

HBase基本架构和原理
1.概述
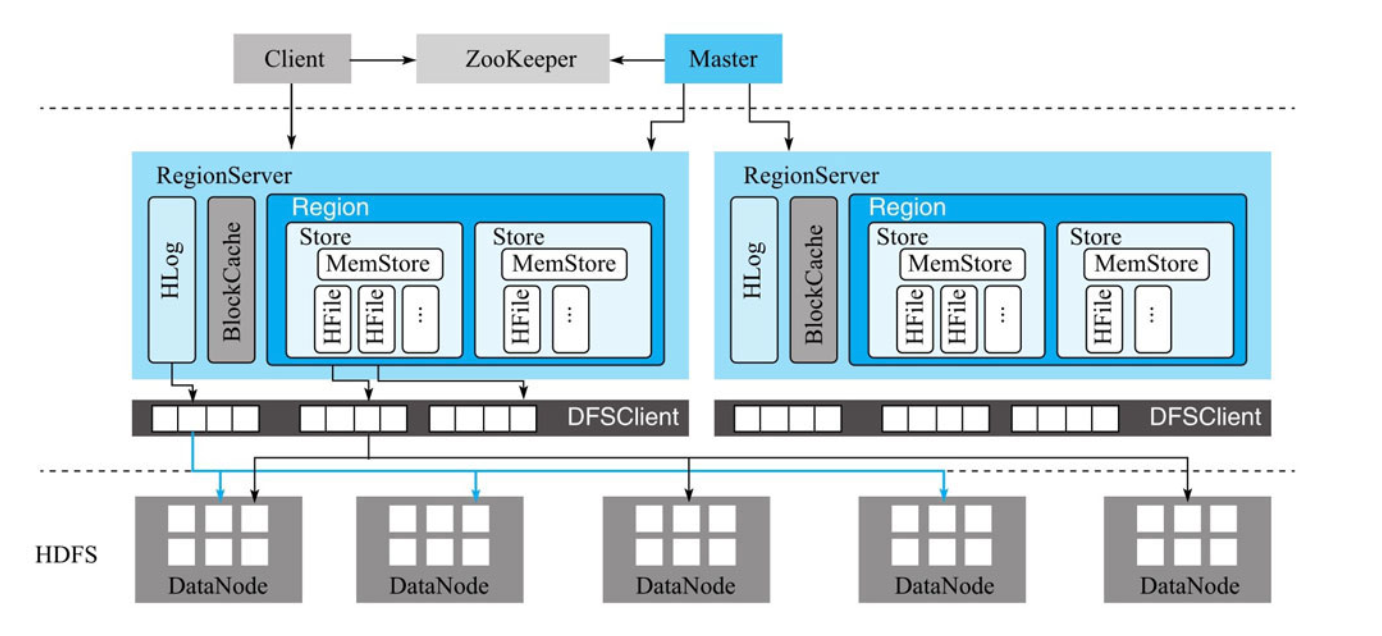
HBase是典型的Master-Slave模型,系统中有一个Master节点和多个RegionServer节点,此外,存储借助HDFS来实现,同时通过Zookeeper来协助Master对集群进行管理,结构如下图所示:
2.客户端
Client提供Shell命令行接口、原生Java API编程接口、Thrift/REST API编程接口以及MapReduce编程接口,支持常见的DML(增删改查)操作和DDL(表的维护)操作
在客户端访问数据行之前,先通过元数据表定位所要访问的数据所在的RegionServer,同时将元数据缓存在Client本地,如果数据发生了迁移,需要重新请求并缓存
3.Zookeeper
Zookeeper在HBase的主要功能有:
- 保证Master高可用:如果Master宕机,Zookeeper会检测到该事件并选举出新的Master,保证系统正常运转
- 管理元数据
- 保证RegionServer宕机恢复:通过心跳感知是否宕机,如果宕机通知Master处理
- 实现分布式表锁:对一个表进行操作时需要先加表锁,Zookeeper通过特定机制可以实现分布式表锁
4.Master
Master主要负责管理工作:
- 处理用户的各种请求
- 管理集群中的所有RegionServer
- 清理过期日志和文件等
5.RegionServer
RegionServer主要响应用户的读写请求,由WAL(HLog)、BlockCache和多个Region组成
- WAL(HLog):HLog主要有两个作用,第一点是实现数据的高可靠性,HBase数据随机写入时,会先写入缓存,再异步刷新落盘。为了防止缓存数据丢失,写入缓存之前需要首先顺序写入HLog,即使缓存数据丢失,也可以通过HLog日志来进行恢复,第二点是实现HBase集群间的主从复制,通过将主集群的HLog日志进行回放来实现复制功能
- BlockCache:读缓存,客户端从磁盘读取完数据之后会将数据缓存到内存中,如果之后访问的话可以直接从内存中读取,不需要从磁盘中读取,如果有大量热点读的业务请求的话,可以极大提高性能
BlockCache缓存对象由一系列Block块组成,每个Block块默认为64K,每个块由物理上相邻的多个KV数据组成,主要有LRUBlockCache和BucketCache - Region:数据表的一个分片,数据表大小超过一定的阈值后会水平切分,分成两个Region,通常一个表的Region分布在集群的多个RegionServer上,一个RegionServer有多个Region,一般来自不同的表
一个Region由一个或多个Store组成,Store的个数取决于列簇的数量,每个列簇的数据会集中存放
一个Store由一个MemStore和一个或多个HFile组成,MemStore是写缓存,写入数据时会先写入MemStore,写满之后会异步将数据flush成一个HFile文件,当HFile数量超过阈值之后,会进行Compact操作,将小文件合并成大文件
6.HDFS
HDFS存储实际数据,HBase内部通过DFSClient组件来对HDFS的数据进行读写访问
7.HBase特性
1.优点
- 容量大,单表支持千亿行、百万列的数据规模,容量可达TB、PB
- 可扩展性,存储节点,读写服务节点扩展
- 稀疏性,允许大量列值为空,不占用空间
- 高性能,写性能高,随机单点读和小范围扫描读也能得到保证
- 多版本支持,对一个KV有多个版本保留
- 支持过期,超过TTL的数据会被自动清理
- 原生支持Hadoop
2.缺点
- 不支持复杂的聚合运算,需要使用Phoenix或Spark等
- 自身不支持二级索引
- 不支持全局跨行事务,只支持单行事务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号