
大数据初入门
---恢复内容开始---
一、HADOOP
1.什么是hadoop
HADOOP是apache旗下的一套开源软件平台,HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
HADOOP的核心组件有
①、HDFS(分布式文件系统)
②、YARN(运算资源调度系统)
③、MAPREDUCE(分布式运算编程框架)
广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2.Hadoop集群搭建
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每日十分钟,同步一次时间。 配置时间同步: 1)时间服务器配置 (1)检查ntp是否安装 [root@hadoop102 桌面]# rpm -qa|grep ntp ntp-4.2.6p5-10.el6.centos.x86_64 fontpackages-filesystem-1.41-1.1.el6.noarch ntpdate-4.2.6p5-10.el6.centos.x86_64 (2)修改ntp配置文件 vi /etc/ntp.conf 修改内容如下 a)修改1 #restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap b)修改2 server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst
为 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst c)添加3 server 127.127.1.0 fudge 127.127.1.0 stratum 10 3)修改/etc/sysconfig/ntpd 文件 vim /etc/sysconfig/ntpd 增加内容如下 SYNC_HWCLOCK=yes 4)重新启动ntpd [root@hadoop102 桌面]# service ntpd status ntpd 已停 [root@hadoop102 桌面]# service ntpd start 正在启动 ntpd: [确定] 5)执行: chkconfig ntpd on 2)其他机器配置(必须root用户) (1)在其他机器配置10分钟与时间服务器同步一次 [root@hadoop103 hadoop-2.7.2]# crontab -e 编写脚本 */10 * * * * /usr/sbin/ntpdate hadoop102 (2)修改任意机器时间 date -s "2015-9-11" (3)十分钟后查看机器是否与时间服务器同步 date
2.1、准备4个linux虚拟机(1-4)并创建用户并安装jdk环境(我采用复制虚拟机文件夹 参考:https://blog.csdn.net/zhang123456456/article/details/55815940)
2.2、在官网下载Hadoop(本文采用:hadoop-2.6.4.tar.gz)
2.3、上传Hadoop到集群1中
2.4、创建apps文件夹(mkdir apps)并将hadoop解压到apps下面(tar -zxvf hadoop-2.6.4.tar.gz -C apps/)
2.5、(cd apps/hadoop-2.6.4/etc/hadoop/)进入目录
2.6、修改(vim hadoop-env.sh )将JAVA_HOME改成固定的(echo $JAVA_HOME命令可以获得javahome路径)

2.7、修改core-site(vim core-site.xml),在configuration中添加
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址,hdfs://后为主机名或者ip地址和端口号 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://jokerq1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,value为hadoopp下新建的用于存储的文件夹 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hdpdata</value>
</property>
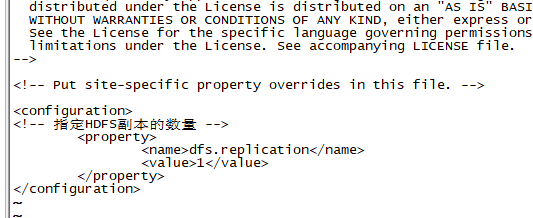
2.8、修改hdfs-site(vim hdfs-site.xml ),在configuration中添加
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
修改slaves(vim slaves)
2.9、修改mapred-site名称(mv mapred-site.xml.template mapred-site.xml)
2.10、修改mapred-site(vim mapred-site.xml),在configuration中添加
<!-- 指定mr运行在yarn上,使在集群上运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2.11、修改yarn-site,(vim yarn-site.xml ),在configuration中添加
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>jokerq01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
2.12、将apps文件夹拷贝到其他服务器上(cd ~ --> scp -r apps jokerq2:/home/hadoop/ --> scp -r apps jokerq3:/home/hadoop/ --> scp -r apps jokerq4:/home/hadoop/)(说明:本文4个虚拟机创建的用户名均为hadoop,主机名为jokerq1-4,(每个都已修改主机和ip的映射(vim /etc/hosts)))

2.13、将hadoop添加到环境变量(目的可以再任意路径下执行hadoop指令)(vim /etc/profile)(对应修改)(修改完成source /etc/profile)
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export HADOOP_HOME=/root/app/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.14、格式化namenode(是对namenode进行初始化)(集群1服务器)(hadoop namenode -format)

3、启动
3.1、在集群1中启动那么NameNode(hadoop-daemon.sh start namenode)

3.1.1、可以通过访问web页面查看使用情况(192.168.25.151:50070/)
3.2、其他服务器启动DataNode即可(hadoop-daemon.sh start datanode)
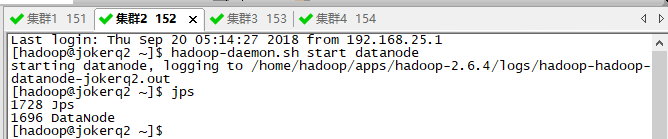
3.3使用jps命令验证是否启动成功(jps)
五、启动
1.进入sbin目录(cd ~/app/hadoop-2.4.1/sbin/)
2.启动HDFS(start-dfs.sh)( 可以修改 vim ~/app/hadoop-2.4.1/etc/hadoop/slaves 将localhost改为主机名)
3.启动YARN(start-yarn.sh)
4.使用jps命令验证是否启动成功(jps)
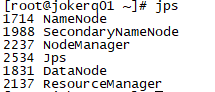
5.可以访问http://192.168.25.151:50070 (HDFS管理界面)(可以修改host文件将ip改为对应的linux机器名)
4、配置免密登录
ssh免密登录(1到1-4)
配置datanode启动节点 cd apps/hadoop-2.6.4/etc/hadoop/ --》 vim slaves 将hadoop改为其他节点
1、ssh-keygen(直接3个回车就行)
2、ssh-copy-id jokerq1
3、ssh-copy-id jokerq2
4、ssh-copy-id jokerq3
5、ssh-copy-id jokerq4
6、检查是否生效(是否需要输入密码) ssh joker4
7、测试 cd apps/hadoop-2.6.4/sbin/ --> start-dfs.sh 查看是否启动datanode --》stop-dfs.sh查看是否关闭
如果遇到如下错误
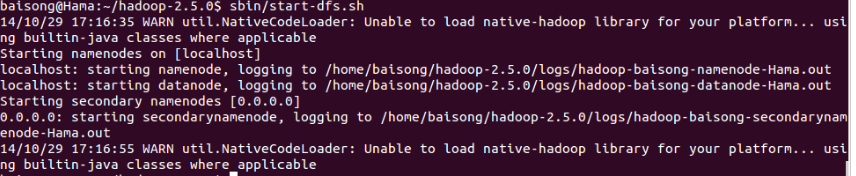
分析原因知,没有设置 HADOOP_COMMON_LIB_NATIVE_DIR和HADOOP_OPTS环境变量 在环境变量中添加(参考https://blog.csdn.net/xin_jmail/article/details/40556267)
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
六、配置ssh免登陆
正常多个机器:
(1-3步骤假设为机器1,机器1中想通过 ssh jokerq01 命令直接连接到jokerq01机器而不需要登录密码的)
1.进入到目录(cd ~/.ssh)
2.执行(ssh-keygen -t rsa)命令 (四个回车,执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥))
3.将公钥拷贝到要免登陆的机器上(需要先修改host文件对应的ip与机器名)(例:scp id_rsa.pub jokerq01:/root)
4.(4-6步骤换到要免登录的机器(jokerq01))(cd ~/.ssh)
5.新建authorized_keys文件(touch authorized_keys)并修改权限(chmod 600 authorized_keys)

6.将拷贝的公钥追加到后面(cat ../id_rsa.pub >> ./authorized_keys)
7.在机器1中通过 (ssh jokerq01) 命令直接登录
伪分布式:
1.(cd ~/.ssh)(ssh-keygen -t rsa)
2.直接追加(cat id_rsa.pub >> authorized_keys)
3.自己连接自己不需要密码(ssh jokerq01)

七、HDFS的JAVA客户端编写()
linux:
1.将linux改为图形界面(内存调大)用来运行eclipse(startx)(失败参考https://blog.csdn.net/baidu_19473529/article/details/54235030)
2.安装eclipse
2.1上传压缩包(eclipse-jee-photon-R-linux-gtk.tar.gz),并解压(可以命令,也可以右键Extract Here)
3.运行文件夹的eclipse(图标不适应可以修改图标),并新建java项目(java project)
4.导入jar包(在hadoop-2.4.1\share\hadoop\hdfs下的hadoop-hdfs-2.4.1.jar,还有hadoop-2.4.1\share\hadoop\hdfs\lib下的所有jar包,hadoop-2.4.1\share\hadoop\common下的hadoop-common-2.4.1.jar,hadoop-2.4.1\share\hadoop\common\lib下的所有jar包)
5.编写测试代码
windows(解压到本地,修改hosts文件,添加HADOOP_HOME,path等环境变量,并用(无jar版windows平台hadoop-2.6.1)将bin 和lib替换):
1.建项目,导jar包,写代码
2.直接JUnit Test报错,运行需要用户名修改为拥有linux文件可操作权限的用户(右键,run as,run configurations,Arguments,添加-DHADOOP_USER_NAME=root)
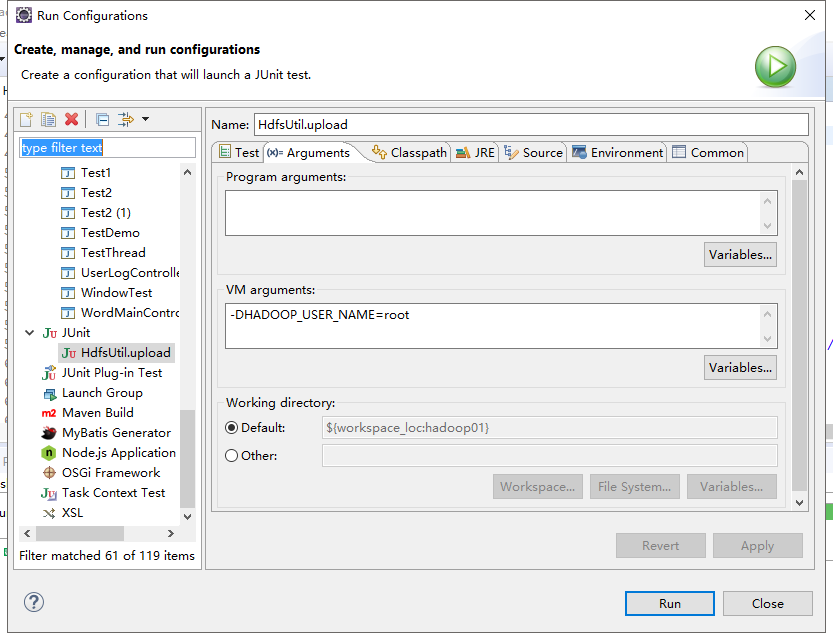
也可以FileSystem.get()方法指定用户

FileSystem fs = null;
@Before
public void init() throws Exception{
//读取classpath下的xxx-site.xml 配置文件,并解析其内容,封装到conf对象中
Configuration conf = new Configuration();
//也可以在代码中对conf中的配置信息进行手动设置,会覆盖掉配置文件中的读取的值
conf.set("fs.defaultFS", "hdfs://jokerq1:9000/");
//根据配置信息,去获取一个具体文件系统的客户端操作实例对象
fs = FileSystem.get(new URI("hdfs://jokerq1:9000/"),conf,"hadoop");
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号