Lecture#02 Advanced SQL
上节课提到关系代数,其目标是 从更高层面告诉数据库我们想要的结果,而不告诉它如何做。
🌰 对数据进行进行排序,若我们必须告诉数据库系统具体该如何做,则需提供给它具体的某种排序算法;若我们使用高级语言/声明式语言,则只需告知数据库完成对数据的排序,而并不介意它实际怎样完成。
👆是声明式语言(SQL)的优点之一,无需告知数据库如何做,它会找出最佳优化方案。
查询优化将SQL查询转换为某种最有效的查询方案,查询优化器可以尝试不同策略来对查询进行优化。
如何进行查询优化之后讨论。
今日课纲
聚合函数 + Group By
字符串、日期、时间类型的处理
输出控制、输出重定向
嵌套查询
window 函数
公共表表达式 Common Table Expressions(CTE)
1 关系语言
Edgar Codd 在20世纪70年代早期发表了有关关系模型的重要论文。他最初只定义了——DBMS 如何在关系模型上执行查询的数学符号(关系代数的七种基本运算符:选择、投影、自然连接、笛卡尔积、交、并、差)。
用户只需要使用声明性语言(如SQL)指定他们想要的结果。DBMS负责确定产生该答案的最有效的计划。
关系代数基于集合(无序,无重复)。SQL基于包(无序,允许重复)。
SQL不会排序也不会去重,除非你明确提出要求。
2 SQL 的历史
SQL:结构化查询语言。IBM最初将其命名为“SEQUEL”。由不同种类的命令组成:
数据操作语言(DML):数据操作,选择 select、插入 insert、更新 update、删除 delete。数据定义语言(DDL):数据定义,如新建表,增加索引等。数据控制语言(DCL):安全性授权、访问控制。- 其他:如何定义视图,如何定义完整性约束、参照约束,事务。
SQL并不是一门死语言。它每隔几年就会更新一些新功能。sql - 92是DBMS声明他们支持SQL的最低标准。每个供应商都在一定程度上遵循该标准,但有许多专有扩展。
SQL-92标准(也就是我们如今所熟知的基本SQL,例如select,insert,update,delete,创建表,事务等)
不同数据库间SQL特性及功能比较:https://troels.arvin.dk/db/rdbms/
通常我们看标准SQL在某种数据库系统中如何编写(MYSQL),尽管有标准实现,但实际上并没有人去按照标准去做(目前没有任何数据库系统通过了SQL 2016标准的认证,它们只支持了一些很零碎的功能)
3 聚合函数
示例数据库:
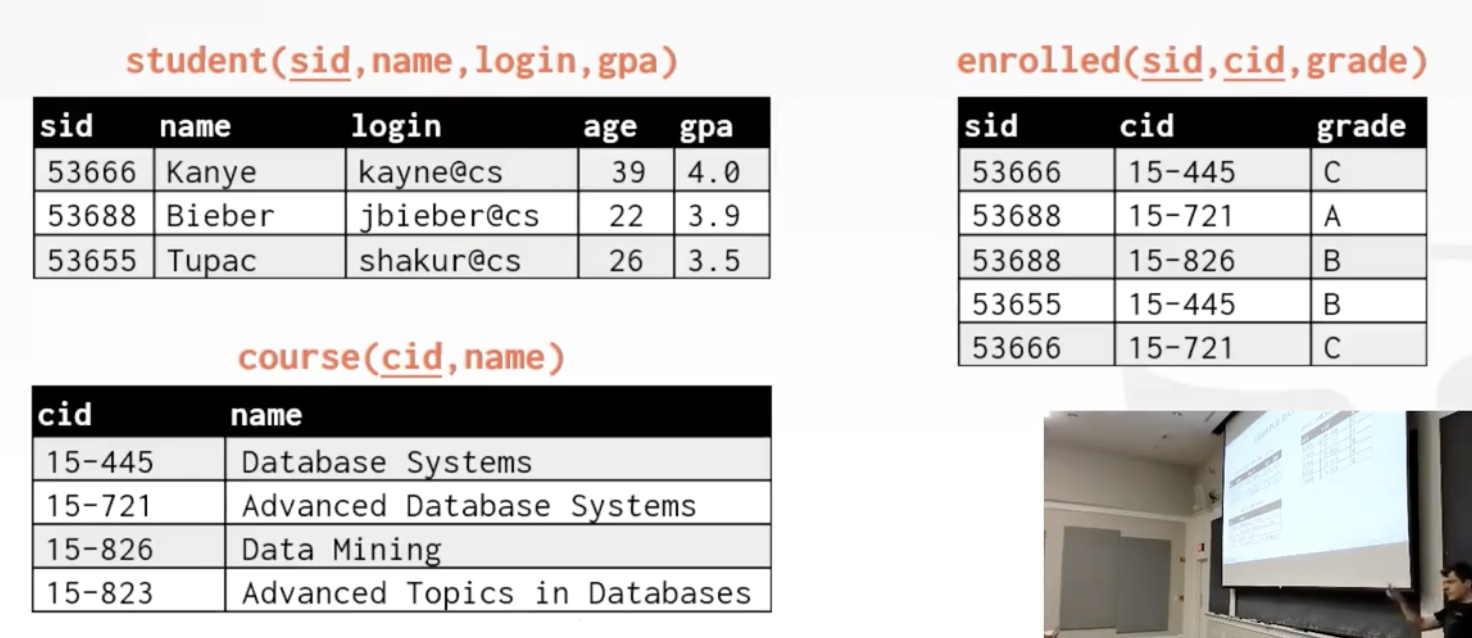
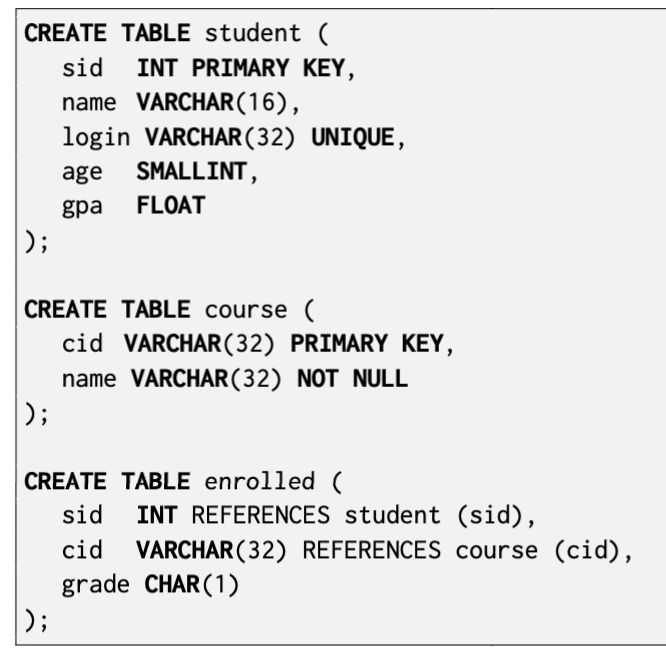
聚合函数将一组元组作为输入,然后生成单个标量值作为输出。只能在SELECT输出列表中使用。
SQL-92标准中定义了AVG()、MIN()、MAX()、SUM() 以及 COUNT() 函数。
- AVG(col) —— 返回col列的平均值
- MIN(col) —— 返回col列的最小值
- MAX(col) —— 返回col列的最大值
- SUM(col) —— 返回col列所有值的和
- COUNT(col) —— 返回 col 列值的数目
计算student表中login字段中以"@cs"结尾的学生数目:

此处COUNT()例子中,我们只想数出过滤完后的元组数目,故login字段实际无任何意义,因此可使用"*"重写login。
"*"是SQL中的特殊关键字,它代表了该tuple中的所有属性。更进一步,我们可将“*"用1替换,即每数一个tuple,tuple数量就加1。
单个查询中可放入多个聚合函数。
计算student表中login字段中以"@cs"结尾的学生数目及他们的平均分:

加入 DISTINCT 关键字,可去除重复值。
计算student表中login字段中以"@cs"结尾的不重复的学生数目(账号个数):(前提是不存在两个学生的登录账号相同)

group by 子句中给出的一个/多个属性构造分组,属性上取值都相同的元组被分为一组。having 子句可设置分组的限定条件。
- select 子句和 having子句中,只能有被聚集的属性和出现在 group by 子句中的属性。
- 不使用 group by 则将整个结果视作一个分组。
输出每门课的cid及学生的平均gpa:
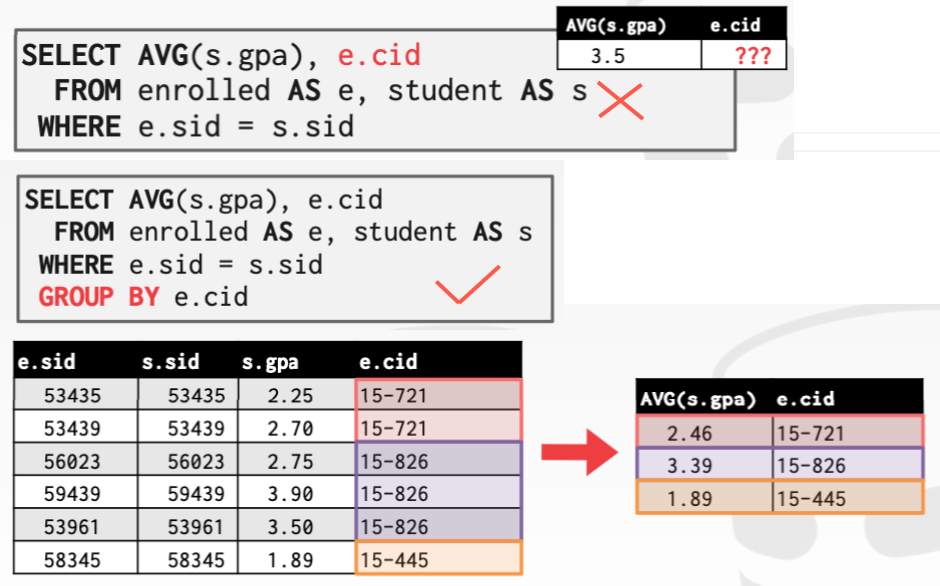
不写 group by 时,整个结果为一个分组,有多个cid,故第一种写法是错误的。
MySQL在传统模式下(
SET SESSION sql_model = 'traditional')会随意输出一个e.cid,但是若你设置更严格的模式(ansi),则会提示错误。
你可以使用提示的查询计划,来帮助你改进或减少某些运行查询的工作量:
我想统计小于某个值的一些集合的数量(通过GROUP BY来做),随着我的聚合函数计算的进行,可能我意识到我需要的 tuple 数量不超过10个,我要通过我的HAVING子句来进行滤掉,那么我不会让第11个Tuple存在于这个组中,因为它做无用功。
4 字符串操作
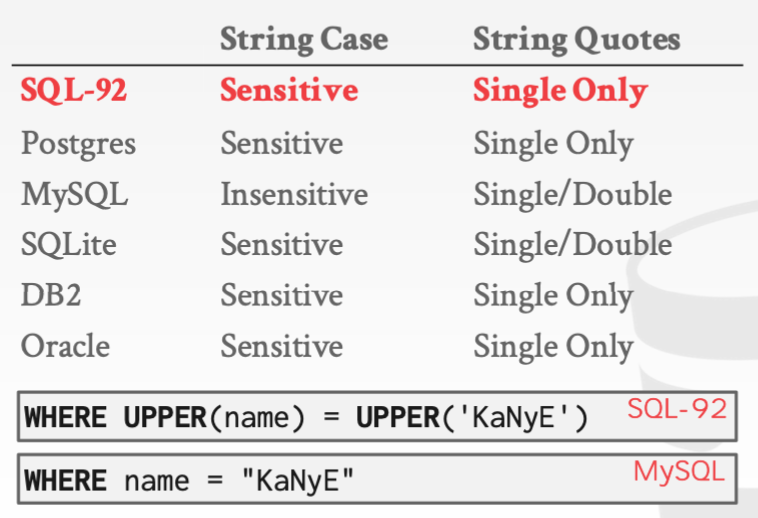
不同数据库对于字符大小写敏感、字符串引号的规定:
(SQL标准规范中字符大小写敏感,且必须用单引号声明。大部分数据库系统遵循这一点)
SQL 中由很多操作字符串的函数:
upper(s)将字符串 s 转换为大写;lower(s)将字符串 s 转换为小写trim(s)去除字符串 s 后面的空格substring(s,first,last)选取s的子串
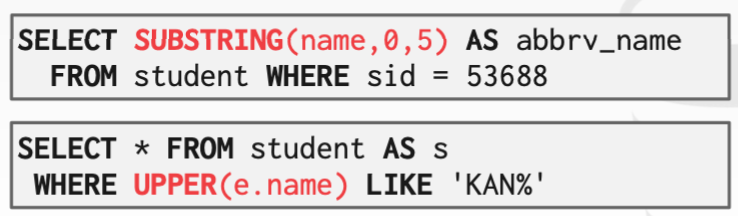
使用 like 操作符实现字符串的模式匹配,使用 escape 关键词定义转义字符;使用 not like 比较运算符搜寻不匹配项。
- 百分号(%):匹配任意子串
- 下划线(_):匹配任意一个字符
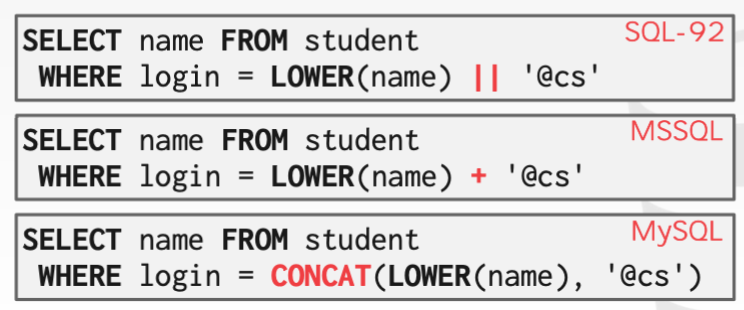
标准SQL使用 || 拼接字符串。
- 大多数DBMS也遵循这一点。Postgres和Oracle是所有DBMS中遵循SQL标准最好的,SQL server、DB2其次,SQLite还行,MySQL最差。
- 在SQL Server 下要用
+;在MySQL下不能用 + 、不能用 || ,只能通过concat()函数。MySQL中若在两个字符串间不放任何东西,它们也会连接在一起(这点其他数据库系统都不行)。‘An’ ‘Dy’ ‘Pavlo’
5 日期/时间操作
日期(类型)记录时间戳,而不用时间格式。
| 返回当前时间戳 | Postgres | MySQL | SQLite |
|---|---|---|---|
NOW()函数 |
√ | √ | × |
CURRENT_TIMESTAMP() 函数 |
× | √ | × |
CURRENT_TIMESTAMP 关键字 |
√ | √ | √ |
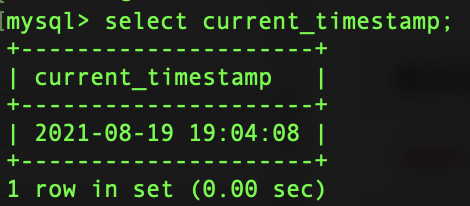
SELECT CURRENT_TIMESTAMP;
-
DATE()函数:将字符串转换为日期类型。 -
EXTRACT()函数:提取日期/时间数据的单独部分,比如年YEAR、月MONTH、日DAY、小时HOUR、分钟MINUTE、秒SECOND等 -
UNIX_TIMESTAMP()函数:将日期转换为 UNIX 中的时间戳(即从1970.01.01开始计算的秒) -
ROUND(字段,位数)函数:将数值字段四舍五入为指定的小数位数。 -
DATEDIFF()函数:MySQL 中 用于计算两个日期之间的间隔天数。 -
julianday()函数:SQLite中 将日期转换为公历时间(即从公元前4713.01.01到现在的天数)。 -
CAST(表达式 AS 数据类型)函数:将某种数据类型的表达式显式转换为另一种数据类型。参数是个表达式,它包括用AS关键字分隔的源值和目标数据类型。
🌰获取今天是这个月的第几天:
SELECT EXTRACT(DAY FROM DATE('2021-08-19')) AS days; -- 输出19,适用Postgres、MySQL,SQLite不行
🌰获取今天是这一年的第几天(使用日期的减法):
-- 只适用 Postgres
SELECT DATE('2021-08-19')-DATE('2021-01-01') AS days; -- 输出230
-- 适用 MySQL
SELECT ROUND((UNIX_TIMESTAMP(DATE('2021-08-19'))-UNIX_TIMESTAMP(DATE('2021-01-01')))/(60*60*24),0) AS days; -- 先转化为秒,再转换为天数
SELECT DATEDIFF(DATE('2021-08-19'),DATE('2021-01-01')) AS days;
-- 适用 SQLite
SELECT CAST((julianday(CURRENT_TIMESTAMP)-julianday('2021-01-01')) AS INT) AS days;
SQLite是最为流行,部署最为广泛的数据库系统。
6 输出重定向 Output Redirection
与将查询结果返回给客户端(Eg:终端)不同,可让DBMS将结果存储到另一个表中。则可在后续查询中访问该数据。
-
新表:将查询的输出存储到一个新的(永久的)表中。SQL标准中,
INTO关键字在执行过程中会创建一张表。
-
现有表:将查询的输出存储到数据库中已经存在的表中。输出数据列的属性、类型必须与现有表的属性、类型相匹配,列名称不必匹配。

如果SELECT语句中有44列,你只填其中的3列,那我们就会将你的数据丢掉,我无法将其写入,因为它们俩的属性并不匹配。
👆只是SQL语法标准,但实际不同系统实现这点的方式不同。无法写入的情况下,有些系统会直接报错;有些系统会继续往下运行,忽略写入失败的那个;有些可能直接崩溃。
7 输出控制 Output Control
SQL基于包(无序,允许重复)。
ORDER BY <column*> [ASC|DESC] :按一列或多列值对输出元组进行排序。(默认升序 ASC)
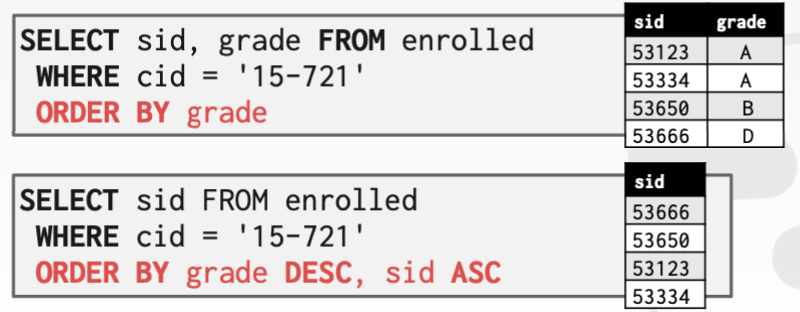
- ORDER BY 子句中可使用任意表达式。

LIMIT <count> [offset] :默认情况下,DBMS将返回查询产生的所有元组。可使用LIMIT子句来限制结果元组的数量。LIMIT 表示要取的tuple数目,offset 表示要跳过的tuple数目。
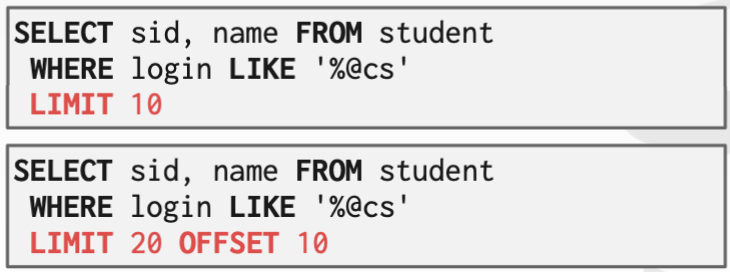
- 除非使用带有 LIMIT 的 ORDER BY 子句,否则每次调用结果中的元组都可能不同。就相当于又调用一次查询,第二次调用的结果可能不同。
8 嵌套查询
在其他查询中调用查询,以在单个查询中执行更复杂的逻辑。外部查询的作用域包含在内部查询中(即内部查询可引用外部查询的属性,但外部不能引用内部)
构建嵌套查询的办法:先从外部查询开始构建,考虑实际需要哪些属性,然后考虑如何过滤得到结果。

内部查询可出现在查询的任何地方:
-
SELECT 中:

-
FROM 中:

-
WHERE 中:

嵌套查询涉及操作符:
ALL:必须满足子查询中所有行的表达式。ANY:子查询中至少有一行必须满足表达式。IN:等价于= ANY()。EXISTS:至少返回一行。
例子
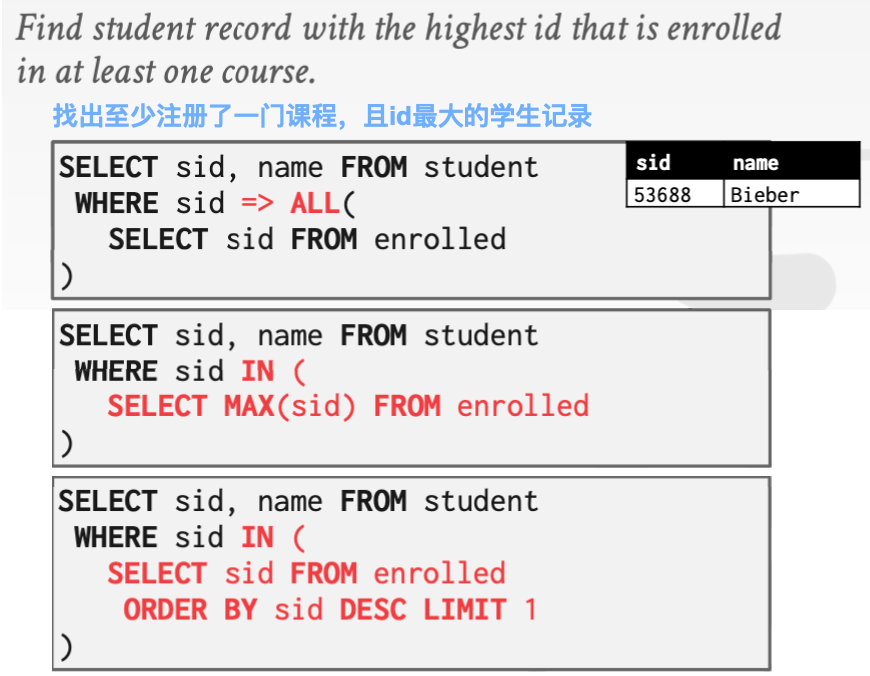

❗️ 能否将内部循环当做一种嵌套循环看待?
答:可以,但并非如此。for循环实际上有某种类似于顺序的概念,而所有的这些操作符(例如,IN,EXISTS,ANY)所试图表达的是在内部查询中的是否存在有满足条件的任何tuple,你并不会真的每个都要去遍历一遍。如果你将外部查询当做一个for循环考虑,因为你正在遍历每个tuple,但是服务器对内部查询的评估始终是在一个 bag 或者 set 的层面进行的。
9 window 函数
Window 函数:跨元组执行“移动”计算。类似于聚合函数,对一个tuple子集进行函数计算,将它们聚合为一个结果,可以增量方式或移动方式进行此操作。但它仍然返回原始元组,后跟用 window 函数计算出的值。 如果采用聚合函数,则只能看到被聚集的属性和出现在 group by 子句中的属性,无法看到原来完整的tuple。
先执行整个查询,再使用window函数对这些结果进行处理,然后将之放入查询结果中。格式如下:
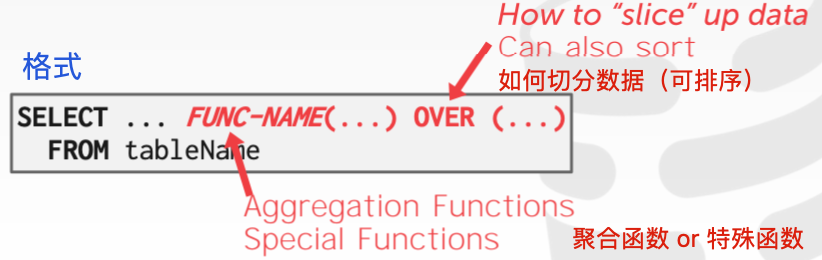
函数:可以是我们之前讨论的任何聚合函数,如MIN()、MAX()、AVG()、COUNT()和SUM();也可以是特殊的window函数:
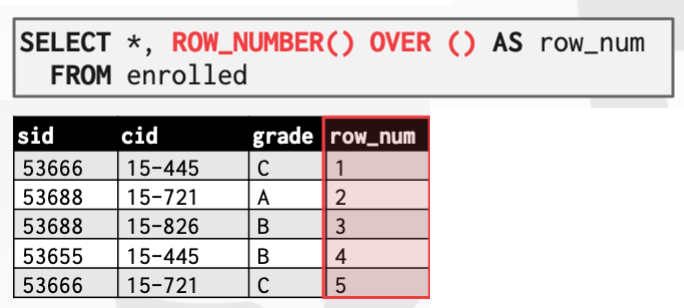
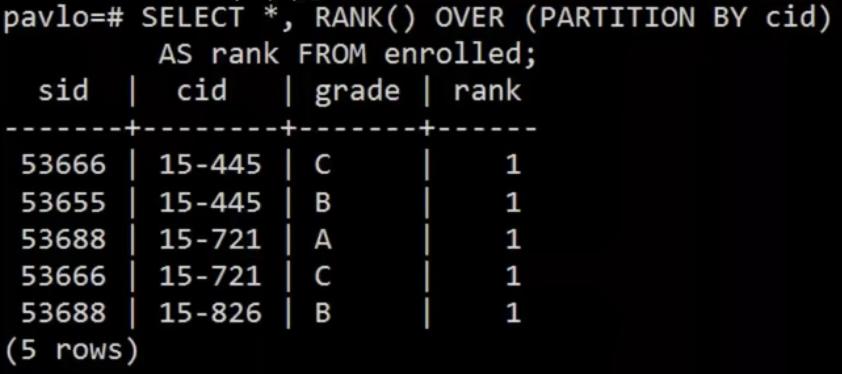
ROW_NUMBER():当前行的行号(输出顺序)RANK():当前行的顺序位置(排序后的排名)。要配合 OVER 中的 ORDER BY 使用。
❗️ ROW_NUMBER() 输出的行号代表的是出现在输出中的顺序,RANK() 则是分组排序后的组内顺序。即:DBMS在window函数排序后计算 RANK,排序前计算 ROW_NUMBER。
分组:OVER 子句指定在计算 window 函数时如何将元组分组。PARTION BY 指定分组。
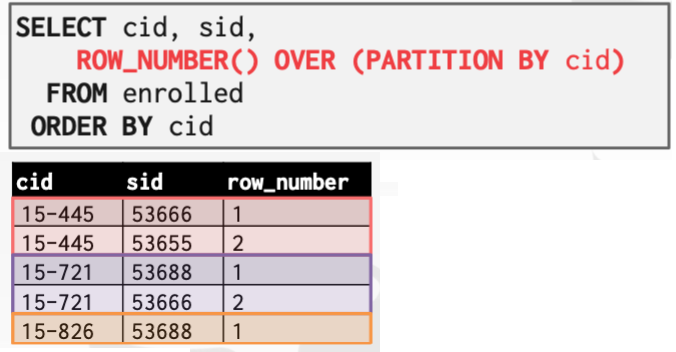
根据cid进行分组,并在输出中生成对应的行号。看起来就像聚合函数GROUP所做的那样,根据cid对它们进行分组,每一组内按顺序排列。
在 OVER 中包含 ORDER BY 可对每个组中的条目进行排序。(可确定结果的顺序)

此处两个例子结果一致,因为先执行查询排序后在结果之上执行window函数。
🌰 找出每门课最高分的学生信息:

内部查询:遍历enrolled表,基于课程ID对tuples进行分组(partition by语句),然后每组根据它们的成绩升序排列(order by语句)。此时我们就得到了分组后的结果,rank()函数会根据排序后每个tuple在输出列表中出现的先后顺序进行计算,然后将输出写入临时表ranking中。
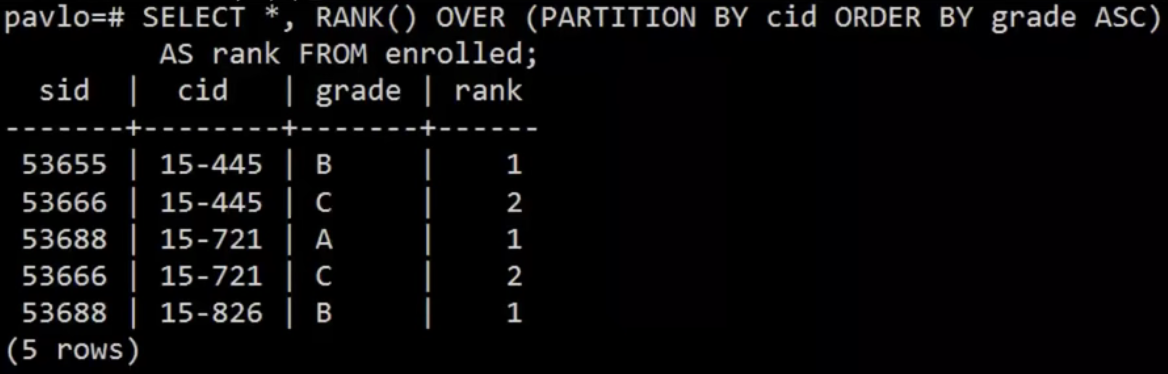
外层查询:基于tuple的rank字段来做额外的过滤。
❗️ RANK() 一定要配合 OVER中的 ORDER BY 使用,否则不能正常排序。
(这是数据库实际执行该查询的结果,而不是该查询自身的语义)
PostgresSQL、MySQL 8、较新版本SQLite支持 window 函数。
10 CTE
CTE是编写更复杂查询的窗口或嵌套查询的替代方案。可以将CTE视为仅用于一个查询的临时表。CTE 基本工作原理是引入WITH子句,WITH子句会在你执行正常的查询之前先一步执行。
WITH子句将内部查询的输出绑定到具有该名称的临时结果。
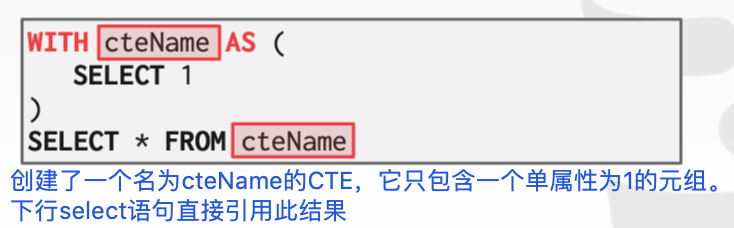
可以绑定输出列属性名:

一个查询可包含多个CTE声明:

例子

WITH 后添加 RECURSIVE 关键字可让CTE引用自身。
❗️ CTE和嵌套查询的区别:可在CTE中进行递归,但在嵌套查询中不能。


UNION 去重,UNION ALL 不去重。这里不用 ALL 也行。通过循环生成1到10的数字—— SELECT 1生成的tuple带单个属性值1,接着对另一个引用counter所做的查询进行UNION操作。无论我们使用的counter是什么,我们会对它进行+1,然后将它作为输出生成。我们会一直执行这条语句,直到WHERE子句中counter的值大于10,停止生成tuple。若没有WHERE限制,会无限循环!
设置语句超时时间:SET statement_timeout = '10s';

 浙公网安备 33010602011771号
浙公网安备 33010602011771号