强化学习 5 —— SARSA 和 Q-Learning算法代码实现
上篇文章 强化学习——时序差分 (TD) --- SARSA and Q-Learning 我们介绍了时序差分TD算法解决强化学习的评估和控制问题,TD对比MC有很多优势,比如TD有更低方差,可以学习不完整的序列。所以我们可以在策略控制循环中使用TD来代替MC。优于TD算法的诸多优点,因此现在主流的强化学习求解方法都是基于TD的。这篇文章会使用就用代码实现 SARSA 和 Q-Learning 这两种算法。
一、算法介绍
关于SARSA 和 Q-Learning算法的详细介绍,本篇博客不做过多介绍,若不熟悉可点击文章开头链接查看。
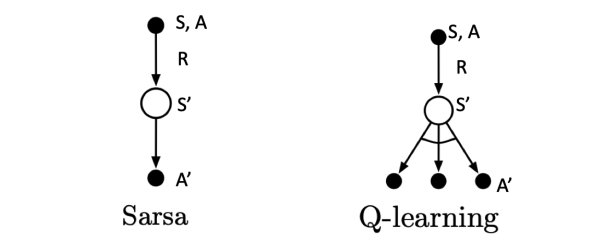
Sarsa 和 QLearning 时序差分TD解决强化学习控制问题的两种算法,两者非常相似,从更新公式就能看出来:
- SARSA:
- Q-Learning
可以看出来,两者的区别就在计算 TD-Target 的时候,下一个动作 a' 是如何选取的
对于 Sarsa 来说:
- 1)在状态 s' 时,就知道了要采取那个动作 a',并且真的采取了这个动作
- 2)当前动作 a 和下一个动作 a' 都是 根据 \(\epsilon\) -贪婪策略选取的,因此称为on-policy学习
对于 Q-Learning:
- 1)在状态s'时,只是计算了 在 s' 时要采取哪个 a' 可以得到更大的 Q 值,并没有真的采取这个动作 a'。
- 2)动作 a 的选取是根据当前 Q 网络以及 \(\epsilon\)-贪婪策略,即每一步都会根据当前的状况选择一个动作A,目标Q值的计算是根据 Q 值最大的动作 a' 计算得来,因此为 off-policy 学习。
二、代码
1、SARSA
定义 SARSA agent 类,
class Sarsa:
def __init__(self, state_dim, action_dim, lr=0.01, gamma=0.9, e_greed=0.1):
self.action_dim = action_dim
self.lr = lr
self.gamma = gamma
self.epsilon = e_greed
self.Q = np.zeros((state_dim, action_dim))
def sample(self, state):
"""
使用 epsilon 贪婪策略获取动作
return: action
"""
if np.random.uniform() < self.epsilon:
action = np.random.choice(self.action_dim)
else: action = self.predict(state)
return action
def predict(self, state):
""" 根据输入观察值,预测输出的动作值 """
all_actions = self.Q[state, :]
max_action = np.max(all_actions)
# 防止最大的 Q 值有多个,找出所有最大的 Q,然后再随机选择
# where函数返回一个 array, 每个元素为下标
max_action_list = np.where(all_actions == max_action)[0]
action = np.random.choice(max_action_list)
return action
def learn(self, state, action, reward, next_state, next_action, done):
"""
更新 Q-table 方法
next_action 就是下一步选的动作,所以直接用 self.Q[next_state, next_action]
然后计算 td-target,然后更新 Q-table
"""
if done: target_q = reward
else:
target_q = reward + self.gamma * self.Q[next_state, next_action]
self.Q[state, action] += self.lr * (target_q - self.Q[state, action])
上面代码重点是 learn() 方法中的 Q-table 的更新,结合公式还是比较容易理解的。下面是每一个 episode 的流程:对于一个 episode 先调用 reset() 方法获得初始化状态state,然后选择当前的动作 action ,使用当前的动作让环境执行一步,获取到下一个状态 next_state 以及奖励 reward ,然后利用这些数据进行更新Q表格,注意 更新之后要把下一个状态和动作赋值给当前的状态和动作,然后循环。
def run_episode(self, render=False):
state = self.env.reset()
action = self.model.sample(state)
while True:
next_state, reward, done, _ = self.env.step(action)
next_action = self.model.sample(next_state)
# 训练 Q-learning算法
self.model.learn(state, action, reward, next_state, next_action, done)
state = next_state
action = next_action
if render: self.env.render()
if done: break
完整代码见强化学习——SARSA 算法 ,劳烦大人点个 star 可好?
2、Q-Learning
由上可知,Q-Learning 和 SARSA 算法很相似,代码几乎相同,下面就展示下与 SARSA 算法不同的部分
class QLearning:
# ...
# 其他方法见 SARSA 部分
def learn(self, state, action, reward, next_state, done):
"""
Q-Learning 更新 Q-table 方法
这里没有明确选择下一个动作 next_action, 而是选择 next_state 下有最大价值的动作
所以用 np.max(self.Q[next_state, :]) 来计算 td-target
然后更新 Q-table
"""
if done:
target_q = reward
else:
target_q = reward + self.gamma * np.max(self.Q[next_state, :])
self.Q[state, action] += self.lr * (target_q - self.Q[state, action])
对于 Q-Learning 的算法流程部分 ,和 SARSA 也有些细微区别:在Q-Learning 中的 learn() 方法不需要传入 next_action 参数,因为在计算td-target 时只是查看了一下下一个状态的所有动作价值,并选择一个最优动作让环境去执行。还请仔细区分两者的不同:
def run_episode(self, render=False):
state = self.env.reset()
while True:
action = self.model.sample(state)
next_state, reward, done, _ = self.env.step(action)
# 训练 Q-learning算法
self.model.learn(state, action, reward, next_state, done)
state = next_state
if render: self.env.render()
if done: break
完整代码见强化学习——Q-Learning 算法,劳烦大人点个 star 可好?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号