


软件工程(论文查查程序)
| 这个作业属于哪个课程 | (https://edu.cnblogs.com/campus/jmu/ComputerScience21/) |
|---|---|
| 这个作业要求在哪里 | (https://edu.cnblogs.com/campus/jmu/ComputerScience21/homework/13034) |
| 这个作业的目标 | 设计论文查重算法和程序 |
需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
GitHub链接(https://github.com/jmuhzz/jmuhzz)
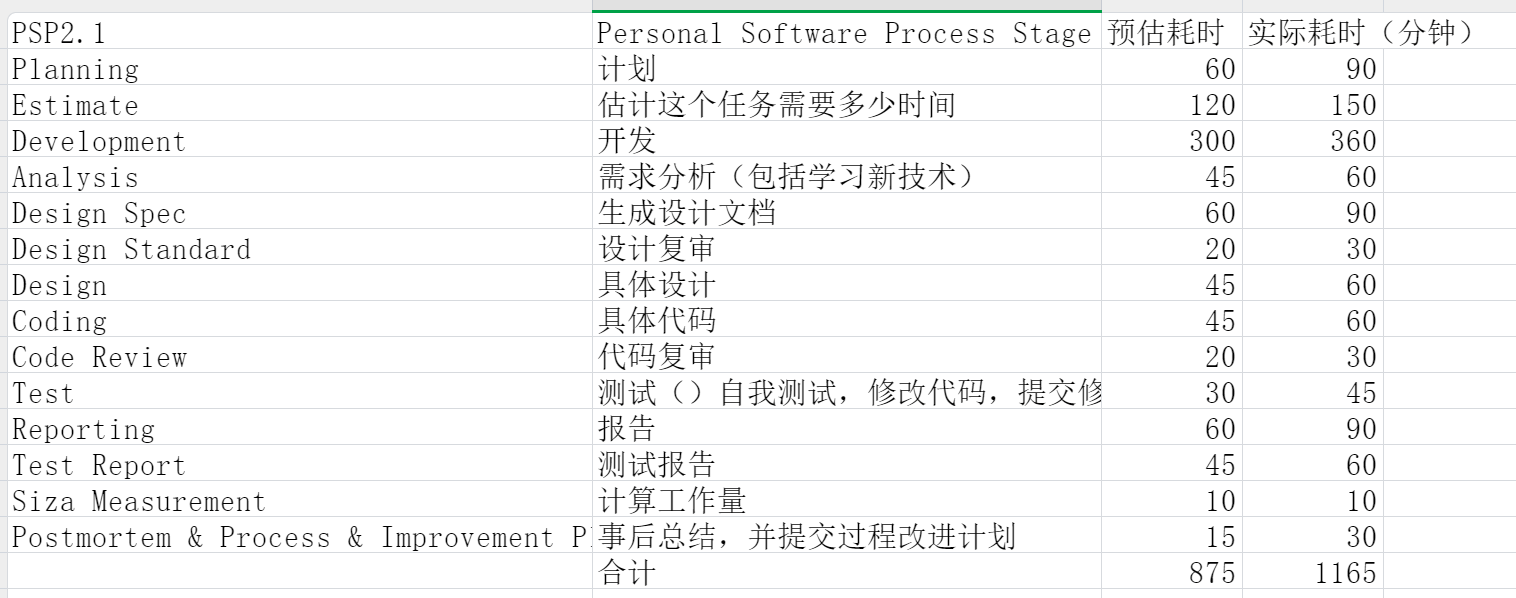
一、PSB表格
二、设计与开发
开发环境
-操作系统:windows
-编程语言:jdk 1.8
开发工具
-maven包管理工具
-idea:IDEA2020.3.1
-性能分析工具:JProfiler14.0
项目依赖
-commons-math jar包:用于提供处理余弦向量之间的计算
-hanlp-portable jar包:用于处理文本中中文词语的匹配,并转化为相应的相应的向量
算法设计与说明
1.采用余弦相似度算法来计算两文本间的余弦相似度来近似代替两文本之间的文章相似度
2.该算法是基于中文词库,将两文本中的内容转化为向量形式,接着再计算这两向量的余弦相似度来近似代替文章相似度
3.余弦相似度公式:余弦相似度 = (向量1 · 向量2) / (||向量1|| * ||向量2||),其中,向量1 · 向量2 表示向量的点积, ||向量1|| 和 ||向量2|| 表示向量的模
4.余弦相似度范围是0-1,越接近1表示两文本之间越相似,既文章相似度越高
5.独到之处:能较为简单的判断文章之间的大致相似程度,且代码实现较为简单,占用的内存和CPU都不大
接口设计与实现过程
整个项目的代码都在CosineSimilarity这一个类中,这个类的最主要功能是:计算余弦相似度,用余弦相似度近似代替文章相似度,越接近1文章间越相似
CosineSimilarity类的组成是由以下的函数实现的:
1.String readFileToString(String filePath)函数:以字符串形式从文件中将文本内容读到程序中
2RealVector getVector(String text, List words)函数:将读到的文本内容转化为词向量
3.double getCosineSimilarity(RealVector vector1, RealVector vector2)函数:将得到的词向量用于计算文本间的余弦相似度
4.void main(String[] args)函数:用于将得到的文本来测试,并得到答案
两个额外下载的jar包
1.commons-math jar包:用于提供处理余弦向量之间的计算
2.hanlp-portable jar包:用于处理文本中中文词语的匹配,并转化为相应的相应的向量
以.txt结尾的文件
这些文件是用于测试的文本
三、测试与性能分析
3.1测试
3.1.1CosineSimilarity测试
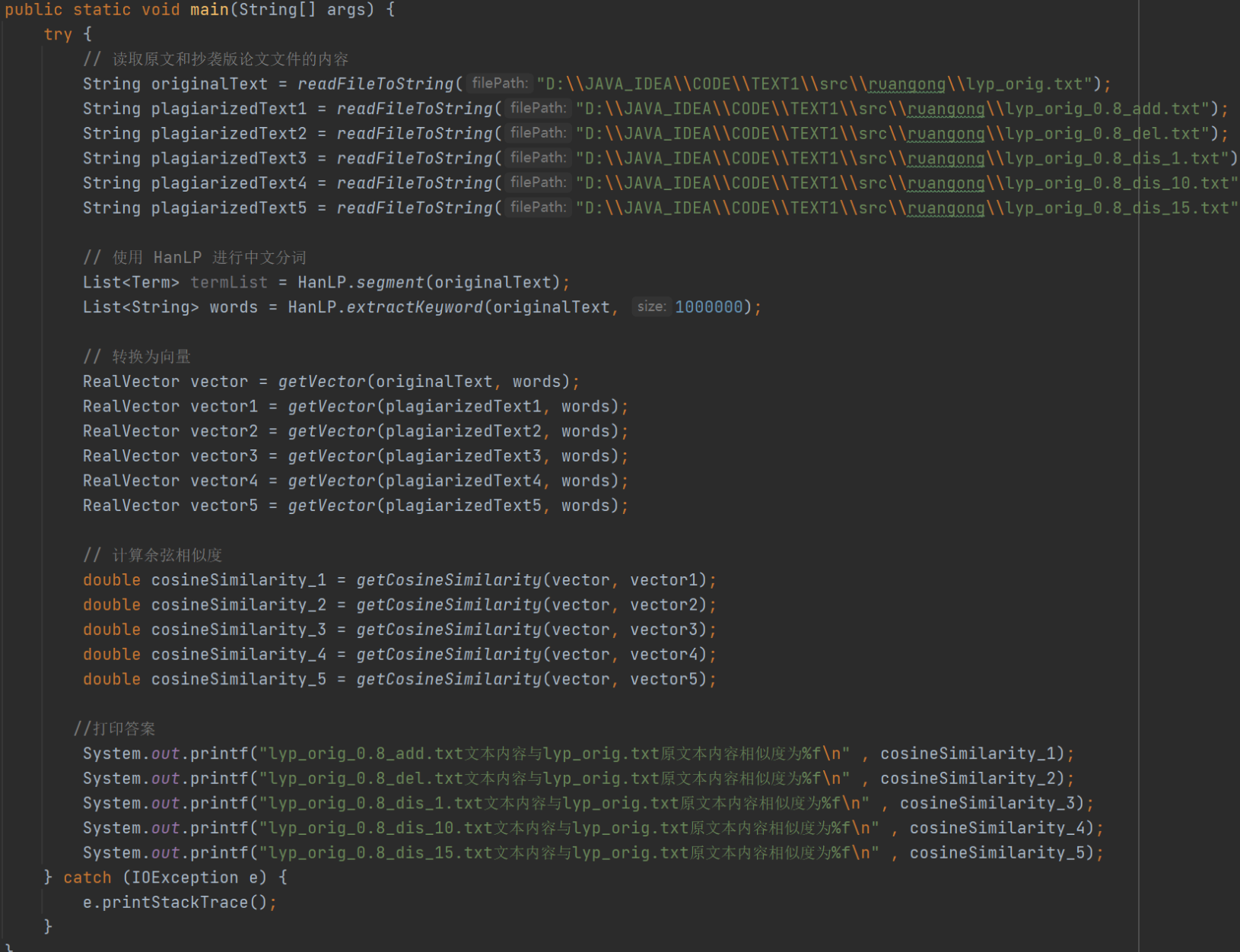
main函数代码:
3.1.2覆盖率

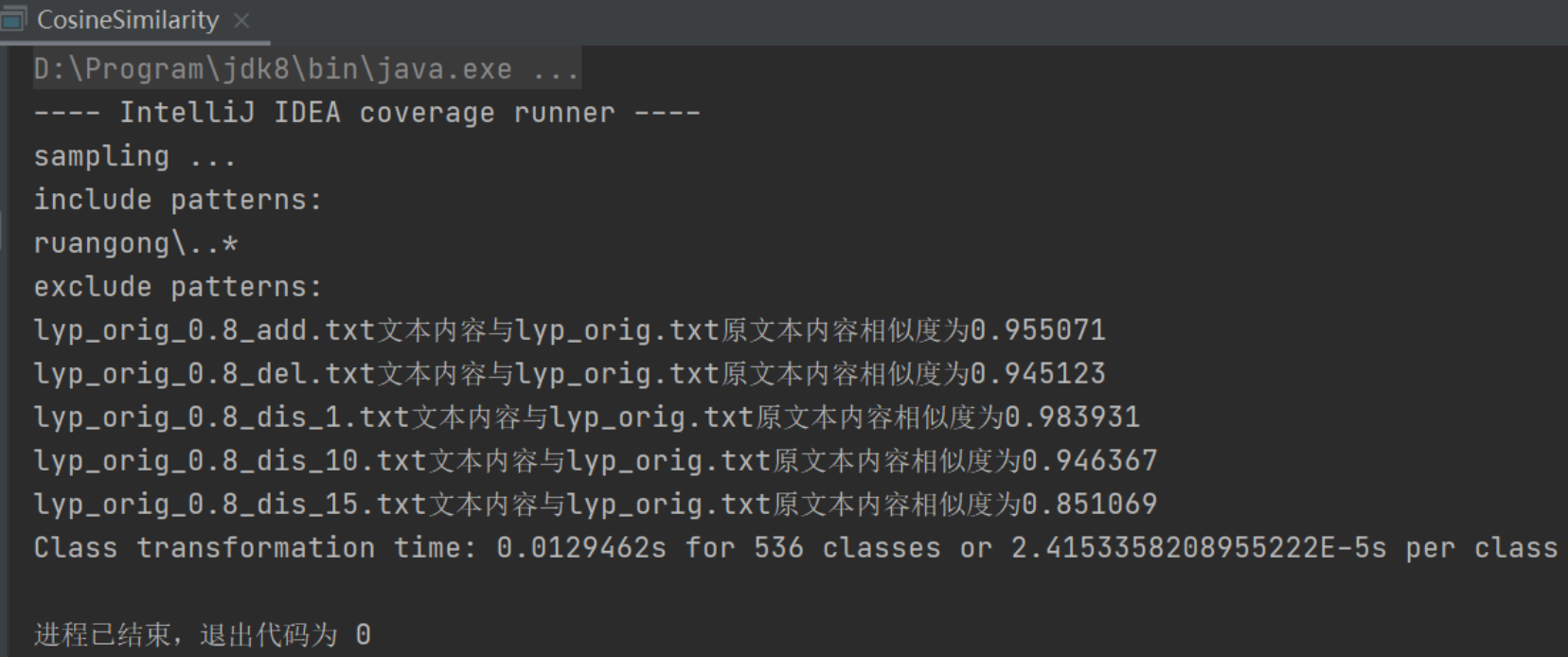
3.1.3测试结果
3.2性能分析
3.2.1Override
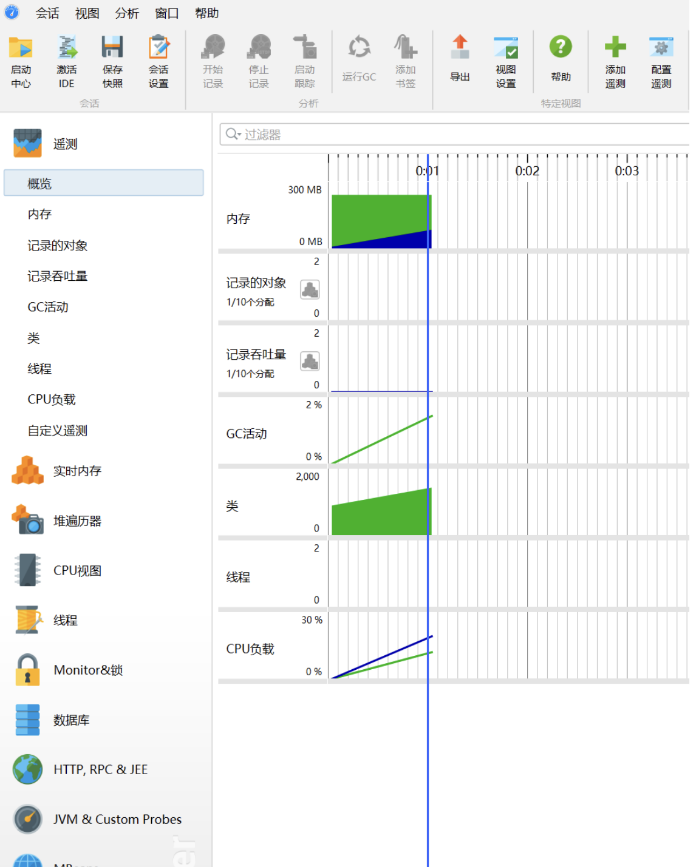
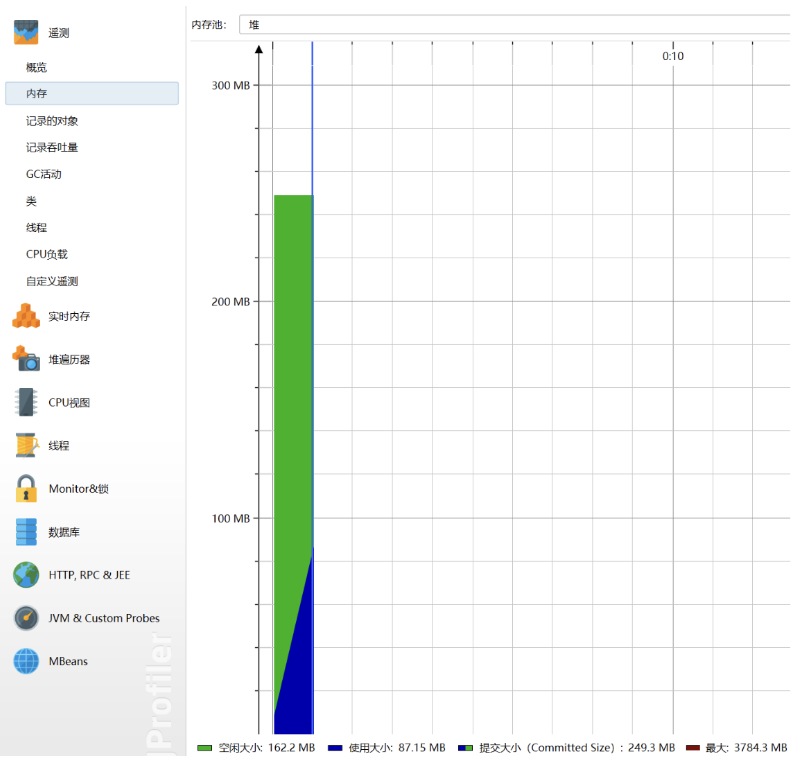
内存:
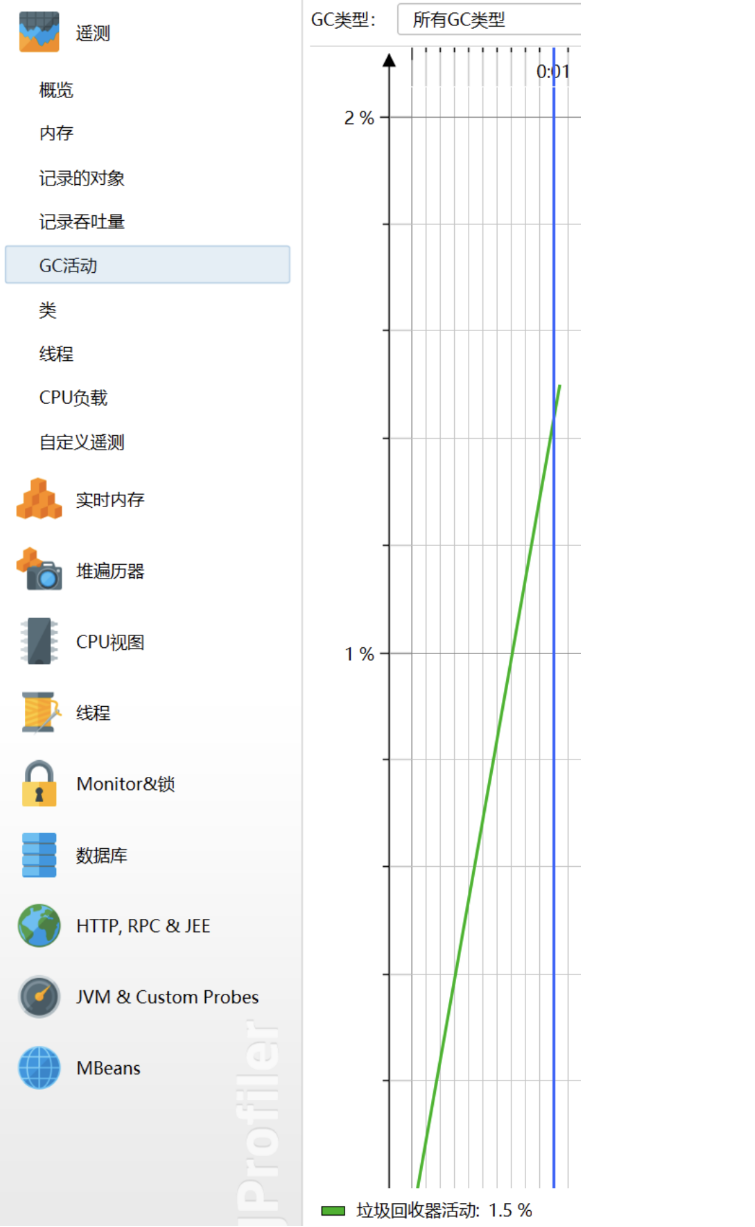
GC活动:
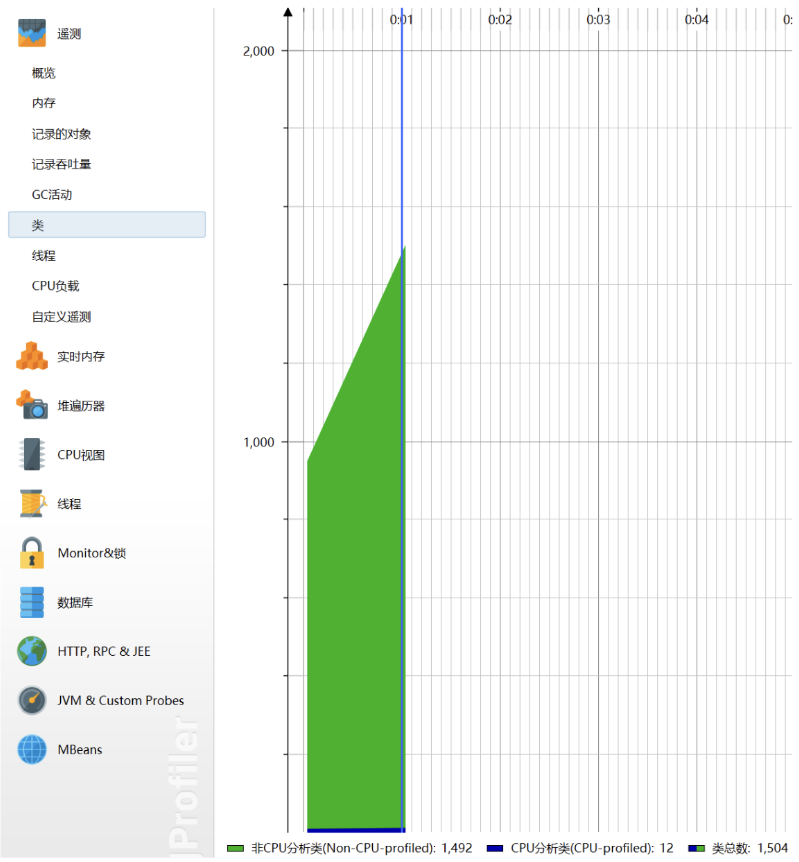
类:
CPU负载:
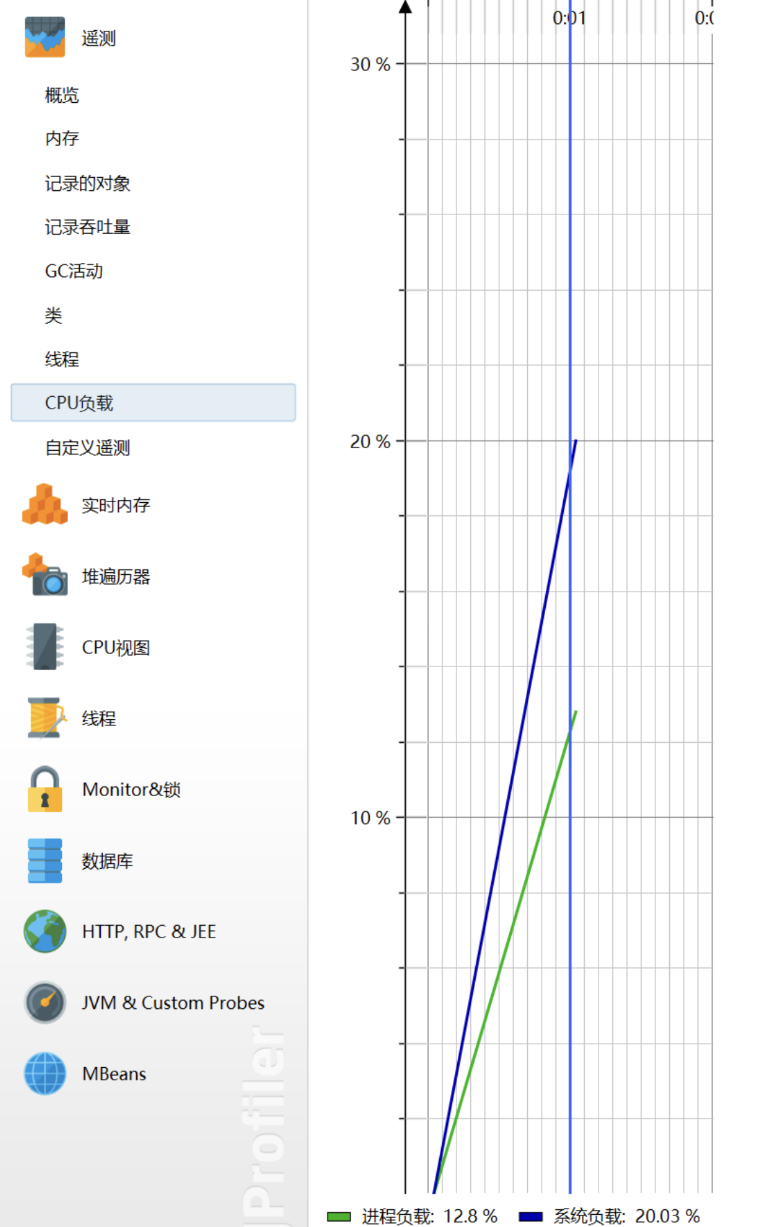
3.2.2Memory
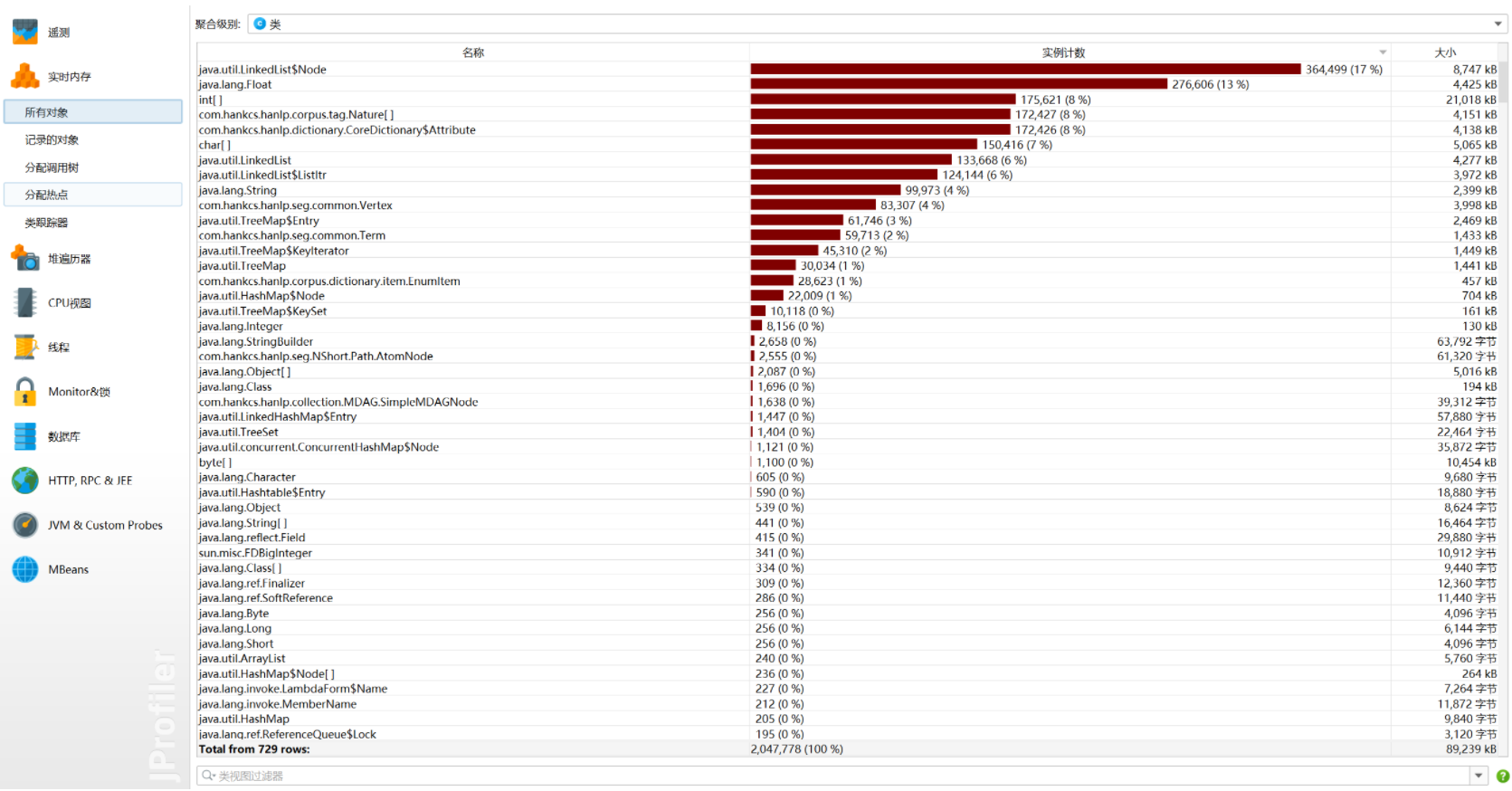
可以看出LinkList类和Float类占用的比较多,这是由于进行中文分词时加载过滤词集合以及进行计算余弦相似度时产生的
四、异常说明
1.读取文件时错误
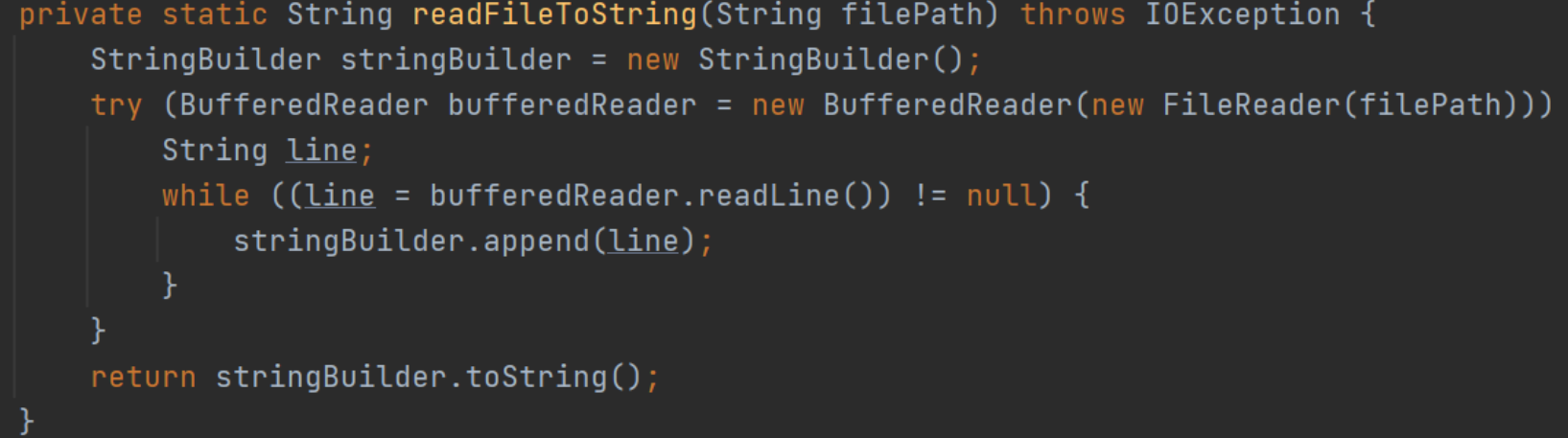
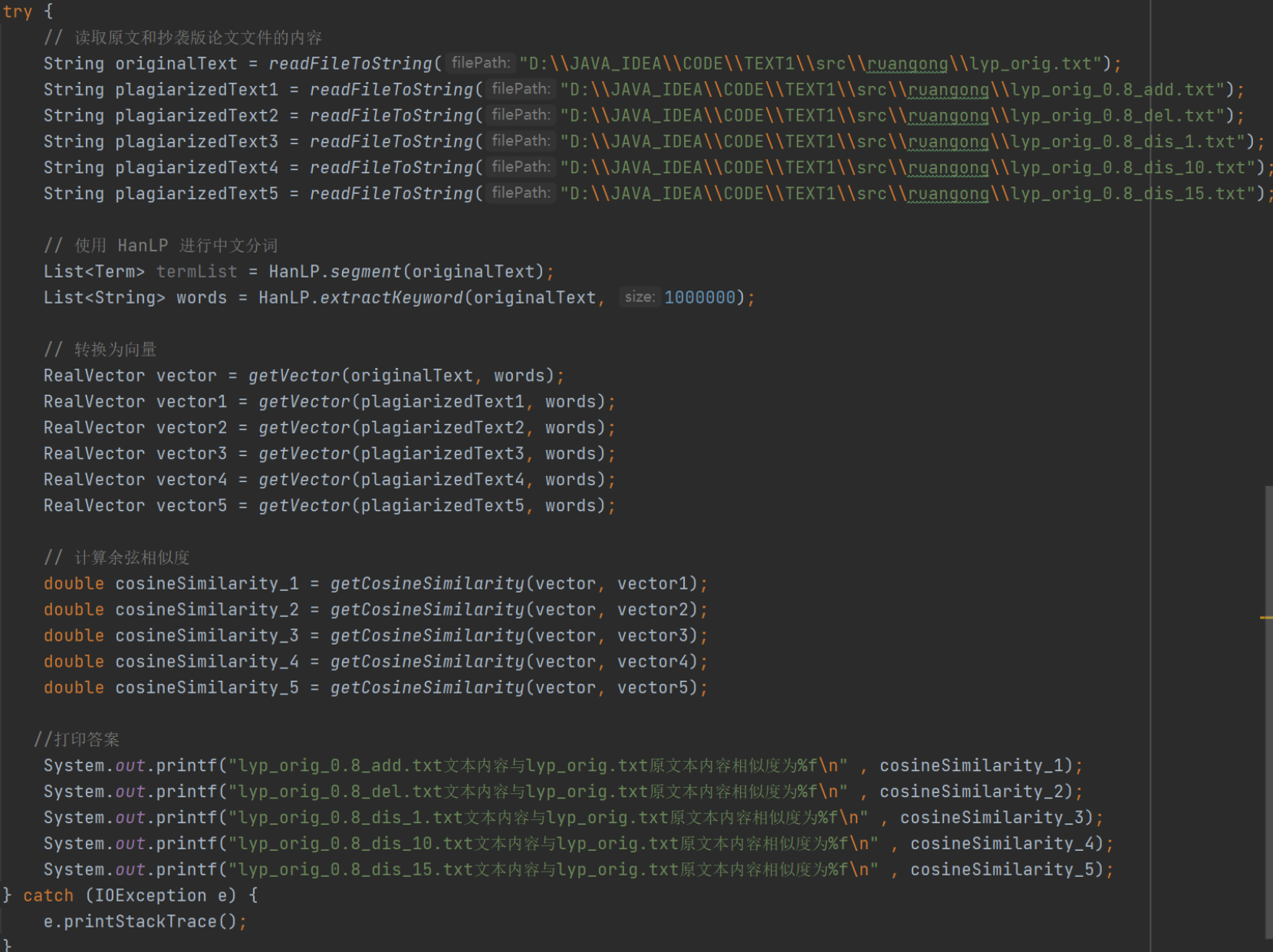
2.文件读取输出错误


 浙公网安备 33010602011771号
浙公网安备 33010602011771号