
优化器统计的目的
在我们深入研究 PostgreSQL 优化和统计之前,有必要了解 PostgreSQL 如何运行查询。典型的流程如下:
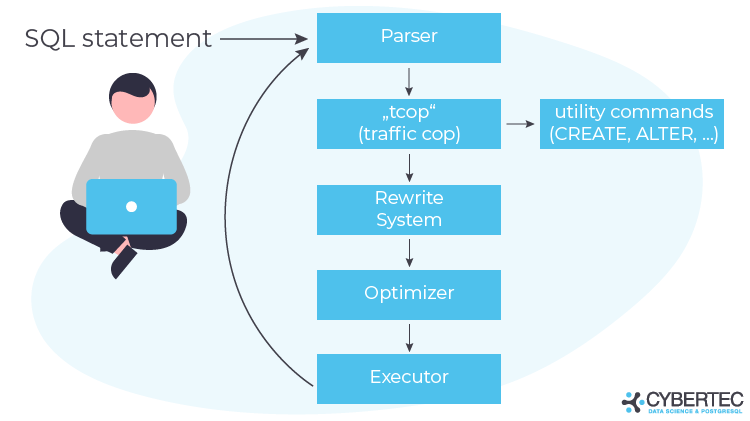
首先,PostgreSQL解析查询。然后,traffic cop将实用命令(ALTER、CREATE、DROP、GRANT等)从其他命令中分离出来。在这之后,整个事情都经过重写系统,它负责处理规则等。
接下来是优化器——它应该产生尽可能最好的计划。然后该计划可以由执行者执行。现在的主要问题是:优化器如何找到最好的计划?除了许多数学转换之外,它还使用统计信息来估计查询中涉及的行数。我们来看看:
test=# CREATE TABLE t_test AS SELECT *, 'hans'::text AS name
FROM generate_series(1, 1000000) AS id;
SELECT 1000000
test=# ALTER TABLE t_test ALTER COLUMN id SET STATISTICS 10;
ALTER TABLE
test=# ANALYZE;
ANALYZE
我创建了 100 万行,并告诉系统计算这些数据的统计信息。为了使内容适合我的网站,我还告诉 PostgreSQL 降低统计的精度。默认情况下,统计目标是 100。但是,我决定在这里使用 10,以使内容更具可读性 - 稍后会详细介绍。
现在让我们运行一个简单的查询:
test=# explain SELECT * FROM t_test WHERE id < 150000;
QUERY PLAN
---------------------------------------------------------------
Seq Scan on t_test (cost=0.00..17906.00 rows=145969 width=9)
Filter: (id < 150000)
(2 rows)
我们在这里看到的是 PostgreSQL 期望顺序扫描返回 145.000 行。此信息非常重要,因为如果系统知道会发生什么,它可以相应地调整其策略(索引、无索引等)。就我而言,只有两个选择:
- 顺序扫描
- 并行顺序扫描。
test=# explain SELECT * FROM t_test WHERE id < 1;
QUERY PLAN
---------------------------------------------------------------
Gather (cost=1000.00..11714.33 rows=1000 width=9)
Workers Planned: 2 -> Parallel Seq Scan on t_test (cost=0.00..10614.33 rows=417 width=9)
Filter: (id < 1)
(4 rows)
我所做的就是更改 WHERE 子句中的数字,突然间,计划发生了变化。第一个查询需要一个相当大的结果集;因此,启动并行性没有什么用处,因为在收集节点中收集所有这些行的成本太高。在第二个示例中,seq 扫描很少产生行 - 因此并行查询是有意义的。
为了找到最佳策略,PostgreSQL 依靠统计数据为优化器提供预期结果的指示。统计数据越好,PostgreSQL 就越能优化查询。
检查优化器统计信息
如果你想看看PostgreSQL使用了哪一种数据,你可以看一下pg_stats是哪个视图向用户显示统计信息。这是视图的内容:
test=# \d pg_stats
View "pg_catalog.pg_stats"
Column | Type | Collation | Nullable | Default
------------------------+----------+-----------+----------+---------
schemaname | name | | |
tablename | name | | |
attname | name | | |
inherited | boolean | | |
null_frac | real | | |
avg_width | integer | | |
n_distinct | real | | |
most_common_vals | anyarray | | |
most_common_freqs | real[] | | |
histogram_bounds | anyarray | | |
correlation | real | | |
most_common_elems | anyarray | | |
most_common_elem_freqs | real[] | | |
elem_count_histogram | real[] | | |
让我们一步一步地分析一下规划器可以使用哪些类型的数据:
- schemaname + tablename + attname:对于每个模式中每个表的每一列,PostgreSQL 将存储一行数据。
- inherited:我们是否正在查看继承/分区表?
- null_fraction:列中包含 NULL 值的百分比是多少?
WHERE col IS NULL如果您有或WHERE col IS NOT NULL”之类的内容,这一点很重要 - avg_width:列的平均预期宽度是多少?
- n_distinct:列中不同条目的预期数量
- most_common_vals:我们拥有最常出现的值的更精确信息。如果表中的条目分布不均匀,这一点尤其重要。
- most_common_freqs:这些最常见值的频率是多少?PostgreSQL 在此存储百分比值。例如:“男性”是一个频繁的条目,54.32% 的条目是男性。
- histogram_bounds:PostgreSQL 使用直方图来存储数据的分布。如果统计目标为 100,数据库将存储 101 个条目以指示数据内的边界(1% 步长)。
- correlation:优化器还想了解有关磁盘上数据的物理顺序的信息。如果数据按顺序(1、2、3、4、5、6、...)或随机(6、1、2、3、5、4、...)存储,则会有所不同。如果我们正在寻找范围,则需要更少的块来读取排序的数据。如果您想使用 BRIN 索引,这一点尤其重要。
最后,还有一些与数组相关的条目——但我们暂时不用担心这些。相反,让我们看一些示例内容:
test=# \x
Expanded display is on.
test=# SELECT * FROM pg_stats WHERE tablename = 't_test';
-[ RECORD 1 ]----------+---------------------------------------------------------------------------
schemaname | public
tablename | t_test
attname | id
inherited | f
null_frac | 0
avg_width | 4
n_distinct | -1
most_common_vals |
most_common_freqs |
histogram_bounds | {47,102906,205351,301006,402747,503156,603102,700866,802387,901069,999982}
correlation | 1
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |
-[ RECORD 2 ]----------+---------------------------------------------------------------------------
schemaname | public
tablename | t_test
attname | name
inherited | f
null_frac | 0
avg_width | 5
n_distinct | 1
most_common_vals | {hans}
most_common_freqs | {1}
histogram_bounds |
correlation | 1
most_common_elems |
most_common_elem_freqs |
elem_count_histogram |
在此清单中,您可以看到 PostgreSQL 对我们的表了解多少。在“id”列中,直方图部分最重要:“{47,102906,205351,301006,402747,503156,603102,700866,802387,901069,999982}”。PostgreSQL认为最小值是47。10%小于102906,20%预计小于205351,依此类推。这里还有趣的是n_distinct:-1 基本上意味着所有值都不同。如果您正在使用,这一点很重要GROUP BY。在 GROUP BY 的情况下,优化器想要知道期望有多少个组。n_distinct在许多情况下用于为我们提供该估计。
在“name”列中,我们可以看到“hans”是最常见的值(100%)。这就是为什么我们没有得到直方图。
当然,关于 PostgreSQL 优化器的运行方式还有很多可说的。然而,首先,对 Postgres 使用统计数据的方式有一个基本的了解是非常有用的。
自动清理和统计
一般来说,PostgreSQL 几乎自动生成统计信息。autovacuum 守护进程负责定期更新统计数据。统计数据是正确优化查询所需的燃料。这就是为什么它们非常重要。
如果您想手动创建统计信息,您可以随时运行ANALYZE. 然而,在大多数用例中,autovacuum 就可以了。
