Ready <none> 22s v1.28.2 node2 Ready <none> 27s v1.28.2

如果上述过程中出现如下报错:
[root@master ~]# kubectl get nodes Unable to connect to the server: tls: failed to verify certificate: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes") [root@master ~]# kubectl get nodes Unable to connect to the server: tls: failed to verify certificate: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
解决办法:
先删除config缓存,然后创建新的:
[root@master ~]# rm -rf /root/.kube/* [root@master ~]# mkdir -p $HOME/.kube [root@master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config [root@master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
故障:node节点不正常,kebelet服务挂了,cri-docker服务也启动失败,docker服务启动也失败
kebelet服务依赖于cri-docker服务依赖于docker服务:
[root@node4 ~]# journalctl -u docker.service -- Logs begin at Wed 2024-07-24 10:26:44 EDT, end at Wed 2024-07-24 11:19:06 EDT. -- Jul 24 10:26:56 node4 systemd[1]: Starting Docker Application Container Engine... Jul 24 10:26:58 node4 dockerd[1102]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'ï' after object key:value pair Jul 24 10:26:58 node4 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE Jul 24 10:26:58 node4 systemd[1]: Failed to start Docker Application Container Engine. Jul 24 10:26:58 node4 systemd[1]: Unit docker.service entered failed state. Jul 24 10:26:58 node4 systemd[1]: docker.service failed. Jul 24 10:27:00 node4 systemd[1]: docker.service holdoff time over, scheduling restart. Jul 24 10:27:00 node4 systemd[1]: Stopped Docker Application Container Engine. Jul 24 10:27:00 node4 systemd[1]: Starting Docker Application Container Engine... Jul 24 10:27:00 node4 dockerd[1462]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'ï' after object key:value pair Jul 24 10:27:00 node4 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE Jul 24 10:27:00 node4 systemd[1]: Failed to start Docker Application Container Engine. Jul 24 10:27:00 node4 systemd[1]: Unit docker.service entered failed state. Jul 24 10:27:00 node4 systemd[1]: docker.service failed. Jul 24 10:27:02 node4 systemd[1]: docker.service holdoff time over, scheduling restart. Jul 24 10:27:02 node4 systemd[1]: Stopped Docker Application Container Engine. Jul 24 10:27:02 node4 systemd[1]: Starting Docker Application Container Engine... Jul 24 10:27:03 node4 dockerd[1469]: unable to configure the Docker daemon with file /etc/docker/daemon.json: invalid character 'ï' after object key:value pair Jul 24 10:27:03 node4 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE Jul 24 10:27:03 node4 systemd[1]: Failed to start Docker Application Container Engine. Jul 24 10:27:03 node4 systemd[1]: Unit docker.service entered failed state. Jul 24 10:27:03 node4 systemd[1]: docker.service failed. Jul 24 10:27:05 node4 systemd[1]: docker.service holdoff time over, scheduling restart. Jul 24 10:27:05 node4 systemd[1]: Stopped Docker Application Container Engine.
从错误表示/etc/docker/daemon.json这个文件出现格式错误,如果实在不知道哪里出问题,可以参考其他节点,也可以删掉,直接清空该文件
[root@node4 ~]# systemctl daemon-reload [root@node4 ~]# systemctl start docker [root@node4 ~]# systemctl status docker ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2024-07-24 11:20:07 EDT; 5s ago Docs: https://docs.docker.com Main PID: 4652 (dockerd) Tasks: 17 Memory: 55.9M CGroup: /system.slice/docker.service └─4652 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
docker服务启动正常后,就可以启动其他服务了
[root@node4 ~]# systemctl start cri-docker [root@node4 ~]# systemctl status cri-docker ● cri-docker.service - CRI Interface for Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/cri-docker.service; disabled; vendor preset: disabled) Active: active (running) since Wed 2024-07-24 11:20:28 EDT; 7s ago Docs: https://docs.mirantis.com Main PID: 4864 (cri-dockerd) Tasks: 32 Memory: 119.6M CGroup: /system.slice/cri-docker.service ├─4864 /usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 ├─5130 /opt/cni/bin/calico ├─5135 /opt/cni/bin/calico ├─5140 /opt/cni/bin/calico ├─5147 /opt/cni/bin/calico └─5151 /opt/cni/bin/calico
[root@node4 ~]# systemctl status kubelet ● kubelet.service - kubelet: The Kubernetes Node Agent Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/kubelet.service.d └─10-kubeadm.conf Active: active (running) since Wed 2024-07-24 11:20:34 EDT; 22s ago Docs: https://kubernetes.io/docs/ Main PID: 4946 (kubelet) Tasks: 11 Memory: 45.0M CGroup: /system.slice/kubelet.service └─4946 /usr/bin/kubele
参考文章:
https://zhuanlan.zhihu.com/p/646238661
https://blog.csdn.net/qq_40460909/article/details/114707380
https://blog.csdn.net/qq_21127151/article/details/120929170
k8s集群重置方法2:
master:kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
node其他节点:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号