自己动手写虚拟机
这学期上了《编译原理》这门课。什么感觉呢,既机械又灵活。
前端技术理论性很强,算法固定,甚至可以使用lex,yacc这类的工具自动生成。但如果是你自己来设计一个语言,你会设计什么样的语法和语义呢,如Lisp那样简洁而强大,还是如C++那样复杂而强大呢?反正我是无从下手。
后端技术比前端复杂,不过也有很多工具可以利用,比如GCC的后端和伊利诺伊斯大学开发的LLVM,好像Google的go语言的后端用的就是LLVM。
相对于计算机其他领域,如操作系统,编译理论技术已经发展的很完善了。对于一个身经百战的高手来说,实现一个编译器的难度不大,像Ken Thompson、Dennis Ritchie等大神,他们写个好的操作系统要几年,而写个好的编译器只要几个星期就可以了,关键在于为什么要设计这样一个语言。当初Dennis发明C语言就是为了更好的写Unix程序或者Unix本身,其实这体现的是过程式开发的思想;Alan Kay等人发明Smalltalk就是为了是程序员更容易、更规范地运用面向对象的思想;Dennis大神在Plan9操作系统上用的Alef语言,就是为了支持并发式编程。所以程序设计语言的灵魂是它体现出来的方法论。
OK,其实我很讨厌说这些虚的东西,它让我感觉自己像个卖狗皮膏药的。但我又忍不住,仿佛这样说了,我离Ken Thompson、Martin Fowler等大师又进了一步,其实我什么也不懂。
写个虚拟机干嘛JJWW说这么多程序设计语言的事啊?好吧,其实我实现这个虚拟机就是为了实现一个编译器,并且都是《编译原理与设计》一书上介绍的。所以你最好是把我写的这篇文章当成是学习那本书的辅助资料。不过如果你对那本书不感兴趣,仅仅也想实现个简单虚拟机,那么这篇文章也会有一定用处,实际上那本书对虚拟机的实现几乎没有阐述。将要实现的虚拟机叫 Tiny Machine,简称 TM,不要联想到中文的缩写哦!
TM汇编格式
我所实现的TM对汇编文件的格式要求很严格,它不能有注释,每行有且只有一条汇编指令。汇编指令的格式为:
opcode r s t
即操作码加上三个操作数(不管操作码真正使用几个操作数),也就是编译原理代码生成中常用的三地址码格式。
TM编程结构
TM机器由三个部分组成:
1. 寄存器,总共8个,最后一个是程序计数器。这8个都是通用寄存器,连程序计数器都是。
2. 指令内存区。最小单元是一条指令的大小,指令在TM中用 instruc_t结构表示,所以指令内存区是instruc_t类型的数组。
3. 数据内存区。最小单元是sizeof(int),所以数据内存区int类型的数组。
你是不是觉得TM机跟你想象的不一样呢?首先指令内存和数据内存是分开的,不像X86是一起的,学过计算机组成原理的朋友应该知道这是所谓的哈佛结构。还有就是不管指令内存还是数据内存,他们的最小单元都不是字节类型,甚至这两种内存的最小单元根本就不一样。这两点和我们平常在X86平台下积累的内存模型完全不一样,其实这样做是为了简化TM虚拟机的实现。以前我也想过实现一个虚拟机,我当时的方法就是完全按照X86的模型,但是太复杂以至于我放弃了。这也是为什么我现在会写这篇文章,因为我发现《编译原理与实践》的作者实现的很巧妙。
TM的结构如下, 其中ifile是要加载的汇编文件:

TM指令系统
先看下X86的汇编指令,比如ADD,它既可以是寄存器的值和寄存器的值相加,也可以是寄存器的值和内存的值相加,也就是一条指令的寻址模式是变化的,所以X86的指令格式中要保留一些位用来标识寻址模式。而TM中的情况则简单得多,还是看ADD,如果汇编文件中有这样一条指令 ADD 0 1 2,它一定是表示将1号寄存器和2号寄存器的值相加,结果存入0号寄存器。所以TM中的指令有个最重要的特点:一个操作码只有一种解释方式。ADD只能解释为将s号寄存器和t号寄存器相加,将结果存入r号寄存器;其他的操作码也一样只有一种解释方式,只不过可能t不是表示寄存器而是普通的数。
TM中所有的操作码如下,操作码的意义都是唯一的,并且给出了详细的注释:
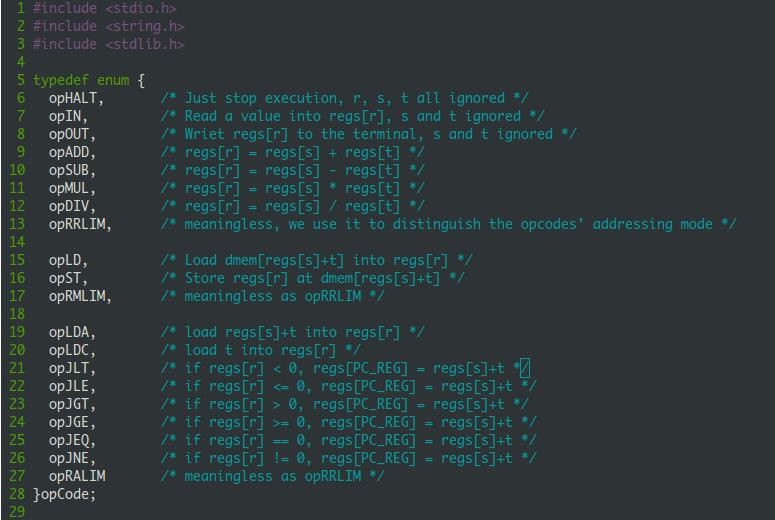
因为一种操作码就对应了一种指令,所以下文我不会区分操作码和指令,读者根据上下文应该很容易。指令是存储在指令内存区的,上文已经说过指令内存区的最小单元是instruc_t,下面就来定义它:

TM总体执行过程
关于数据结构的东西已经讲的差不多了(除了两三个关于调试的数据结构,读者最好通过我提供的源码自己去看),接下来我实现TM中的总体过程,也就是main函数。TM先找到要汇编输入文件,然后调用vm_setup()做一些初始化工作,在调用vm_load()将汇编代码加载到指令内存中,最后调用vm_startup()执行指令内存中的程序。main函数的源代码很简单,如下:

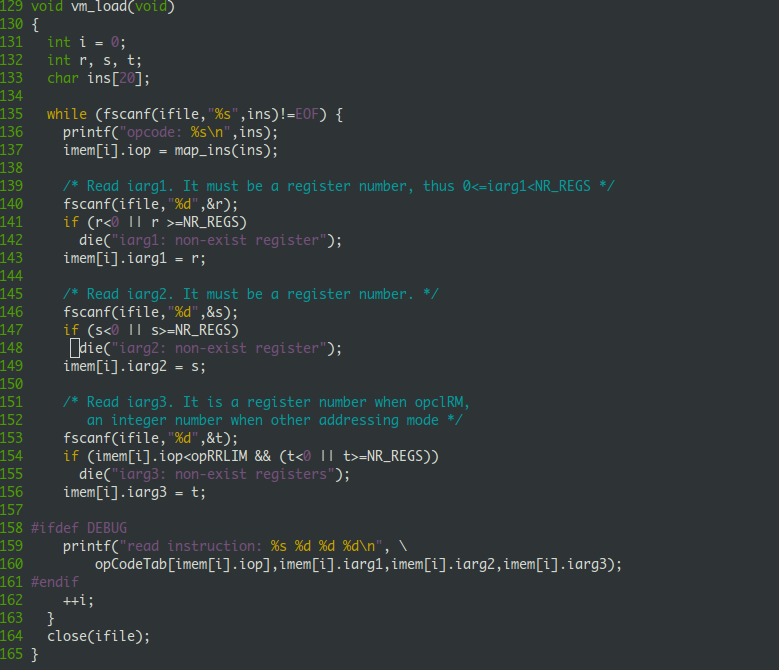
vm_load函数实现
vm_setup函数过于简单,在这里就不说了,读者自己看源码,它就是将regs、imem、dmem清零。这里我重点讲一下vm_load函数的实现。vm_load就是把汇编文件中一行一行的"opcode r s t" 转换成instruc_t类型的变量,存在imem中。源码如下: (哎,其实vm_load我讲的更少)
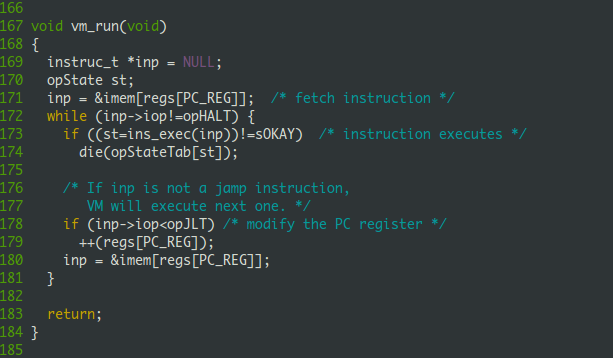
vm_run函数实现
vm_run是TM最有大局观的函数,它主要是模拟CPU的工作过程,也就是三个步骤的循环:
1. 根据当前PC值获取指令
2. 执行该指令,如果发生致命错误则退出。TM中每个指令的执行函数都会返回一个状态以表明他们是正常执行,还是遇到了致命错误。
3. 修改PC的值
vm_run源码如下:
ins_exec函数会接受所有的指令,然后根据操作码选择合适的函数来进行真正的运算,好像有点儿设计模式的味道。ins_exec函数源码如下:
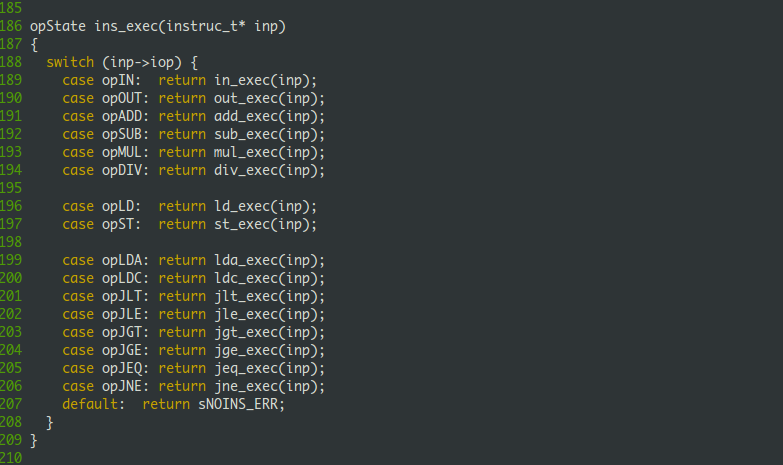
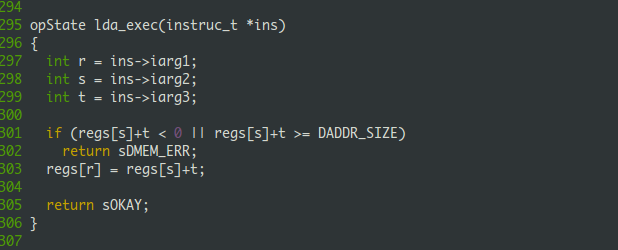
ins_exec代码结构非常清晰,不用我说你也知道是什么意思。比如当前指令的操作码是ADD,那么它就会调用add_exec函数。想要扩展TM机器的指令也非常容易,执行定义一个xxx_exec函数,然后在ins_exec中添加一个case opXXX分支即可。每一个操作码都对应一个函数,下面就选LDA指令看看,它的意义是把 regs[s]+t 加载到regs[r]中,源码如下:
总结:
我们应该先熟悉TM机器再来实现它,读者可以看看《编译原理与实践》,事实上我实现的TM比书上的还要简单,特别是如何加载汇编文件,书中相当于写了个词法分析器,而我仅仅是用了一些fscanf语句,这也导致了我的汇编文件格式有更高的要求,比如不能有注释、每行有且只有一条指令、指令格式一定为 opcpde r s t,即使是HALT指令也要写成 HALT x x x,虽然三个操作数都没有用。
读者最好看看我的源代码(已经给出了详尽的注释),因为还有一些数据结构没有列出。
如果有任何问题,可以此博客上给我留言,也可以发邮件至 JohnWaken@163.com
Tiny Machine源代码
posted on 2009-12-05 20:45 John Waken 阅读(19787) 评论(23) 编辑 收藏 举报

