HTTP2初探
背景
本文是对Google博客上文章的翻译和笔记.以及一些待解决的问题记录. Google 博客上这篇文章的中文版有很多翻译错误.
概述
HTTP/2 仍是对之前 HTTP 标准的扩展,而非替代.HTTP 的应用语义不变,提供的功能不变,HTTP 方法、状态代码、URI 和标头字段等这些核心概念也不变.
HTTP/2 的主要目标是:
- 通过支持完整的请求与响应的多路复用来减少延迟;
- 通过有效压缩 HTTP 标头字段将协议开销降至最低;
- 增加对请求优先级和服务器推送的支持;
重要的两点
- HTTP/2 没有改动 HTTP 的应用语义。HTTP 方法、状态代码、URI 和标头字段等核心概念一如往常;
- HTTP/2 修改了数据格式化(分帧)以及在客户端与服务器间传输的方式;
这两点统帅全局,通过新的分帧层向我们的应用隐藏了所有复杂性。可以实现在同一连接上 进行多个并发交换.
Binary framing layer: 二进制分帧层
HTTP/2 所有性能增强的核心在于新的二进制分帧层,它定义了如何封装 HTTP 消息并在客户端与服务器之间传输。
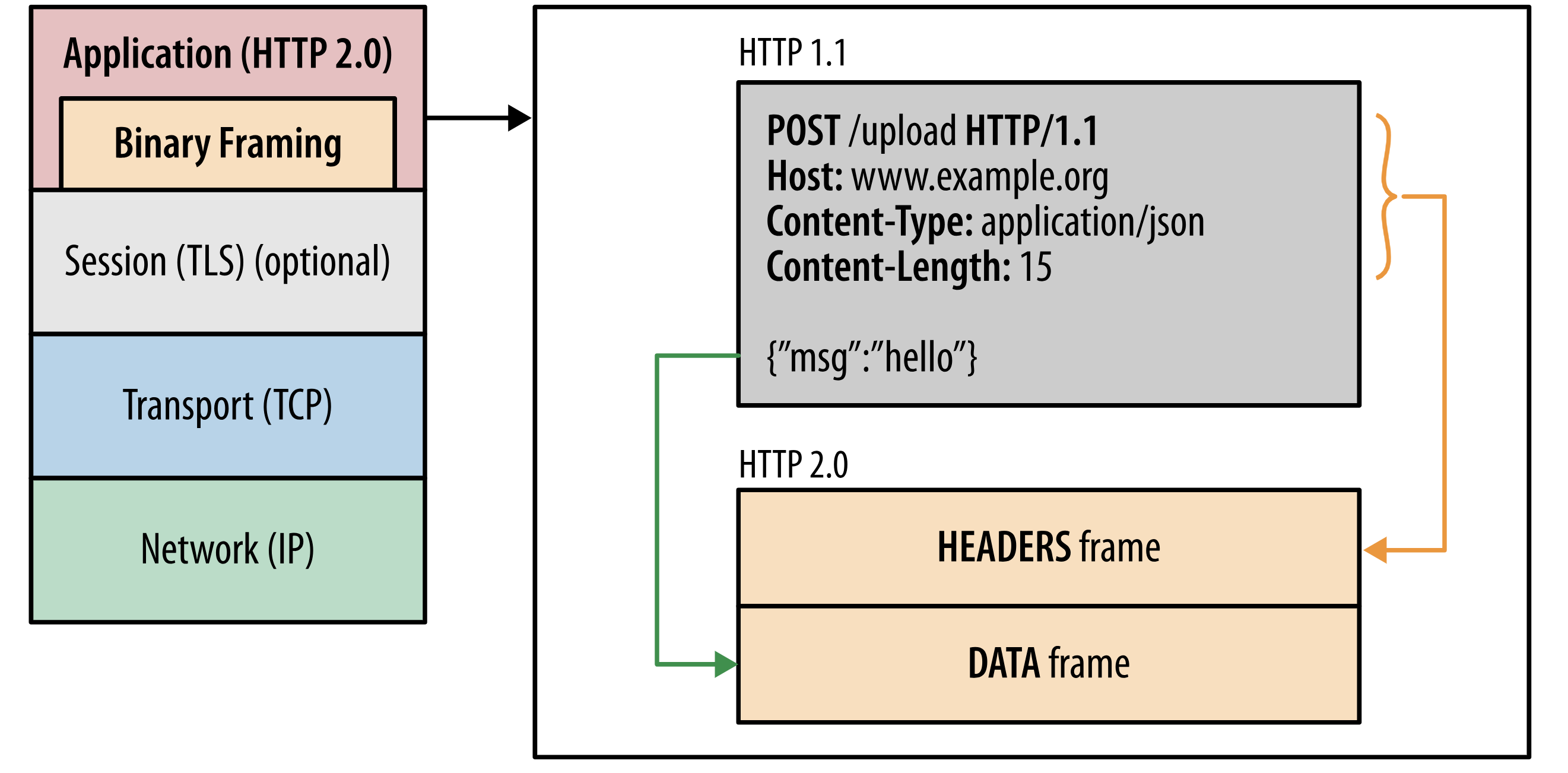
这里所谓的“层”,指的是位于套接字接口与应用可见的高级HTTP API之间一个经过优化的新编码机制:HTTP 的语义(包括各种动词、方法、标头)都不受影响,不同的是传输期间对它们的编码方式变了。
HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码。
数据流、消息和帧
- 数据流:已建立的连接内的双向字节流,可以承载一条或多条消息。
- 消息:与逻辑请求或响应消息对应的完整的一系列帧。
- 帧:HTTP/2 通信的最小单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。
简单概括一下:
- 所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- 每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。
- 每条消息都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧。
- 帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载等等.来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装.
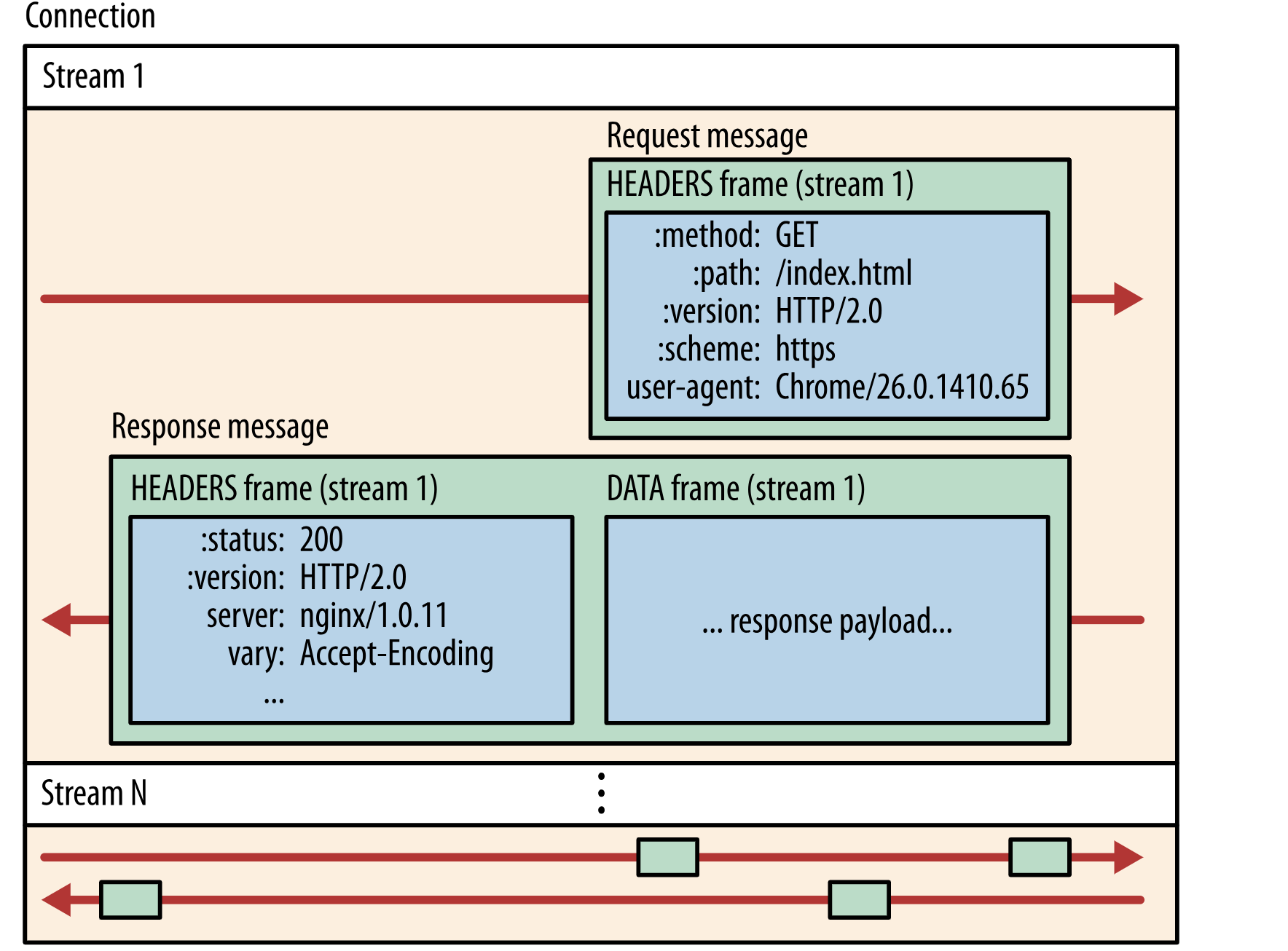
HTTP/2 将 HTTP 协议通信分解为二进制编码帧的交换,这些帧对应着特定数据流中的消息。所有这些都在一个 TCP 连接内复用。
Request and response multiplexing: 请求与响应复用
在 HTTP/1.x 中,如果客户端要想发起多个并行请求以提升性能,则必须使用多个 TCP 连接.
即: 多个并行请求 == 多个 TCP 连接;
H2 中客户端和服务端将HTTP消息分解为互不依赖的帧,在一条TCP连接上交替发送,在最后一端进行重新组装.这样可以实现请求和相应复用.
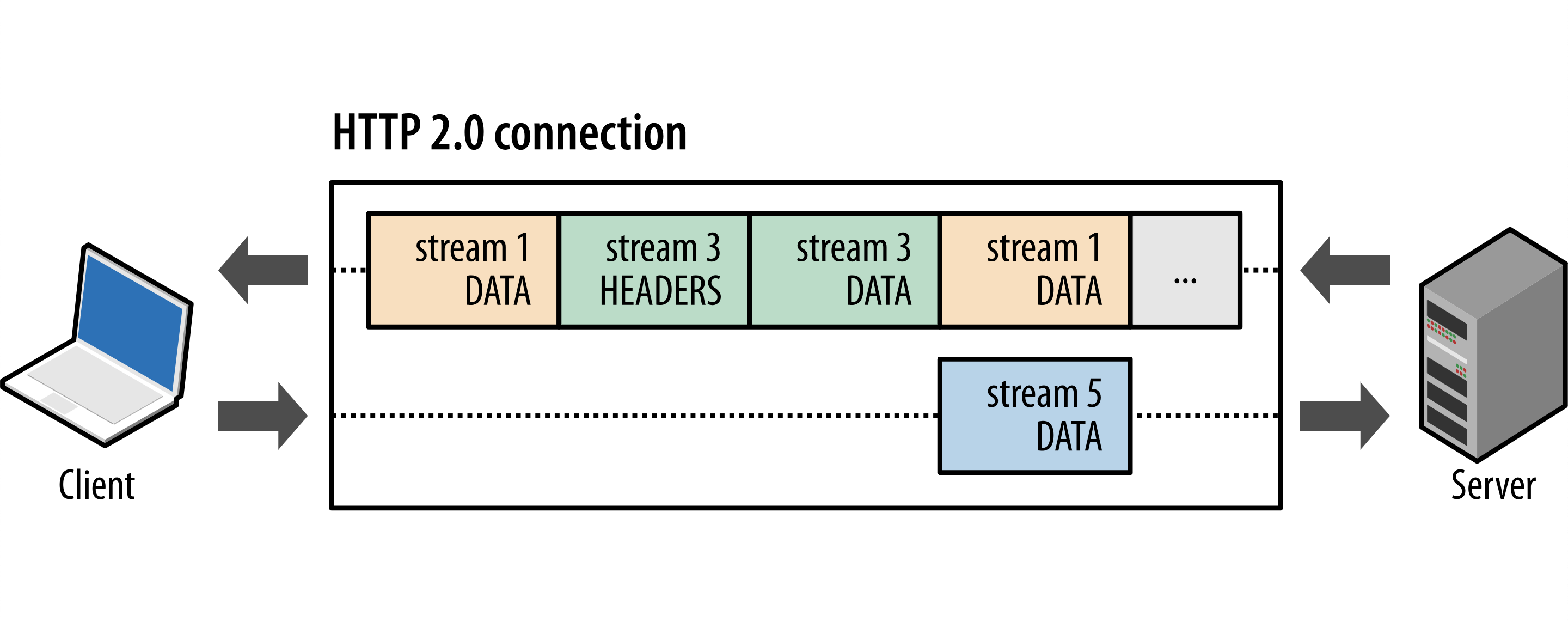
图中展示了三个数据流正在并行传输.
客户端正在向服务器传输一个 DATA 帧(数据流 5).
服务器正向客户端交错发送数据流 1 和数据流 3 的一系列帧。
优点:显著提高效率;
Stream prioritization:数据流优先级
将数据分解为帧之后,这些帧就可以实现多路复用,故而,这些帧的顺序就很重要.
所以H2允许每个数据流都有一个关联的优先级和依赖关系.
H2 允许:
- 每个数据流可以分配一个1到256之间的一个整数,作为权重;
- 每个数据流可以和其他的数据流存在明确的依赖关系;
权重和依赖关系的设定,可以让客户端构造和传达一个优先级树,以表示客户端想要如何接受响应;
相对的,服务端可以通过这个优先级树,来控制CPU,内存和其他资源的,以达到设置流优先级的目的;一旦 response 资源可用, 控制带宽的分配可以达到最佳的方式传递高优先级的数据传递到
客户端;
一个流的依赖关系通过引用另外一个流的唯一标识符作为parent,来达到依赖; 如果parent 被省略,则 parent就是root 流;
声明流的依赖关系,意味着, parent 流资源分配优先级需要在依赖方之前;
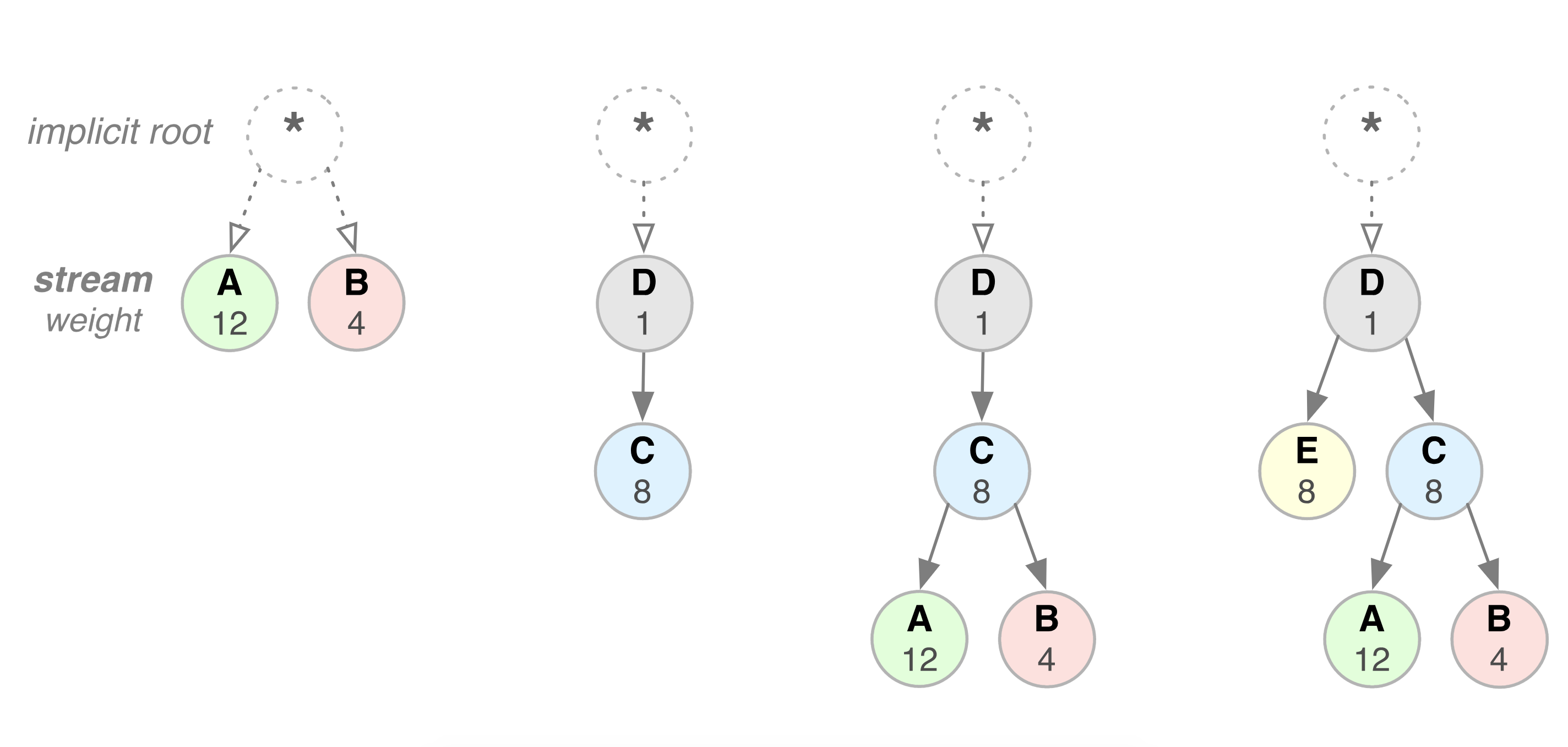
如图:
图中 D 需要在 C 之前得到处理.
对于共享一个parent的兄弟节点,则根据他的权重比例进行资源的分配; 图中的A和B,需要按照 12/16 和 4/16 的比例进行资源的分配;
图中需要解释的有
- D依赖于root stream;
- A 和 B 依赖于 C;
- E 和 C 依赖于 D;
所以:
D优先于E和 C得到全部的资源;
E和C 优先于AB得到全部的资源; E和C按照等比例拿到资源;
C优先于AB 拿到全部资源,此时与权重无关,由依赖关系决定.
除此之外,优先级和依赖关系还允许客户端在任意的时间点进行修改.这样就允许了浏览器更进一步的优化;换句话中,我们可以在和用户的交互的过程中,修改依赖关系和权重,来达到用户的交互和其他的一些信号.
PS: 对于权重和依赖关系,只是客户端请求的一个偏好,服务端并不保证一定会按照这个依赖关系和权重进行资源的分配;
虽然看上去似乎有违直觉,可是,我们不能因为高优先级的请求block了,而不顾低优先级的任务;
One connection per origin: 每个源,都有个连接
即多路复用.
有了新的分帧机制后,HTTP/2 不再依赖多个 TCP 连接去并行复用数据流;
每个数据流都拆分成很多帧,而这些帧可以交错,还可以分别设定优先级。
因此,所有 HTTP/2 连接都是持久化的,而且每个来源仅需一个连接.
大多数的HTTP连接都是急促而短暂的,但是TCP对于长连和批量数据进行了优化. 通过复用连接,提高了连接的利用率,也降低了协议的开销.
可以减少占用的内存和处理空间,也可以缩短完整连接路径;
连接数量减少,可以减少开销较大的 TLS 连接数、提升会话重用率,以及从整体上减少所需的客户端和服务器资源。
Flow control: 流控制
流控制是为了防止出现,接收方繁忙,负载较高,或者仅仅只想为特定的数据流分配固定的资源,然而发送方已经不停的发送;
这和TCP的控制流类似,然而H2的多个数据流在单一的TCP连接上复用,然而TCP的控制不够精细,也为提供应用级别的API来控制单一流的传输控制.
H2提供了一组简单的构建块, 来允许客户端和服务端各自的流级别和连接级别的控制;
- 流控制是有方向性的. 每个接收方都可以为每个流或者整个连接设置自己期望的窗口大小.
- 流控制是基于信用的. 每个接收方通告自己的初始连接,初始流的控制窗口的大小(以字节为单位). 任何时候,发送方可以通过发射一个 DATA 帧来减少窗口的大小; 接收方可以发送一个 WINDOW_UPDATE 帧来实现窗口的增大;
- 流控制是不能禁用的. 当H2的连接建立之后,客户端和服务端相互交换了 SETTINGS 帧,这个帧交换起到了设置双方在两个方向上窗口的大小. 默认的控制窗口的大小是65535字节,但是接收方是可以在收到任何数据时,通过发送WINDOW_UPDATE帧来设置一个大的 "最大窗口大小": 2^31-1 个字节来维持这一窗口大小.
- 流控制是跳到跳的,而不是端到端的. 也就是说,一个中间人可以基于自身的条件和启发式的算法,使用流控制来控制资源使用和实现资源费分配机制.
H2未指定任何的流控制算法,替代的,提供了构建块将具体的算法实现交给了客户端和服务端,实现自定义的策略,以实现资源分配和资源的使用; 也可以实现自定义的传输能力以提高真实和感知性能.
举例: 应用层流控制允许浏览器将流控制窗口设置为0 ,以达到暂停一部分流的加载,先加载优先级更高的流,等到适当的时候再通过调整窗口的大小以重新恢复低优先级的资源加载.
Server push: 服务器推送
H2可以实现向客户端发送多个响应. 即可实现无需客户端主动请求的情况,实现对客户端的推送.
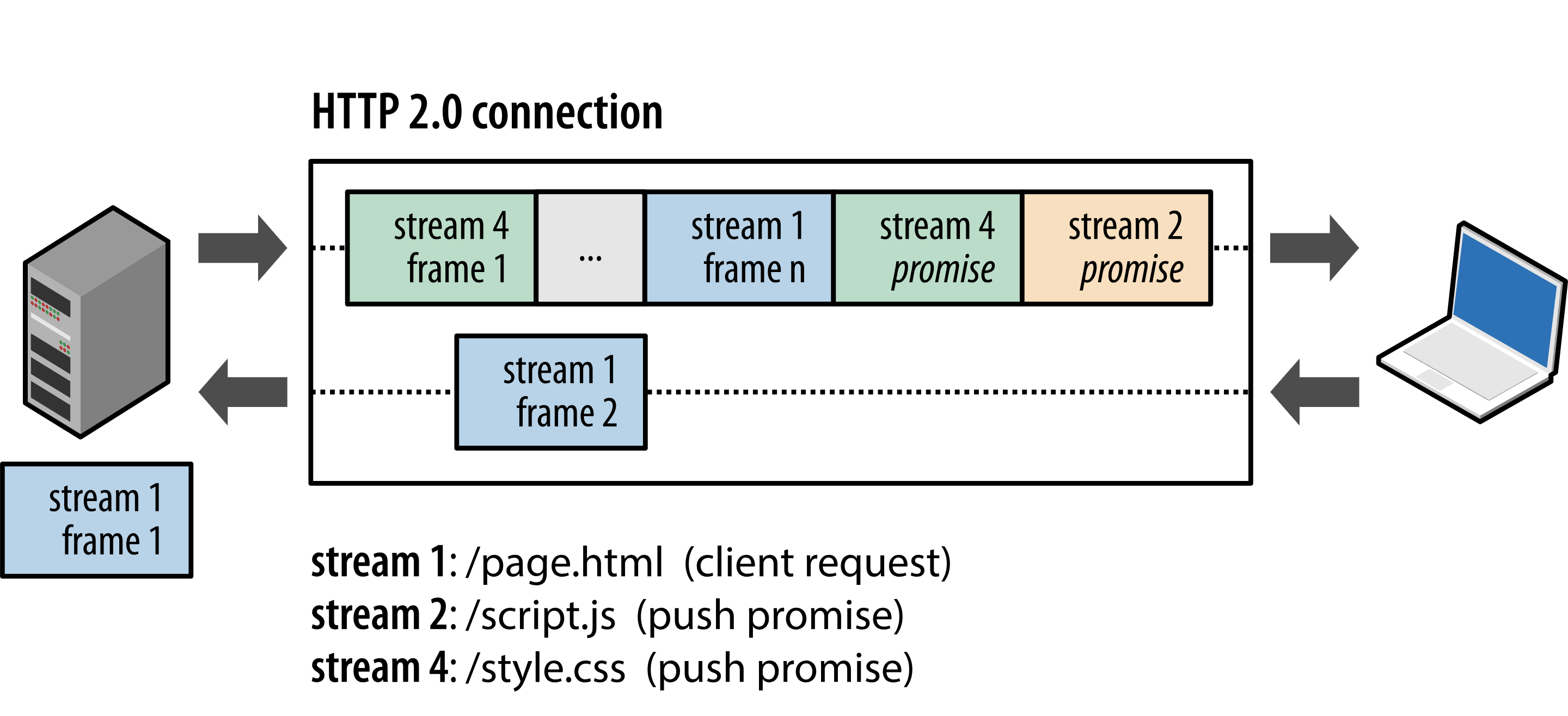
如图所示,除了stream1 是主动请求,其他的都是服务端主动推送的.
注意: H2打破了原先的请求响应语义;支持一对多和服务器发起的工作流,
PUSH_PROMISE 101:
所有服务器推送数据流都由PUSH_PROMISE帧发起,以表明了服务器向客户端推送所述资源的意图,并且需要先于客户端对于该推送资源的请求。
故而传输顺序非常重要:客户端需要了解服务器打算推送哪些资源,以免对这些资源创建重复请求。 满足此要求的最简单策略是,先于父响应(即,DATA帧)发送所有PUSH_PROMISE帧,其中包含所承诺资源的 HTTP 标头,这样客户端就知道哪些资源是服务端打算推送的。
在客户端接收到PUSH_PROMISE帧 后,它可以根据自身情况选择拒绝数据流(通过RST_STREAM帧)。 (例如,如果资源已经位于缓存中,便可能会发生这种情况。). 这是一个相对于 HTTP/1.x 的重要提升。 相比之下,使用资源内联(一种受欢迎的 HTTP/1.x“优化”)等同于“强制推送”:客户端无法选择拒绝、取消或单独处理内联的资源。
使用 HTTP/2,客户端仍然完全掌控服务器推送的使用方式。 客户端可以
- 限制并行推送的数据流数量;
- 调整初始的流控制窗口以控制在数据流首次打开时推送的数据量;
- 或完全停用服务器推送。
这些偏好设置在 HTTP/2 连接开始时通过SETTINGS帧传输,也可以随时更新。
推送的每个资源都是一个数据流,客户端可以对推送的流进行多路复用,设定优先级。
浏览器强制执行的唯一安全限制是,推送的资源必须符合原点相同这一政策:服务器对所提供内容必须具有权威性。
Header compression: header 压缩
传统H1的 header 使用的是纯文本,这会对传输过程带来500–800 字节的额外开销.
H2使用了 HPACK 压缩方式,对请求头和响应头的元数据进行压缩,进而减少开销.
采用两种技术:
- 对传输的header进行静态哈夫曼编码,可以有效减少独立传输的大小;
- 客户端和服务端同时维护和更新一份之前出现过的header字段的索引表;,随后对之前传输过的值进行编码,这份索引表将会作为参考,以提高效率;
哈夫曼编码允许对单个值在传输的时候进行压缩, 对传输过的值进行索引,这样可以在传递重复的值时,只需索引值,根据索引值,可以快速的查找和重构完整的header 的 key 和 value.
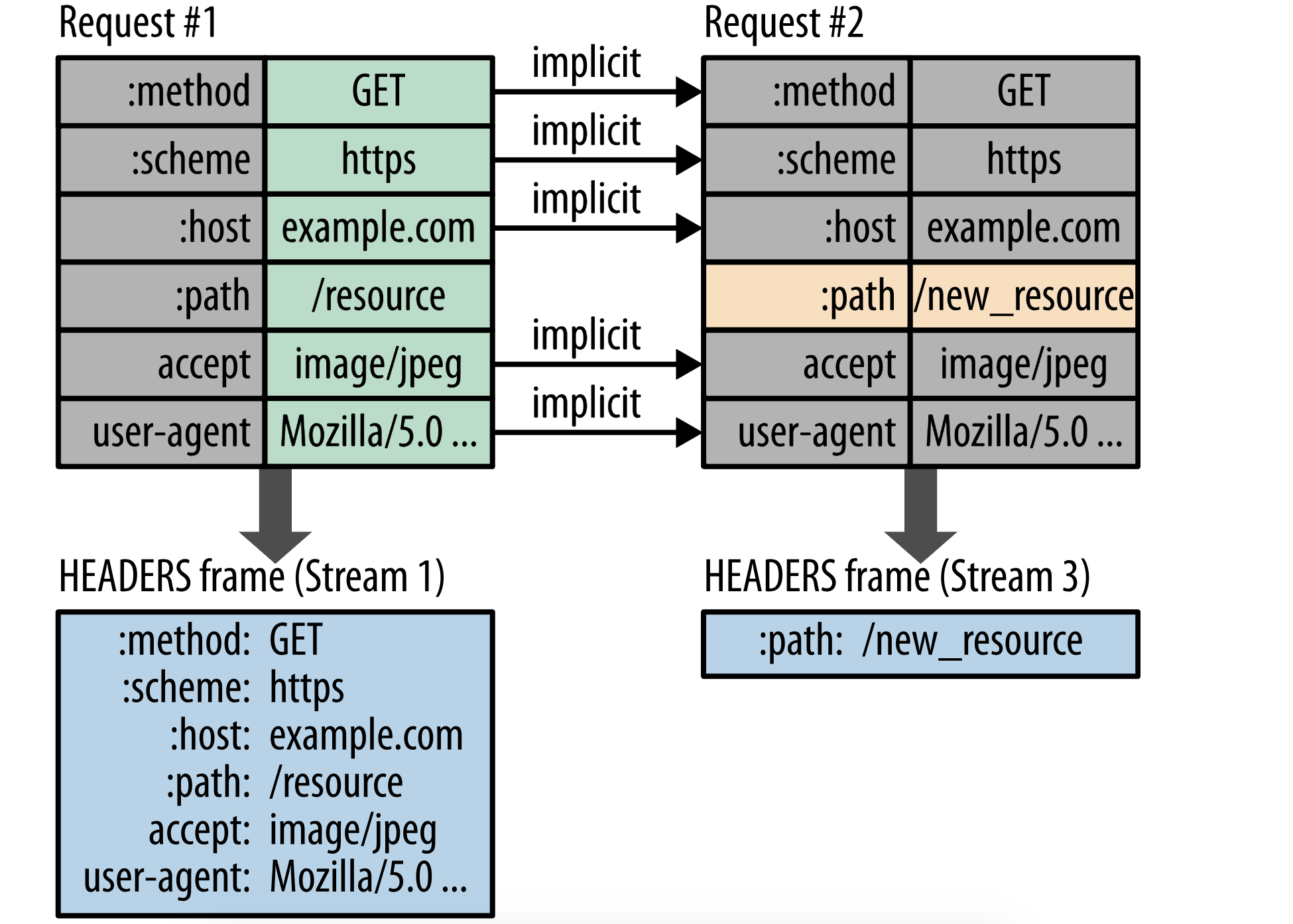
作为一个深远的优化,哈夫曼编码包含了动态表和静态表.
- 静态表包含了一些常用的HTPP header字段,这些字段是所有连接都可能使用的.
- 动态表默认是空的,在不同的连接过程中,根据交换的值不同而进行更新.
进而带来的结果是,每次请求,因为对未曾出现过的值使用了静态哈夫曼编码,对在两侧静态或者动态表中都出现的使用了索引值而不是直接的原始值,因而这次请求会因此而减小;
H2中的请求和相应的header字段的定义保持不变,仅有的一个小例外是: 所有的 header 字段的名字必须是小写, 请求行被分割成独立: :method, :scheme, :authority, 和 :path 等伪header字段.
读完文章后的待解决问题,需要更进一步的研究
- H2中的request line最终变成的格式是什么样的?
- message被切割成frame,这些frame是按照什么规则切割的?文章中的举例是 header 和 data payload .
- head-of-line blocking 是什么?
- One connection per origin这里的origin指的是什么?
- 服务器推送的条件是不是建立客户端和服务端曾经建立过连接的基础上.?同时H2是否是保证了每个连接的持久化?, H2的连接都是持久化的,可以确认;
- 压缩部分: 文中提到,H1的所有head等元数据都是纯文本,会增加传输的开销,那么,gzip呢?是如何工作的?
- HPACK 压缩格式 指的是什么?
- 静态霍夫曼代码 又指的是什么?
- 客户端和服务器同时维护和更新,那么怎么保证双方的表格和index 的一致性呢?
- 文中提到对value进行编码,那么key呢?
- 文中提到对重复的内容传递 index values ,指的是什么? 同样的问题,那怎么和对应的key对应上?
- 静态表和动态表格式是什么样的?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号