强化学习 4 —— 时序差分法(TD)解决无模型预测与控制问题
在上篇文章强化学习——蒙特卡洛 (MC) 采样法的预测与控制中我们讨论了 Model Free 情况下的策略评估问题,主要介绍了蒙特卡洛(MC)采样法的预测与控制问题,这次我们介绍另外一种方法——时序差分法(TD)
一、时序差分采样法(TD)
对于MC采样法,如果我们没有完整的状态序列,那么就无法使用蒙特卡罗法求解了。当获取不到完整状态序列时, 可以使用时序差分法(Temporal-Difference, TD)。
1、TD 简介
对于蒙特卡洛采样法计算状态收益的方法是:
而对于时序差分法来说,我们没有完整的状态序列,只有部分的状态序列,那么如何可以近似求出某个状态的收获呢?回顾贝尔曼方程:
我们可以用 \(R_{t+1} + \gamma v_\pi(S_{t+1})\) 近似代替 \(G_t\) ,此时有:
-
一般把 \(R_{t+1} + \gamma v(S_{t+1})\) 叫做 TD Target
-
把叫做 \(R_{t+1} + \gamma v(S_{t+1})-v(S_t)\) TD Error
-
把 用 TD Target 近似的代替 Gt 的过程称为 引导(Bootstraping)
这样一来,这样我们只需要两个连续的状态与对应的奖励,就可以尝试求解强化学习问题了。
2、n步时序差分
在上面我们用 $ R_{t+1} + \gamma v_\pi(S_{t+1})$ 近似代替 \(G_t\) 。即向前一步来近似收获 \(G_t\),那我们能不能向前两步呢?当然是可以的,此时 \(G_t\) 近似为:
近似价值函数 \(v(S_t)\) 为:
从两步,到三步,再到n步,我们可以归纳出n步时序差分收获 \(G_t^{(n)}\)的表达式为:
往前走两步时,对应的算法叫 TD(2) ,往前走三步时,对应的算法叫 (TD3) 。当n越来越大,趋于无穷,或者说趋于使用完整的状态序列时,n步时序差分就等价于蒙特卡罗法了。特别的对于往前走一步的算法,我们叫 TD(0)。
3、TD小结
TD 对比 MC:
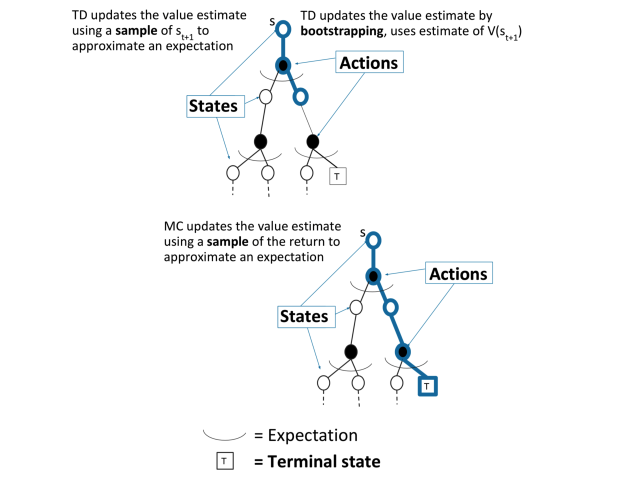
- TD在知道结果之前就可以学习,也可以在没有结果时学习,还可以在持续进行的环境中学习,而MC则要等到最后结果才能学习,时序差分法可以更快速灵活的更新状态的价值估计。
- TD在更新状态价值时使用的是TD 目标值,即基于即时奖励和下一状态的预估价值来替代当前状态在状态序列结束时可能得到的收获,是当前状态价值的有偏估计,而MC则使用实际的收获来更新状态价值,是某一策略下状态价值的无偏估计,这点 MC 优于 TD。
- 虽然TD得到的价值是有偏估计,但是其方差却比MC得到的方差要低,且对初始值敏感,通常比MC更加高效。
二、TD 解决控制问题
我们知道,TD对比MC有很多优势,比如TD有更低方差,可以学习不完整的序列。所以我们可以在策略控制循环中使用TD来代替MC。因此现在主流的强化学习求解方法都是基于TD的,下面我们就介绍两种最常用的算法,分别是 Sarsa 和 Q-Learning
1、Sarsa:
对于一个动作序列如下图所示:
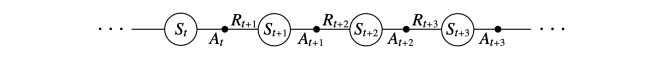
在迭代的时候,我们基于 \(\epsilon\) -贪婪法在当前状态 \(S_t\) 选择一个动作 \(A_t\), 然后会进入到下一个 状态 \(S_{t+1}\),同时获得奖励 \(R_{t+1}\),在新的状态 \(S_{t+1}\) 我们同样基于 \(\epsilon\)-贪婪法选择一个动作 \(A_{t+1}\),然后用它来更新我们的价值函数,更新公式如下:
-
注意:这里我们选择的动作 \(A_{t+1}\),就是下一步要执行的动作,这点是和Q-Learning算法的最大不同
-
TD Target \(\delta_t = R_{t+1} + \gamma Q(S_{t+1}, A_{t+1})\)
-
在每一个 非终止状态 \(S_t\) 都要更新
-
进行一次更新,我们要获取5个数据,\(<S_t, A_t, R_{t+1}, S_{t+1}, A_{t+1}>\) ,这也是算法名字 Sarsa 的由来
Sarsa算法流程如下

n-step Sarsa
上面的 Sarsa 算法是我们每向前走一步就更新,其实可以 类比 TD,可以向前走多步然后进行更新,就叫 n-step Sarsa
其中 \(q_{(n)}\) 为:
2、On-policy 和 Off-policy
比如上面的 Sarsa 算法就是一个 On-Policy 算法。从更新公式可以看出,Sarsa 算法的探索使用 \(\epsilon-\)贪婪法,而更新value 的动作也是带有 \(\epsilon\) 的探索。也就是说探索和更新 \(V(s)\) 是用的同一种策略 \(\pi\) ,我们就叫 同策略学习(On-Policy Learning)。
而另外一个重要的方法就是Off-Policy Learning ,也就是异策略学习。在异策略学习算法中,我们有两个不同的策略,一个策略 \(\pi\) 是获取最优的 \(V(s)\) (比如使用贪心法),我们称为 target policy。而另外一个 策略 \(\mu\) 是为了生成不同的轨迹,同时拥有更多的探索性(比如 \(\epsilon-\)贪婪法),我们称为 behavior policy。
强化学习过程主要是探索和利用 的问题。如何更好的探索环境以采集轨迹,以及如何利用采集到的轨迹经验。Off Policy 其实就是把探索和优化 一分为二,优化的时候我只追求最大化,二不用像 On Policy 那样还要考虑 epsilon 探索,所以Off Policy 的优点就是可以更大程度上保证达到全局最优解。
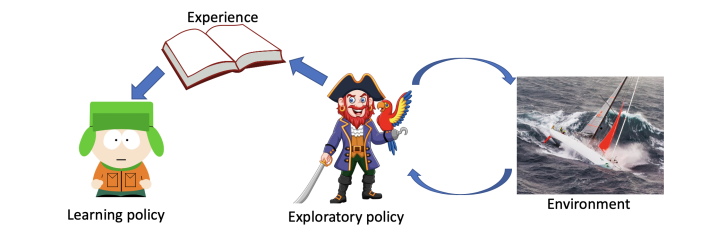
如上图所示,就是一个 Off policy 很好的比喻。海盗更具有冒险精神,他可以把与风浪(环境)中获得的轨迹(或者经验)保留下来,然后其的小白就可以利用这些经验来学习如何更好的在海上航行。对于 On-policy,每次更新之后,策略都会发生变化,所以之前产生的 交互数据已经没有价值了,我们要废弃掉,再重新产生新的交互数据。而Off Policy 在这方面就有着优势,他可以反复的利用以前过往的数据,因为他的目标策略和行为策略是分离的。而 Q-Learning 就是一个 Off-Policy 算法。
3、Q-Learning
对于Q-Learning,我们会使用 \(\epsilon-\)贪婪法来选择新的动作,这部分和SARSA完全相同。但是对于价值函数的更新,Q-Learning使用的是贪婪法,而不是SARSA的 \(\epsilon-\)贪婪法。这一点就是SARSA和Q-Learning本质的区别。
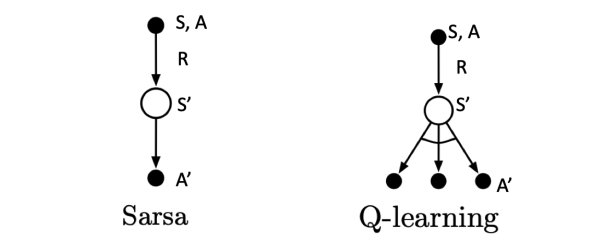
首先我们基于状态 \(S_t\),用 \(\epsilon-\)贪婪法选择到动作 \(A_t\), 然后执行动作 \(A_t\),得到奖励\(R_{t}\),并进入状态\(S_{t+1}\),对于 Q-Learning,它基于状态 \(S_{t+1}\) 没有用 \(\epsilon-\)贪婪法选择到动作 \(A'\), 而是使用贪心策略选择 \(A'\) 。也就是选择使\(Q(S_{t+1}, a)\) 最大的 \(a\) 来作为 \(A'\) 来更新价值函数。对应到上图中就是在图下方的三个黑圆圈动作中选择一个使\(Q(S', a)\) 最大的动作作为 \(A'\) 。注意: 此时选择的动作只会参与价值函数的更新,不会真正的执行。
- 对于 behavior policy \(\mu\) 使用 \(\epsilon-\) 贪心策略
- 对于 target policy \(\pi\) 使用贪心策略选取
因此 Q-Learning Target :
Q-Learning 的更新式子如下:
Q-Learning 算法

4、Sarsa VS Q-learning
作为时序差分法控制算法的两个经典的算法,他们各自有特点。
Q-Learning直接学习的是最优策略,而Sarsa在学习最优策略的同时还在做探索。这导致我们在学习最优策略的时候,如果用Sarsa,为了保证收敛,需要制定一个策略,使 \(\epsilon-\)贪婪法的超参数 \(\epsilon\) 在迭代的过程中逐渐变小。Q-Learning没有这个烦恼。
另外一个就是Q-Learning直接学习最优策略,但是最优策略会依赖于训练中产生的一系列数据,所以受样本数据的影响较大,因此受到训练数据方差的影响很大,甚至会影响Q函数的收敛。Q-Learning的深度强化学习版Deep Q-Learning也有这个问题。
在学习过程中,Sarsa在收敛的过程中鼓励探索,这样学习过程会比较平滑,不至于过于激进,而 Q-Learning 是直接选择最优的动作,相比于 Sarsa 算法更激进。
比如在 Cliff Walk 问题中,如下所示,Sarsa 算法会走蓝色的安全线,而激进的 Q-Learning 算法则会选择红色的最优路线。(其中灰色部分是悬崖)
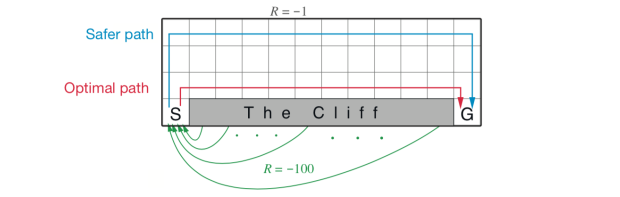
关于 Sarsa 和 Q-Learning 算法的代码详解可以看下一篇文章强化学习——Sarsa 和 Q-Learning 算法实战
三、DP、MC、TD的对比
1 有无 Bootstrapping 和 Sampling
| Bootstrapping | Sampling | |
|---|---|---|
| DP | Yes | |
| MC | Yes | |
| TD | Yes | Yes |
2、DP 和 TD

3 对于三种算法的直观理解
- DP
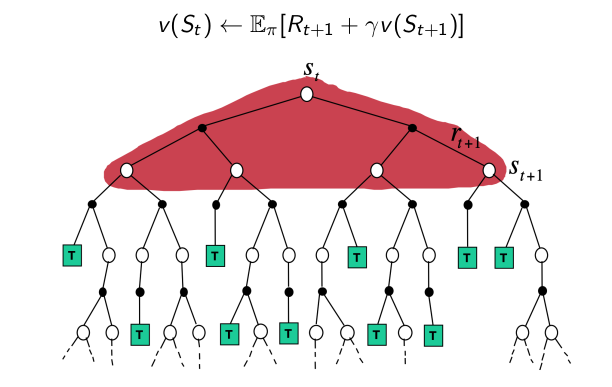
- MC
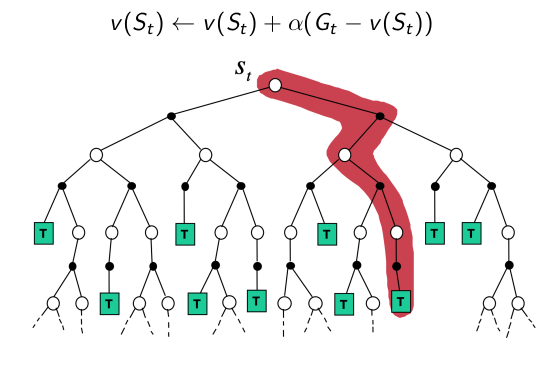
- TD
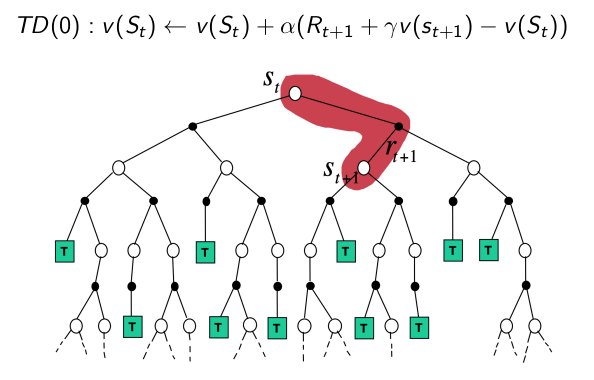
3 三种算法之间的关系
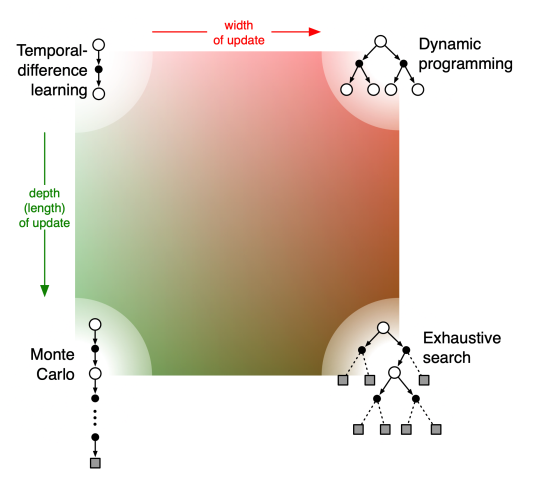
上图是强化学习方法空间的一个横切面,突出两个重要维度:更新的深度和宽度
这两个维度是与改善价值函数的更新操作的类型联系在一起的。水平方向代表的是:使用采样更新(基于一个采样序列)还是期望更新(基于可能序列的分布)。期望更新需要一个概率分布模型,采样更新只需要一个采样模型即可。
垂直方向对应的是更新的深度,也是“自举(bootstrap)”的程度。从单步时序差分更新到蒙特卡洛更新。中间部分包括了基于 n 步更新的方法(例如基于资格迹的 \(\lambda\) 更新)
可以看到,动态规划在图示空间的右上方,因为动态规划属于单步期望更新。右下角是期望更新的一个极端情况,每次更新都会遍历虽有可能情况直到到达最后的终止状态(或者在持续任务中,折扣因子的类乘导致之后的收益对当前回报不再有影响为止)。这是启发式搜索中的一中情况。
—— 《强化学习》第二版 Sutton
至此,传统的强化学习基本理论就介绍完了,下一篇是SARSA 和Q-Learning算法的代码介绍。当然本系列博客比较基本,若想更深入了解可以读 Sutton 的《强化学习》这本手,这本书英文电子版云盘地址 提取码: hn77。
最近这几年,随着神经网络的兴起,基于神经网络的强化学习发展的如火如荼,出现了许多新的有意思的算法,当然也更加的强大。所以接下来的文章都是介绍 神经网络 + 强化学习,也就是深度强化学习(DRL)。我这枚菜鸟也会尽自己最大所能,给大家讲解清楚,还请大家不要走开,多多关注!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号