Oracle Goldengate是如何保证数据有序和确保数据不丢失的?
工作中一直在用Oracle 的中间件Oracle GondenGate 是如何保证消息的有序和不丢失呢?
Oracle GoldenGate逻辑架构
首先,先看一下Oracle GoldenGate 的逻辑架构:
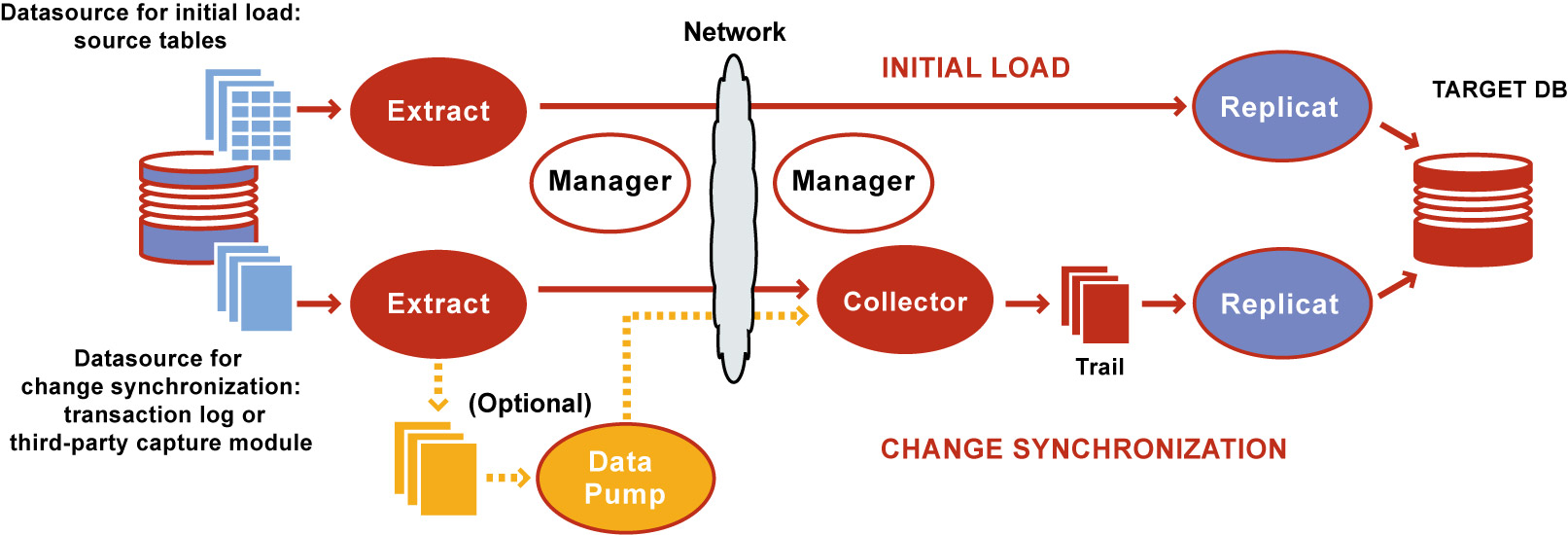
图中涉及到两个阶段:
- 初始化阶段: extract 进程直接抽取源表信息经网络传输到target 端的 replicat进程,replicat 进程获取到初始化加载数据将其同步到目标数据源。
- 增量数据抓取阶段:extract 进程从源表redo log 或其他增量日志中解析并获取增量,然后落地成数据文件;然后pump进程将数据经网络推送到目标端的collector进程。collector是由manager进程维护的,有新的pump数据过来,它会启动一个新的collector,这个collector绑定到特定的端口上,通过TCP/IP连接,负责接收特定pump进程推送过来的数据并落地到指定的目录下生成trail文件。replicat 进程实时读取 trail 文件并将数据推送给kafka。
官方关于 trail文件的说明如下:
To support the continuous extraction and replication of database changes, Oracle GoldenGate stores records of the captured changes temporarily on disk in a series of files called a trail. A trail can exist on the source system, an intermediary system, the target system, or any combination of those systems, depending on how you configure Oracle GoldenGate. On the local system it is known as an extract trail (or local trail). On a remote system it is known as a remote trail.
By using a trail for storage, Oracle GoldenGate supports data accuracy and fault tolerance (see Section 1.2.6, "Overview of Checkpoints"). The use of a trail also allows extraction and replication activities to occur independently of each other. With these processes separated, you have more choices for how data is processed and delivered. For example, instead of extracting and replicating changes continuously, you could extract changes continuously but store them in the trail for replication to the target later, whenever the target application needs them.
即trail 中保存的是数据库中的变化数据。Oracle GoldenGate用trail 做存储,确保数据的准确性和容错性。它也允许extract进程和replicat进程可以独立存在,类似于消息中间件的作用。
checkpoint保证数据不丢失和有序性
下面看一下官方给出的checkpoint 的案例(本来想用项目的真实checkpoint信息,为避免不必要的麻烦,作罢):
注意这个是Oracle RAC模式下checkpoint信息。
查看extract进程checkpoint信息命令:INFO EXTRACT JC108XT,SHOWCH
extract 进程checkpoint信息如下:
EXTRACT JC108XT Last Started 2011-01-01 14:15 Status ABENDED
Checkpoint Lag 00:00:00 (updated 00:00:01 ago)
Log Read Checkpoint File /orarac/oradata/racq/redo01.log
2011-01-01 14:16:45 Thread 1, Seqno 47, RBA 68748800
Log Read Checkpoint File /orarac/oradata/racq/redo04.log
2011-01-01 14:16:19 Thread 2, Seqno 24, RBA 65657408
Current Checkpoint Detail:
Read Checkpoint #1
Oracle RAC Redo Log
Startup Checkpoint (starting position in data source):
Thread #: 1
Sequence #: 47
RBA: 68548112
Timestamp: 2011-01-01 13:37:51.000000
SCN: 0.8439720
Redo File: /orarac/oradata/racq/redo01.log
Recovery Checkpoint (position of oldest unprocessed transaction in data source):
Thread #: 1
Sequence #: 47
RBA: 68748304
Timestamp: 2011-01-01 14:16:45.000000
SCN: 0.8440969
Redo File: /orarac/oradata/racq/redo01.log
Current Checkpoint (position of last record read in the data source):
Thread #: 1
Sequence #: 47
RBA: 68748800
Timestamp: 2011-01-01 14:16:45.000000
SCN: 0.8440969
Redo File: /orarac/oradata/racq/redo01.log
Read Checkpoint #2
Oracle RAC Redo Log
Startup Checkpoint(starting position in data source):
Sequence #: 24
RBA: 60607504
Timestamp: 2011-01-01 13:37:50.000000
SCN: 0.8439719
Redo File: /orarac/oradata/racq/redo04.log
Recovery Checkpoint (position of oldest unprocessed transaction in data source):
Thread #: 2
Sequence #: 24
RBA: 65657408
Timestamp: 2011-01-01 14:16:19.000000
SCN: 0.8440613
Redo File: /orarac/oradata/racq/redo04.log
Current Checkpoint (position of last record read in the data source):
Thread #: 2
Sequence #: 24
RBA: 65657408
Timestamp: 2011-01-01 14:16:19.000000
SCN: 0.8440613
Redo File: /orarac/oradata/racq/redo04.log
Write Checkpoint #1
GGS Log Trail
Current Checkpoint (current write position):
Sequence #: 2
RBA: 2142224
Timestamp: 2011-01-01 14:16:50.567638
Extract Trail: ./dirdat/eh
Header:
Version = 2
Record Source = A
Type = 6
# Input Checkpoints = 2
# Output Checkpoints = 1
File Information:
Block Size = 2048
Max Blocks = 100
Record Length = 2048
Current Offset = 0
Configuration:
Data Source = 3
Transaction Integrity = 1
Task Type = 0
Status:
Start Time = 2011-01-01 14:15:14
Last Update Time = 2011-01-01 14:16:50
Stop Status = A
Last Result = 400
关于Extract的read几种checkpoint解释
1. extract将read checkpoints放置在数据源中。如果数据源是Oracle,则检查点是放在Oracle的日志中。
2. Startup checkpoint:启动检查点是进程启动时在数据源中创建的第一个检查点。
-
Thread #: 创建检查点的线程数,只有Oracle的RAC模式才会有 -
Sequence #: 创建检查点的事务日志的序列号 -
RBA: RBA是relative byte address的简写,表示创建检查点的记录的相对字节地址 -
Timestamp: 表示创建检查点的记录的时间戳 -
SCN: SCN是system change number的简写,表示系统更改检查点所在记录的编号 -
Redo File: 包含创建检查点的记录的事务日志的路径名
3. Recovery checkpoint:恢复检查点表示extract未处理的最早的事务日志的位置信息。
4. Current checkpoint:表示extract在数据源中读的最近的(注意:此时还没有写成功)记录的位置信息。它应该和 Log Read Checkpoint 信息一致。
关于extract的写的checkpoint解释
extract进程将 current checkpoint 放在trail 文件中。current checkpoint 是指extract 正在写的trail的位置。
-
Sequence #: 写入检查点的trail文件的序列号 -
RBA:trail文件中创建检查点的记录的相对字节地址 -
Timestamp: 创建检查点的记录的时间戳 -
Extract trail: trail文件的相对路径名称 -
Trail Type: 其中在类似于NFS服务上的被认为是local
查看 replicat 进程 checkpoint 信息命令:INFO REPLICAT JC108RP, SHOWCH
replicat 进程checkpoint 信息如下:
REPLICAT JC108RP Last Started 2011-01-12 13:10 Status RUNNING
Checkpoint Lag 00:00:00 (updated 111:46:54 ago)
Log Read Checkpoint File ./dirdat/eh000000
First Record RBA 3702915
Current Checkpoint Detail:
Read Checkpoint #1
GGS Log Trail
Startup Checkpoint(starting position in data source):
Sequence #: 0
RBA: 3702915
Timestamp: Not Available
Extract Trail: ./dirdat/eh
Current Checkpoint (position of last record read in the data source):
Sequence #: 0
RBA: 3702915
Timestamp: Not Available
Extract Trail: ./dirdat/eh
Header:
Version = 2
Record Source = A
Type = 1
# Input Checkpoints = 1
# Output Checkpoints = 0
File Information:
Block Size = 2048
Max Blocks = 100
Record Length = 2048
Current Offset = 0
Configuration:
Data Source = 0
Transaction Integrity = -1
Task Type = 0
Status:
Start Time = 2011-01-12 13:10:13
Last Update Time = 2011-01-12 21:23:31
Stop Status = A
Last Result = 400
1. Startup Checkpoint
当进程启动时在trail文件中创建的第一个checkpoint
-
Sequence #:写入检查点的trail文件的序列号 -
RBA:trail文件中创建检查点的记录的相对字节地址 -
Timestamp:表示创建检查点的记录的时间戳 -
Extract Trail:trail 文件的相对地址
2. Current Checkpoint:current checkpoint 是指replicat 进程读取trail文件的最近的记录的位置。
抽取的最终的日志格式使得实现幂等性操作成为可能
Oracle GoldenGate的日志格式是snapshot格式的,试想一下,假设我一条记录的某个字段 做累加操作,Oracle GoldenGate给我们的数据是增量数据,在at-least-once语义之上,进行多次传输,那么数据最终会出问题。而snapshot数据,只需要根据主键不断覆盖即可。这种数据是支持幂等性操作的。
总结
- 其一,日志格式是snapshot的,使得实现幂等性操作成为可能。
- 其二Oracle GoldenGate的checkpoint机制和消费者保存消费的offset的机制是一样的。都支持at-least-once的语义。因为很有可能出现已经写数据成功,但更新checkpoint数据失败,即kafka中的数据可能会出现重复的现象。所以在处理Oracle GoldenGate的消息时,要确保最终落地的操作是幂等性操作,这样数据至少不会丢。一般幂等性都需要唯一id作为标识,一般选用数据的主键做唯一id。如果没有主键可以使用其他方案,切记生成的id要唯一且可重复生成,即同一条记录根据id生成规则,永远是相同的id且在一定时间范围内不冲突。
- 其一数据在Oracle GoldenGate传输过程中,同一个extract进程落到一个文件中,经网络传输会被响应的collector接收并把数据放到对应的rmtrail中,其中 local trail 和 remote trail 是一一对应的。相当于数据从一个分区传输到另外一个固定对应的分区,只要数据有序传输(它通过读写checkpoint来保证),那么最终remote trail和local trail的顺序肯定是一致的(可能会有重复)。
- 其二,replicat落到kafka的数据是单分区的,保证了放到kafka的数据的有序性。
参考:
Oracle GoldenGate文档库:https://docs.oracle.com/goldengate/1212/gg-winux/GWUAD/wu_about_gg.htm#GWUAD117
Oracle官方对 Checkpoint 的术语的解释:https://docs.oracle.com/goldengate/1212/gg-winux/GWUAD/wu_ogg_checkpts.htm#GWUAD965

 浙公网安备 33010602011771号
浙公网安备 33010602011771号