分布式事务解决方案总结
分布式事务
两阶段提交协议
两阶段提交协议是用来处理分布式事务的。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。 两阶段提交的算法如下:
第一阶段:
- 协调者会问所有的参与者结点,是否可以执行提交操作。
- 各个参与者开始事务执行的准备工作:如:为资源上锁,预留资源,写undo/redo log……
- 参与者响应协调者,如果事务的准备工作成功,则回应“可以提交”,否则回应“拒绝提交”。
第二阶段:
- 如果所有的参与者都回应“可以提交”,那么,协调者向所有的参与者发送“正式提交”的命令。参与者完成正式提交,并释放所有资源,然后回应“完成”,协调者收集各结点的“完成”回应后结束这个Global Transaction。
- 如果有一个参与者回应“拒绝提交”,那么,协调者向所有的参与者发送“回滚操作”,并释放所有资源,然后回应“回滚完成”,协调者收集各结点的“回滚”回应后,取消这个Global Transaction。
2PC说白了就是第一阶段做Vote,第二阶段做决定的一个算法,也可以看到2PC这个事是强一致性的算法。
两段提交最大的问题就是,如果第一阶段完成后,参与者在第二阶没有收到决策,那么数据结点会进入“不知所措”的状态,这个状态会block住整个事务。也就是说,协调者Coordinator对于事务的完成非常重要,Coordinator的可用性是个关键。 因些,我们引入三段提交,三段提交在Wikipedia上的描述如下,他把二段提交的第一个段break成了两段:询问,然后再锁资源。最后真正提交。三段提交的示意图如下:
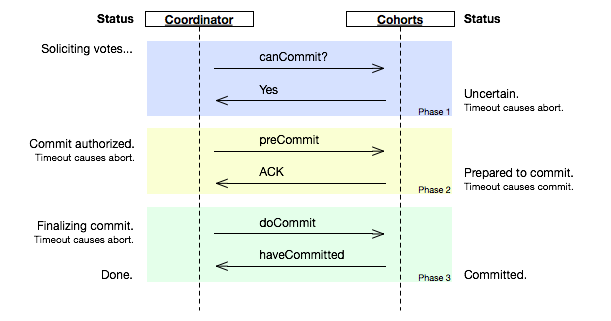
三段提交的核心理念是:在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源。
一个网络服务会有三种状态:1)Success,2)Failure,3)Timeout,第三个绝对是恶梦,尤其在你需要维护状态的时候。
Paxos 算法
Paxos 算法解决的问题是在一个可能发生上述异常的分布式系统中如何就某个值达成一致,保证不论发生以上任何异常,都不会破坏决议的一致性。
Paxos 一般也分为两个阶段:
- prepare 阶段
- proposer选择一个提案编号n并将prepare请求发送给acceptors中的一个多数派;
- acceptor收到prepare消息后,如果提案的编号大于它已经回复的所有prepare消息,则acceptor将自己上次接受的提案回复给proposer,并承诺不再回复小于n的提案;
- 批准阶段
- 当一个proposer收到了多数acceptors对prepare的回复后,就进入批准阶段。它要向回复prepare请求的acceptors发送accept请求,包括编号n和根据P2c决定的value(如果根据P2c没有已经接受的value,那么它可以自由决定value)。
- 在不违背自己向其他proposer的承诺的前提下,acceptor收到accept请求后即接受这个请求。
本地消息表
这种实现方式的思路,其实是源于ebay,后来通过支付宝等公司的布道,在业内广泛使用。其基本的设计思想是将远程分布式事务拆分成一系列的本地事务。如果不考虑性能及设计优雅,借助关系型数据库中的表即可实现。
举个经典的跨行转账的例子来描述。
第一步扣款 1W,通过本地事务保证了凭证消息插入到消息表中。
第二步,通知对方银行账户上加 1W 了。那问题来了,如何通知到对方呢?
通常采用两种方式:
- 采用时效性高的 MQ,由对方订阅消息并监听,有消息时自动触发事件
- 采用定时轮询扫描的方式,去检查消息表的数据。
两种方式其实各有利弊,仅仅依靠MQ,可能会出现通知失败的问题。而过于频繁的定时轮询,效率也不是最佳的(90%是无用功)。所以,我们一般会把两种方式结合起来使用。
解决了通知的问题,还需要保证不重复打款,也就是接到重复 MQ 消息时,要保证幂等。
TCC 事务
TCC分别对应Try、Confirm和Cancel三种操作,这三种操作的业务含义如下:
- Try:预留业务资源
- Confirm:确认执行业务操作
- Cancel:取消执行业务操作
TCC事务的优点如下:
- 解决了跨应用业务操作的原子性问题,在诸如组合支付、账务拆分场景非常实用。
- TCC实际上把数据库层的二阶段提交上提到了应用层来实现,对于数据库来说是一阶段提交,规避了数据库层的2PC性能低下问题(长期持有锁)。
TCC事务的缺点:TCC的Try、Confirm和Cancel操作功能需业务提供,开发成本高。
Saga 模式
Saga 也是应用层事务,相比 TCC 少了 Try 这一步,更加简单。Saga 中某一个事务失败后,有两种解决方法:回滚已经成功的事务、重试失败的事务。
目前有一个为 Java 编写的开源 Saga 框架:Tram。
阿里的分布式事务处理方案 GTS
分布式事务解决方案面临应用灵活性、数据一致性、性能三者的挑战。目前已有多种成熟方案,每种方案都是对这三个方面做出的取舍。
GTS采用基于XA架构优化的技术路线,在保留XA架构灵活性的优点下,通过将XA提交中的第一阶段与第二阶段解耦,将提交过程转换为第一阶段本地事务提交+第二阶段异步清理的方式,从而提供提升系统性能,同时通过在GTS内部维护应用级别的日志与锁信息,实现了全局事务的回滚与并发控制。
GTS方案认为XA性能低效的根本原因是采用了阻塞协议。在分布式事务提交的第一阶段等待最慢的一个事务分支完成,即使在不存在锁冲突的情况下,各事务分支的数据库连接依然会被挂起所占用的资源都不能够释放,以防止全局事务提交前释放资源所造成的数据不一致。
GTS 的缺省事务隔离级别为读未提交,该模式下可以达到分布式事务的最大性能,但可能会读到脏数据。对于一致性要求高的应用,在性能允许的情况下,可以采用已提交读语句(for update、lock in share mode)将隔离级别提升至读已提交。
GTS是一个优秀的最终一致性方案。可以读到脏数据,但是修改操作会加GTS锁。也就是把数据库层面的锁移到了中间件层,并对两阶段提交中的大锁拆分成了多个小锁,从而提高了性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号