ShardingJdbc
一、面试常见问题
1.什么是垂直/水平拆分模式
2.基于客户端与服务器端实现分表分库区别
3.单表达到多大量开始分表分库
4.数据库分表分库策略有那些
5.ShardingSphere实战分表分库
6.为什么不推荐使用mycat实现分表分库
7.分表分库后查询存在那些优缺点
8.分表分库后如何实现分页查询
9.分表分库后如何实现排序查询
a、什么是垂直/水平拆分
垂直拆分:将不同业务功能相关的表放到不同的数据库中 也就是类似于 微服务架构中 会员数据库/订单数据库/支付数据库,但拆分后存在分布式事务问题
水平拆分:将一张表数据存放到多个不同数据库中,或者是将一张表,在同一数据库中拆分为多个子表存放,但存在查询问题:如分页、排序
b、基于客户端与服务器端实现分表分库区别
i、基于客户端Shardingjdbc实现数据库代理
优点:效率比较高
缺点:不能够保证数据库的安全性、内存溢出,同时在归并数据结果时是没有实现解耦,可能会影响我们业务代码性能
原理:基于aop代理方式拦截并篡改sql
例子 user为逻辑表根据id作为分表策略,在同一数据库下,分片为user-01和user-02两个真实子表
情况一、客户端根据逻辑表名发送的sql:selec * from user where id = 1 携带id,则 Shardingjdbc依据分表策略原则将篡改后的sql
发给指定事实表,如 select * from user-01 where id =1
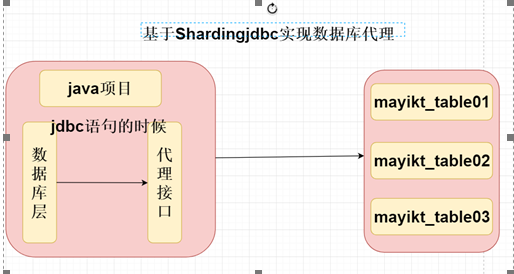
情况二、客户端根据逻辑表名发送的sql:selec * from user where age= 1 携带age不在分表策略内,则 Shardingjdbc同时向子表
user-01和user-02发送两条sql分别为 selec * from user-01 where age= 1、selec * from user-02 where age= 1
将两者查询结果返回给Shardingjdbc进行归并处理后返回客户端
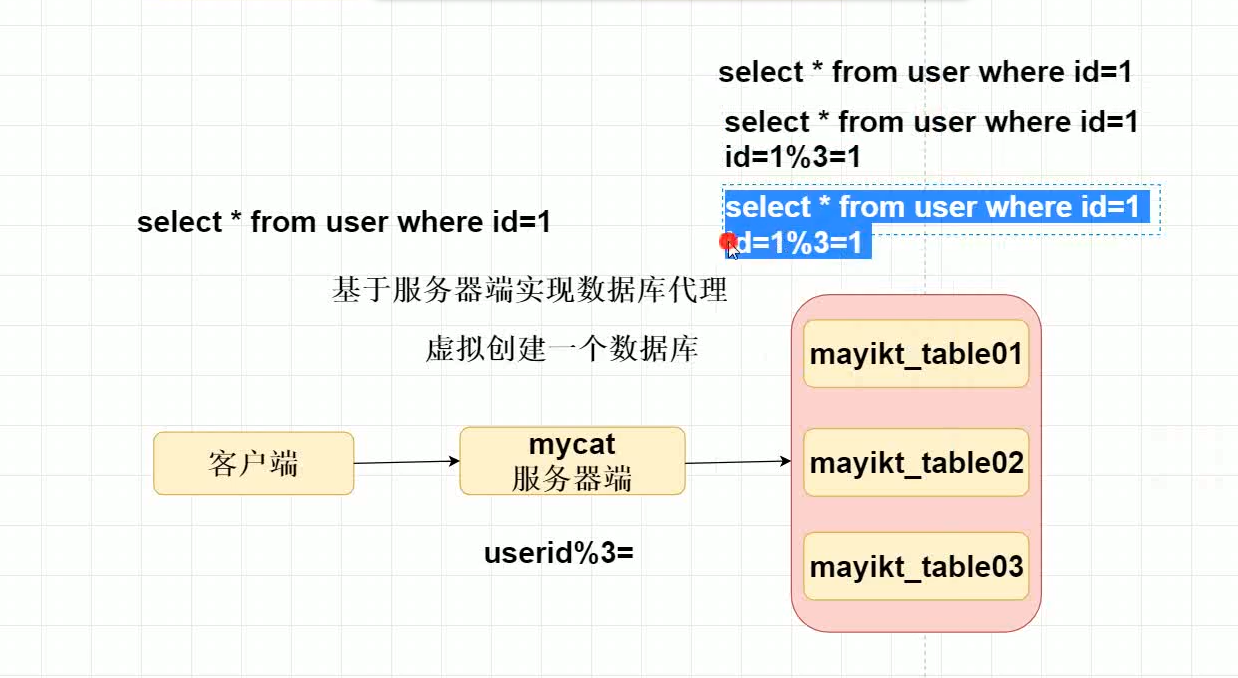
ii、基于服务器端mycat实现数据库代理
优点:能够保证数据库的安全性
缺点:效率比较低
c、单表达到多大量开始分表分库
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
摘自:阿里巴巴java开发手册
d、数据库分表分库策略有那些
取余/取模 均匀存放数据 缺点:不能够扩容
按照范围分片1-500万 501万-1000万
按照日期进行分片 日志、订单信息 同居
按照枚举值分片
二进制取模范围分片
一致性hash分片 类似于HashMap 缺点 数据存放不均匀
按照目标字段前缀指定的进行分区 mayikt wuhan
按照前缀ASCII码和值进行取模范围分片
主流分片算法:取余/取模 日期 一致性hash分片
例如:
根据userid,不能够扩容,只能分成两张表
Userid=1%2=1
Userid=2%2=0
Userid=3%2=1
Userid=4%2=0
Member_01
Member_02
二、只作水平分表的配置:application.properties
# shardingjdbc分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#指定course表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
spring.shardingsphere.sharding.tables.t_course.actual-data-nodes=m1.course_$->{1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE【雪花算法】
spring.shardingsphere.sharding.tables.t_course.key-generator.column=cid
spring.shardingsphere.sharding.tables.t_course.key-generator.type=SNOWFLAKE
# 指定分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.t_course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.t_course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
三、水平分库分表
# shardingjdbc分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m1,m2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://localhost:3306/edu_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=root
#配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://localhost:3306/edu_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=root
#指定数据库分布情况,数据库里面表分布情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.t_course.actual-data-nodes=m$->{1..2}.course_$->{1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.t_course.key-generator.column=cid
spring.shardingsphere.sharding.tables.t_course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.t_course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.t_course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
# 指定数据库分片策略 约定user_id是偶数添加m1,是奇数添加m2
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
spring.shardingsphere.sharding.tables.t_course.database-strategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.t_course.database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号