
第一次个人编程作业
| 软件工程 | 网工1934班级链接 |
|---|---|
| 作业要求 | 作业要求链接 |
| 作业目标 | 1. 尝试个人开发一个论文查重项目 2. 学会使用 PSP 表格预计和记录各模块开发时间 3. 学会使用单元测试对项目进行测试 4. 学习使用性能分析工具来找出代码中的性能瓶颈并进行改进 5. 学会使用 GitHub 来管理源代码和测试用例 |
一、PSP 表格
| PSP 2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 240 | 360 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 30 | 45 |
| · Design Review | · 设计复审 | 10 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| · Design | · 具体设计 | 300 | 190 |
| · Coding | · 具体编码 | 150 | 160 |
| · Code Review | · 代码复审 | 45 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | ||
| · Test Report | · 测试报告 | 30 | 25 |
| · Size Measurement | · 计算工作量 | 10 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 10 |
| · 合计 | 1240 | 1690 |
二、模块接口的设计与实现
模块设计
- 主类
- Main 类:main(),传入文件绝对路径,计算两文本内容重复率,并写入答案文件。
- 工具类
- WordFreq 类:记录分词后每个词的词频。
- Article 类:对文件内容的封装,包含了文件名、原始字符串、分词结果以及词频集合。
- TxtIOUtils 类:readTxt(),读取txt文件内容;writeTxt(),向txt文件写入内容。
- TextTools 类:getSegmentList(),分词操作;getWordFrequency(),统计词频;getArticle(),封装成 Article.
- TextException 类:自定义异常处理类,用于抛出文件文本内容为空的异常。
- CompareTask 类:对两 Article 对象生成词频向量,TF-IDF 加权,计算 Jaccard 系数,即两文本内容重复率。
- CompareReport 类:生成两文本重复率的报告。
- 依赖库
- hanlp:用于分词。
- guava:用于统计词频时用到的 MultiSet 支持。
- junit:用于单元测试。
项目结构

关键函数
getSegmentList()
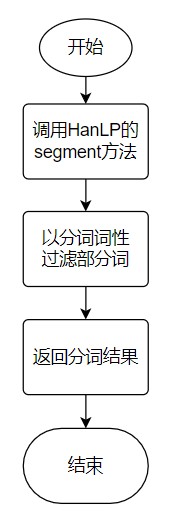
getWordFrequency()

关键算法
前几天上数据挖掘课的时候,讲到相似性度量的时候,书中就提到“广义 Jaccard 系数”,于是萌生了用作论文查重算法的念头。
广义 Jaccard 系数
广义 Jaccard 系数,元素的取值可以是实数。又称为 Tanimoto 系数,用EJ来表示,计算方式如下:
EJ(A,B) = (A * B) / (|A|^2 + |B|^2 - A * B)
其中 A、B 分别表示为两个向量,集合中每个元素表示为向量中的一个维度,在每个维度上,取值通常是 [0, 1] 之间的。
TF-IDF
对于两篇文档,分词之后,形成两个“词语--词频向量”,词语可以做为 EJ 的维度,如何将词频转换为实数值。借鉴 tf/idf 的思路。对于每个词语,有两个频度:1.在当前文档中的频度;2. 在所有文档中的频度。其中 1 相当于 tf ,与权重正相关;2 相当于 df,与权重反相关。对于 1,权重就可以取词频本身 tf(w) = D(w),D(w)表示在当前文档中 w 出现的次数。对于2,计算权重为 idf (w) = log(TotalWC/C(w)). C(w)是词语 w 在所有文档中出现的次数,TotalWC 是所有文档中所有词的总词频。
三、模块接口部分的性能改进
最初采用 tika 来获取 txt 文件内容,发现大材小用了,并且要增加 apache 的许多外部依赖包,导致程序打包体积过大,性能也有所降低。后来就简单地使用 IO 来读写字符串。
Jprofiler 的性能分析图:

从上图来看,程序消耗最大的属于 HanLP 中的函数,及主要消耗来自分词操作。
四、模块部分单元测试展示
测试用例在 3119005373 文件夹下。前面的模块测试用例使用作业要求里的例子,重复率容易看得出,最后的报告多个测试使用老师提供的样例。
public class ProcessTest {
private static String root = "3119005373/";
@Test
/*
测试分词
*/
public void segmentTest() {
String str = "今天是星期天,天气晴,今天晚上我要去看电影。";
List<Term> segmentList = TextTools.getSegmentList(str);
System.out.println(segmentList);
}
@Test
/*
测试统计词频
*/
public void wordFreqTest() {
String str = "今天是星期天,天气晴,今天晚上我要去看电影。";
List<Term> segmentList = TextTools.getSegmentList(str);
List<WordFreq> wordFreqList = TextTools.getWordFrequency(segmentList);
System.out.println(wordFreqList);
}
@Test
/*
测试getArticle
*/
public void getArticleTest() throws IOException, TextException {
Article article = TextTools.getArticle(root + "test_orig.txt");
System.out.println(article.getName());
System.out.println(article.getText());
System.out.println(article.getSegmentList());
System.out.println(article.getWordFreqList());
}
@Test
/*
测试CompareTask和CompareReport
*/
public void compareTest() throws IOException, TextException {
// TODO 涉及读写可用多线程FutureTask优化。
Article a1 = TextTools.getArticle(root + "test_orig.txt");
Article a2 = TextTools.getArticle(root + "test_plag.txt");
CompareTask task = new CompareTask(a1, a2);
task.execute();
CompareReport report = task.getCompareReport();
System.out.println(report);
}
@Test
/*
报告多个测试
*/
public void compareMultiTest() throws IOException, TextException {
List<CompareTask> tasks = new ArrayList<>();
Article a1 = TextTools.getArticle(root + "orig.txt");
Article b1 = TextTools.getArticle(root + "orig_0.8_add.txt");
tasks.add(new CompareTask(a1, b1));
System.out.println("load 1");
Article a2 = TextTools.getArticle(root + "orig.txt");
Article b2 = TextTools.getArticle(root + "orig_0.8_del.txt");
tasks.add(new CompareTask(a2, b2));
System.out.println("load 2");
Article a3 = TextTools.getArticle(root + "orig.txt");
Article b3 = TextTools.getArticle(root + "orig_0.8_dis_1.txt");
tasks.add(new CompareTask(a3, b3));
System.out.println("load 3");
Article a4 = TextTools.getArticle(root + "orig.txt");
Article b4 = TextTools.getArticle(root + "orig_0.8_dis_10.txt");
tasks.add(new CompareTask(a4, b4));
System.out.println("load 4");
Article a5 = TextTools.getArticle(root + "orig.txt");
Article b5 = TextTools.getArticle(root + "orig_0.8_dis_15.txt");
tasks.add(new CompareTask(a5, b5));
System.out.println("load 5");
for (CompareTask task : tasks) {
task.execute();
System.out.println(task.getCompareReport().toString());
System.out.println();
}
}
}
测试覆盖率截图:
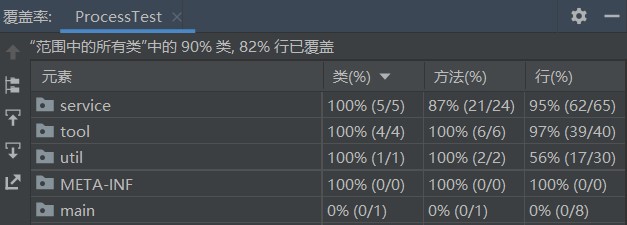
主方法因为会退出程序终止测试,所以没加入单元测试中。
五、模块部分异常处理说明
文件不存在的异常
用 file.exists() 判断文件是否存在,放在 TxtIOUtils 类的 readTxt() 方法下:
if(!file.exists())
throw new FileNotFoundException(file.getName()+"文件不存在!");
异常测试:
@Test
/*
测试文本文件不存在的异常
*/
public void fileNotExistTest() throws TextException {
try {
Article article = TextTools.getArticle(root + "test.txt");
}catch (IOException e) {
e.printStackTrace();
}
}
测试场景:3119005373 文件夹中不存在 test.txt 文件。
测试截图:

文本为空的异常
用 str.isEmpty() 判断文本内容是否为空,放在 TextTools 类下的 getArticle() 方法下:
if(text.isEmpty())
throw new TextException(file.getName()+"文本为空!");
异常测试:
@Test
/*
测试文本内容为空的异常
*/
public void emptyTextTest() throws IOException {
try {
Article article = TextTools.getArticle(root + "test_empty.txt");
}catch (TextException e) {
e.printStackTrace();
}
}
测试场景:test_empty.txt 为空。
测试截图:

答案文件已存在且不可写的异常
用 file.canWrite() 判断文件是否可写,放在 TxtIOUtils 类的 writeTxt() 方法下:
if(!file.canWrite())
throw new FileNotFoundException(file.getName()+"文件已存在且不可写!");
异常测试:
@Test
/*
测试答案文件已存在且不可写的异常
*/
public void fileReadOnlyTest() {
try {
String str = "写不进去啊";
TxtIOUtils.writeTxt(str, root+"test_readonly.txt");
}catch (IOException e) {
e.printStackTrace();
}
}
测试场景:test_readonly.txt 设置只读。
测试截图:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号