
day16-常用模块之re,json,pickle,time,datetime和random模块
今日内容:
昨天我们讲了一个常用模块logging. 今天我们接着讲其他的常用模块
一、re模块
在我们学习re模块之前,我们得先了解什么是正则表达式.
那什么是正则表达式呢?
官方的介绍是:
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
目的:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的
1.给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”)
2.可以通过正则表达式,从字符串中获取我们想要的特定部分。
正则表达式的特点是:
-
灵活性、逻辑性和功能性非常强;
-
可以迅速地用极简单的方式达到字符串的复杂控制。
符号
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,我们下面会给予解释。
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。例如,正则表达式"testing"中没有包含任何元字符,它可以匹配"testing"和"testing123"等字符串,但是不能匹配"Testing"。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\n”匹配\n。“\n”匹配换行符。序列“\”匹配“\”而“(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ | 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo能匹配“z”,也能匹配“zo”以及“zoo”。等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(,+,?,{n},{n,},{n,m*})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
| .点 | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“(”或“)”。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| (?<!pattern) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。*python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
| *num* | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| *n* | 标识一个八进制转义值或一个向后引用。如果*n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n*为一个八进制转义值。 |
| *nm* | 标识一个八进制转义值或一个向后引用。如果*nm之前至少有nm个获得子表达式,则nm为向后引用。如果*nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则*nm将匹配八进制转义值nm*。 |
| *nml* | 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
| \p | 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。其他六个属性:L:字母;M:标记符号(一般不会单独出现);Z:分隔符(比如空格、换行等);S:符号(比如数学符号、货币符号等);N:数字(比如阿拉伯数字、罗马数字等);C:其他字符。**注:此语法部分语言不支持,例:javascript。* |
| <> | 匹配词(word)的开始(<)和结束(>)。例如正则表达式<the>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
其实正则表达式的组合千变万化,可能一百个人里面对同一种功能的实现,可以用用多种不同的方案.
有个图来自 正则表达式之道

案例集合
而且你要完全记住也是很难的,所以下面是我的一些案例集合,方便大家理解.
findall() 方法,第一个参数为匹配的正则表达式,第二个参数为匹配的字符,返回的是所有匹配上的一个列表
import re
print(re.findall('abc', 'abc aac accbcabc accabc')) # ['abc', 'abc', 'abc']
\w 匹配的是 字母数字下划线
print(re.findall('\w', 'hello_123 +-@!')) # ['h', 'e', 'l', 'l', 'o', '_', '1', '2', '3']
\W 匹配的是 非字母数字下划线
print(re.findall('\W', 'hello_123 +-@!')) # [' ', '+', '-', '@', '!']
\s 匹配的是 空字符 即看不见的字符
print(re.findall('\s', 'a b \n \tc123')) # [' ', ' ', '\n', ' ', '\t']
\S 匹配的是 非空字符,即看的见的字符
print(re.findall('\S', 'a b \n \tc123')) # ['a', 'b', 'c', '1', '2', '3']
\d匹配的是数字 [0-9]
print(re.findall('\d', 'a b \n \tc123')) # ['1', '2', '3']
\D 匹配的是 非数字
print(re.findall('\D', 'a b \n \tc123')) # ['a', ' ', 'b', ' ', '\n', ' ', '\t', 'c']
^ 表示 按照开头开始匹配,不是开头的字符都不匹配,所以它每次都只匹配一次
$ 表示 按照末尾开始匹配,即从最后开始匹配
str1 = 'jkey'
print(re.findall(r"\Ajkey\Z", ' zzdad jkey asf jkey ')) # []
print(re.findall(r"^jkey$", ' zzdad jkey asf jkey ')) # []
print(re.findall(r"^jkey$", str1)) # ['jkey']
print(re.fullmatch(r"^jkey$", str1).group()) # jkey
re.M 表示的是按照换行的模块,将一个整体分成多行内容,再拿正则表达式一行一行匹配
print(re.findall(r"^jkey$", """
jkey
asf
jkey
""", re.M)) # ['jkey', 'jkey']
但\A和\Z不支持M 多行模式
print(re.findall(r"\Ajkey\Z", """
jkey
asf
jkey
""", re.M)) # []
print(re.findall(r"^jkey\Z", """
jkey
asf
jkey
""", re.M)) # []
. 表示的是一个任意字符,除了换行符 在后面加上模式 re.DOTALL 就表示可以任意字符,包括换行符
print(re.findall('a.c', 'a1c a2c aAc aaaac', re.DOTALL))
print(re.findall('a.c', 'a1c a2c aAc aaaac', re.S)) # re.S 等同于re.DOTALL
[] 在 正则表达式中表示一个区间,表示的是一个字符,但这个字符可以是[]内的任意字符
注意 ^ 在[] 内为 取反的意思 [^-+*]
print(re.findall('a[0-9]c', 'a1c a2c aAc aaaac'))
print(re.findall('a[a-z]c', 'a1c a2c aAc aaaac'))
print(re.findall('a[A-Z]c', 'a1c a2c aAc aaaac'))
print(re.findall('a[-+*/]c', 'a*c a/c a-c a+c abc aac acc'))
?:左边那一个字符出现0次或者1次
print(re.findall('ab?', "b a abbbbbbbb ab")) # ['a', 'ab', 'ab']
# ab?
*:左边那一个字符出现0次或者无穷次
print(re.findall('ab*', "b a abbbbbbbb ab")) # ['a', 'abbbbbbbb', 'ab']
# ab*
+:左边那一个字符出现1次或者无穷次
print(re.findall('ab+', "b a abbbbbbbb ab")) # ['abbbbbbbb', 'ab']
# ab+
{n,m}:左边那一个字符出现n次或m次
print(re.findall('ab{2,4}', "b a abbbbbbbb ab")) # ['abbbb']
# ab{2,4}
print(re.findall('ab{2,4}', "b a abb abbb abbbbbbbb ab")) # ['abb', 'abbb', 'abbbb']
.* 表示的是匹配任意字符0-无穷个 , 默认是贪婪的, 他会一直匹配到离它最远的那个符合的字符
.*? 取消 贪婪属性, 匹配到最近的符合字符
将正则表达式用() 括起来表示一个元组,它不会影响到正则表达式对字符的匹配,但会将匹配上的字符,可以根据元组,取到元组序号对应的字符串
案例:取到字符串中的url信息
str2 = "< a href='https://www.baidu.com'>'我是百度啊'</ a>< a href='https://www.sina.com.cn'>'我是新浪啊'</ a>"
print(re.findall("href='(.*?)'", str2)) # (.*?) 表示的就是一个元组,看成一个整体.这里返回的是url列表
# href='(.*?)
一些功能对应的正则表达式:
1.验证用户名和密码:("^[a-zA-Z]\w{5,15}$")正确格式:"[A-Z][a-z]_[0-9]"组成,并且第一个字必须为字母6~16位;
2.验证电话号码:("^(\d{3,4}-)\d{7,8}$")正确格式:xxx/xxxx-xxxxxxx/xxxxxxxx;
3.验证手机号码(包含虚拟号码和新号码段):"^1([38][0-9]|4[5-9]|5[0-3,5-9]|66|7[0-8]|9[89])[0-9]{8}$";
4.验证身份证号(15位):"\d{14}[[0-9],0-9xX]",(18位):"\d{17}(\d|X|x)";
5.验证Email地址:("^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$");
6.匹配MAC地址:([A-Fa-f0-9]{2}\:){5}[A-Fa-f0-9]
7.匹配ip地址:([1-9]{1,3}\.){3}[1-9]。
8.匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
9.匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</>|<.*? />
...
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
和re.match方法一样,就是re.match方法相当于re.search方法在正则表达式开头加了^
re.sub方法
用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配
案例:
# 将字符串中的 lxx 和 sb 交换位置
print(re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)$',r'\5\2\3\4\1','lxx is sb'))
lxx(1) 空格(2) is(3) 空格(4) sb(5)
# 将lxx改成大写的LXX
print(re.sub('^\w+','LXX','lxx is sb'))
re.compile方法
可以存放一些经常使用的正则表达式
返回一个对象.对象可以直接调用re下面的方法,并且不用指定正则表达式,用存放在这的正则表达式
案例:
pattern = re.compile("egon",re.M)
print(pattern.findall("egon xxx egon"))
print(pattern.search("asdfasdfsadfegonasdfon"))
1.使用re.compile
re模块中包含一个重要函数是compile(pattern [, flags]) ,该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式。
其中,后一种调用方式中,pattern是用compile创建的模式对象。如下:
>>> import re
>>> some_text = 'a,b,,,,c d'
>>> reObj = re.compile('[, ]+')
>>> reObj.split(some_text)
['a', 'b', 'c', 'd']
2.不使用re.compile
在进行search,match等操作前不适用compile函数,会导致重复使用模式时,需要对模式进行重复的转换。降低匹配速度。而此种方法的调用方式,更为直观。如下:
>>> import re
>>> some_text = 'a,b,,,,c d'
>>> re.split('[, ]+',some_text)
['a', 'b', 'c', 'd']
好啦,正则真的要深究的话,可能得看几个月,我们记住一些常用的符号是什么意思就可以了.
下面是俩种序列化模块
json模块
1.什么是Json?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它是JavaScript的子集,易于人阅读和编写。
前端和后端进行数据交互,其实就是JS和Python进行数据交互
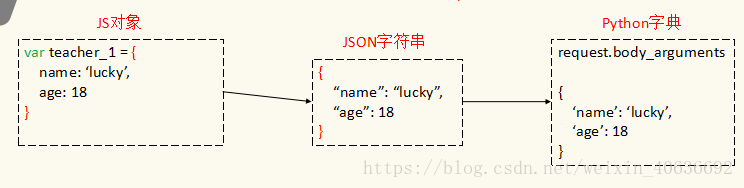
JSON注意事项:
(1)名称必须用双引号(即:””)来包括
(2)值可以是双引号包括的字符串、数字、true、false、null、JavaScript数组,或子对象。
2.python数据类型与json数据类型的映射关系
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str, unicode | string |
| int, long, float | number |
| True | true |
| False | false |
| None | null |
3. json中常用的方法
在使用json这个模块前,首先要导入json库:import json
| 方法 | 描述 |
|---|---|
| json.dumps() | 将 Python 对象编码成 JSON 字符串 |
| json.loads() | 将已编码的 JSON 字符串解码为 Python 对象 |
| json.dump() | 将Python内置类型序列化为json对象后写入文件 |
| json.load() | 读取文件中json形式的字符串元素转化为Python类型 |
json的序列化和反序列化案例
import json
# 序列化
dic = {"name":"jkey", 'xxx': True, 'yyy': None, 'zzz': 1.12}
dic_json = json.dumps(dic)
with open('a.json', 'wt', encoding='utf-8') as w_f:
w_f.write(dic_json)
json.dump(dic,open('.a.json.swap', 'wt', encoding='utf-8'))
# 反序列化
with open('a.json', 'rt', encoding='utf-8') as r_f:
res = r_f.read()
dic1 = json.loads(res)
print(dic1)
dic2 = json.load(open('a.json', 'rt', encoding='utf-8'))
print(dic2)
关于ujson和json的一些区别
在python中,还提供了一种模块,为ujson,它在处理一些 dump,dumps.load.loads这些方法的时候,效率比普通的json模块快一点,所以有些时候,你需要将之前的json模块的这些操作变成ujson时,可能别人会讲到使用一个叫猴子补丁的,其实就是给它变量重命名了
猴子补丁
import json
import ujson # pip3 install ujson
def monkey_patch_json():
"""这个就是猴子补丁"""
json.dump = ujson.dump
json.dumps = ujson.dumps
json.load = ujson.load
json.loads = ujson.loads
monkey_patch_json() # 可以在文件的开头使用一下,让之后的那些操作都变为ujson的
json的优点是:跨平台性好,用一些其他语言都有的数据类型和json相互转换.但是它并不支持python内所有的数据类型.像集合,元组这里会变成大众的数组数据类型,也就是我们python这的列表.
pickle模块
那还有一个支持所有python数据类型的序列化模块,那就是pickle
使用方法和json一样,只是这里还支持python独有的数据类型的转换.
案例:python集合用pickle模块的序列化和反序列化
import pickle
set1 = {1,2,3,56,6}
pickle.dump(set1, open('a.pkl', 'wb'))
set2 = pickle.load(open('a.pkl', 'rb'))
print(set2, type(set2))
但是我们得注意的是,使用pickle序列化保存的是一堆二进制.所以存到文件中的都是一些二进制数.
pickle优点是支持python所有的数据类型,但也只能让python使用.而且存的是一堆二进制.
俩种序列化反序列化模块,没有谁好谁坏,根据项目需求来使用对应的模块即可.
time模块
时间分为三种格式
# 1、时间戳
print(time.time()) # 1609935394.9345422 返回的是现在时间距离1970年的1月1日的0点的一个时间差,单位秒,一般用来计算时间差
# 2、格式化的字符串
print(time.strftime('%Y-%m-%d')) # 2021-01-06 将时间按照指定的格式输出,一般是给人看的
# 3、结构化的时间
res = time.localtime() # 给现在的时间按照年,月,日,小时,分钟,秒,星期几(从0开始),这一年的第几天,一个更省电的模式,一般根据变量名用来取特定的时间块
# time.struct_time(tm_year=2021, tm_mon=1, tm_mday=6, tm_hour=20, tm_min=16, tm_sec=58, tm_wday=2, tm_yday=6, tm_isdst=0)
print(res)
res2 = time.gmtime() # 和上面一样,不过上面的是东八区,就是我们本地,而这里的表示国际时间
# time.struct_time(tm_year=2021, tm_mon=1, tm_mday=6, tm_hour=12, tm_min=16, tm_sec=58, tm_wday=2, tm_yday=6, tm_isdst=0)
print(res2)
时间格式转换图:

可以按照给定的时间变量名取值
print(res.tm_year) # 2021
print(res.tm_mday) # 6
可以将时间戳,转换成结构化的时间
print(time.localtime(33331313)) # time.struct_time(tm_year=1971, tm_mon=1, tm_mday=22, tm_hour=2, tm_min=41, tm_sec=53, tm_wday=4, tm_yday=22, tm_isdst=0)
print(time.gmtime(33331313)) # time.struct_time(tm_year=1971, tm_mon=1, tm_mday=21, tm_hour=18, tm_min=41, tm_sec=53, tm_wday=3, tm_yday=21, tm_isdst=0)
可以将结构化的时间转换成时间戳
print(time.mktime(time.localtime())) # 1609935418.0
将结构化时间转换成指定的格式化时间
res3 = time.strftime("%Y-%m",time.localtime())
print(res3) # 2021-01
将指定的格式化时间转换成结构化的时间
print(time.strptime("2017-11-11 11:11:11","%Y-%m-%d %H:%M:%S")) # time.struct_time(tm_year=2017, tm_mon=11, tm_mday=11, tm_hour=11, tm_min=11, tm_sec=11, tm_wday=5, tm_yday=315, tm_isdst=-1)
显示 时间 一般用于linux
print(time.asctime()) # Wed Jan 6 20:16:58 2021
datetime模块
import datetime
# 返回的是现在的时间,是一个格式化的时间,但是这个时间可以直接进行运算
print(datetime.datetime.now()) # 2021-01-06 20:16:58.519149
# 例如:将时间变为3.5天后
print(datetime.datetime.now() + datetime.timedelta(days=3.5)) # 2021-01-10 08:16:58.519149
# 将时间变为3.5天前
print(datetime.datetime.now() - datetime.timedelta(days=3.5)) # 2021-01-03 08:16:58.519149
random模块
Python为我们提供了random库,该模块实现了各种分布的伪随机数生成器
下面介绍的都是一些基本的使用,如要详细了解,请观看官方文档: Random官方文档。
与其他库一样,首先我们导入需要的模块,如下:
import random
seed()
初始化给定的随机数种子,默认为系统的时间,通俗记忆:为了确保两次试验产生的随机数一致
random.seed(5)
print(random.randint(1, 6)) # 返回5,保证和前面设置的seed内的数值一致
print(random.seed(5)) # None 没有返回值
print(random.randint(1, 6)) # 5
# 只能保证一次,后面的还是一个随机的
print(random.randint(1, 6)) # 3
生成浮点数
random.random() 生成[0.0, 1.0) 范围内的下一个随机浮点数
# random.random() 返回的是一个0-1的小数,包括0.0,不包括1.0
print(random.random()) # 0.7417869892607294
# 可以搭配运算符
print(random.random() * 10) # 7.951935655656967
random.uniform(a,b) 生成[a,b]之间的随机小数
print(random.uniform(1, 10)) # 9.482052553993453
生成随机整数
random.randrange(start,stop,step) 生成start开始,stop结束的整数([start,stop)),步长可以省略
print(random.randrange(1, 10, 3)) # 7
random.randint(a,b) 生成[a,b]之间的随机整数
print(random.randint(1, 10)) # 9
random.getrandbits(k) 生成k比特长的随机整数(不太经常使用)
print(random.getrandbits(10)) # 29
随机选择和打乱
random.choice(seq) 从非空序列seq中选择某个值
print(random.choice([1, 2, "axx", 3.1])) # 3.1
random.sample(population, k) 返回从总体序列或集合中选择的唯一元素的 k 长度列表。 用于无重复的随机抽样。
print(random.sample([1, 2, "axx", 3.1], 2)) # [2, 'axx']
random.shuffle(seq) 对seq打乱重排
item = [1, 3, 5, 7, 9]
random.shuffle(item)
print(item) # [5, 7, 9, 3, 1]
来个具体实例:生成一个由数字和字母组成的验证码,位数为可变
再做这个案例之前,我们得了解俩个内置方法
ord()函数就是用来返回单个字符的ascii值(0-255)
chr() 函数是输入一个整数【0,255】返回其对应的ascii符号
这里的a-z对应的数字为97- 122,A-Z对应的为65-90
def make_code(size=4):
res = ''
for i in range(size):
num = str(random.randint(0, 9))
low_world = chr(random.randint(65, 90))
upper_world = chr(random.randint(97, 122))
res += random.choice([num, low_world, upper_world])
return res
print(make_code(6))
本章总结
1.re模块,记住一些常用的字符
\w 表示字母数字下划线
\W 表示非字母数字下划线
\s 表示空白字符
\S 表示非空白字符
\d 表示匹配数字 即 [0-9]
\D 表示匹配非数字 [^0-9]
\A 表示匹配的以什么开头(不能换行模式匹配)
\Z 表示匹配以什么结尾(不能换行模式匹配)
^ 表示匹配的以什么开头(可以换行模式匹配,re.M)
$ 表示匹配以什么结尾(可以换行模式匹配,re.M)
. 表示匹配任意字符,除非换行字符,但可以指定模式.re.S
* 表示匹配0次或者无穷次
+ 表示匹配1次或者无穷次
? 表示匹配0次或者1次 一般用于取消贪婪匹配
[] 表示一个字符,中括号内可以是多个字符,是或者的意思
{} 表示取多个字符,为一个闭区间
() 可以将正则表达式中的其中一段括起来,例如findall将匹配成功的过滤除括号内的放到列表中
(?:) 可以取消分组
一些常用的re方法
findall()第一个参数为表达式,第二个为匹配的字符串,第三个为可选参数[匹配的模式]
search() 和findall一样使用,不过只返回第一次匹配成功的字符
match()和search一样,但是要匹配开头,开头没匹配上,就返回None.相当于在search的正则表达式前面加了^
2.俩种序列化反序列化模块
2.1 json 模块
序列化:
- dump(obj,ftp)
- obj为json类型的数据
- ftp为文件对象
- dumps(obj)
反序列化:
- load(obj,ftp)
- loads(obj)
优点:跨平台性强,但不支持所有的python数据类型
2.2 pickle模块
和json使用方法一样
优点:支持所有的python数据类型,但只能被python语言使用
3.time和datetime模块
3.1 time模块
- 记住三个格式即可
- 1.时间戳的格式,一般用于运算
- time.time()
- 2.格式化格式
- 指定的格式输出,一般给人看的
- time.strtime("%Y-%m%d %H:%M%S")
- 指定的格式输出,一般给人看的
- 3.时间元组
- 一个时间的所有信息的一个元组,可以通过元组内的变量名取值
- time.localtime()
- 一个时间的所有信息的一个元组,可以通过元组内的变量名取值
- 1.时间戳的格式,一般用于运算
3.2 datetime模块
- 查看当前时间
- datetime.datetime().now()
- 返回的是一个格式化后的时间,但是这个时间可以进行运算
- datetime.datetime().now()
4.random模块
random.random()返回的是一个[0.0-1.0)之间的小数,不包括1.0
random.unifrom(a,b) 返回的是一个[a-b]之间的小数
random.randrange(a,b,s) 返回的是一个随机的a-b内的整数 ,c步长可以不指定
random.randint(a,b) 返回[a-b]内的随机的一个整数
random.choice(seq) 随机返回一个非空seq列表内的元素
random.sample(seq,2) 随机返回指定个数的seq内的元素
random.shuffle(seq) 将seq这个列表打乱顺序
下面有一个小练习:引用了以上的模块
练习为:注册登录小练习
# 目录结构 即其内部代码
- conf
- settings.py
# -*- coding: utf-8 -*-
# @Author : JKey
# Timer : 2021/1/7 8:54
import os
USER_INFO = {}
PHONE_LIST = []
BASE_DIR = os.path.dirname(os.path.dirname(__file__))
A1_LOG = f'{BASE_DIR}/log/a1.log'
A2_LOG = f'{BASE_DIR}/log/a2.log'
standard_format = '%(asctime)s %(filename)s:%(lineno)d %(name)s %(levelname)s %(message)s'
simple_format = '%(asctime)s %(message)s'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到文件的日志,收集info及以上的日志
'file1': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'standard',
'filename': A1_LOG,
'encoding': 'utf-8',
},
'file2': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'standard',
'filename': A2_LOG,
'encoding': 'utf-8',
},
#打印到终端的日志
'stream': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
# 其中''表示的是默认的,即不管什么名称,只要没匹配上,其他的key,就都使用该''key里面的配置
'': {
'handlers': ['file1','file2','stream'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'提示日志': {
'handlers': ['stream'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'ERROR', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
},
}
- core
- src.py
# -*- coding: utf-8 -*-
# @Author : JKey
# Timer : 2021/1/7 8:33
import re, datetime
import os
from conf import settings
from lib import common
def register():
"""注册"""
user_name = input('请输入您的用户信息>>>:').strip()
register_logger = common.get_logger(user_name)
path = fr'db\{user_name}.pkl'
if os.path.exists(path):
register_logger.error(f"用户{user_name}已被注册")
return
pwd = input('请输入您的密码>>:').strip()
pwd2 = input('请确认您的密码>>:').strip()
if pwd == pwd2:
inp_phone_num = input('请输入您绑定的手机号>>>:').strip()
re_phone = "^1([38][0-9]|4[5-9]|5[0-3,5-9]|66|7[0-8]|9[89])[0-9]{8}$"
if not re.search(re_phone, inp_phone_num):
register_logger.error('请输入有效的手机号码')
return
common.save_file('db/phone_info.pkl', settings.PHONE_LIST)
settings.PHONE_LIST = common.get_info('db/phone_info.pkl')
if inp_phone_num in settings.PHONE_LIST:
register_logger.error(f'手机号{inp_phone_num}已被其他绑定,注册失败')
return
res = common.make_code()
print(f'您的验证码为{res}') # 模拟向手机发送验证码
code = input('请输入您的验证码>>:').strip() # 模拟验证码验证
if code == res:
settings.USER_INFO['user_name'] = user_name
settings.USER_INFO['pwd'] = pwd
settings.USER_INFO['phone_num'] = inp_phone_num
settings.USER_INFO['user_time_status'] = datetime.datetime.now()
common.save_file(path, settings.USER_INFO)
settings.PHONE_LIST.append(inp_phone_num)
common.save_file('db/phone_info.pkl', settings.PHONE_LIST)
register_logger.info(f'恭喜{user_name}注册成功')
else:
register_logger.error('验证码不正确')
def login():
"""登录功能"""
user_name = input('请输入您的用户信息>>>:').strip()
path = fr'db\{user_name}.pkl'
login_logger = common.get_logger(user_name)
if not os.path.exists(path):
login_logger.error(f'用户{user_name}不存在')
return
pwd = input('请输入您的密码>>:').strip()
user_file_info = common.get_info(path)
if pwd == user_file_info['pwd']:
user_file_info['user_time_status'] = datetime.datetime.now()
common.save_file(path, user_file_info)
login_logger.info(f'恭喜{user_name}登入成功')
else:
login_logger.error('密码不正确')
def run():
func_dic = {
"0": ["退出", exit],
"1": ["注册", register],
"2": ["登录", login]
}
while True:
for k, v in func_dic.items():
print(f"{k}--->{v[0]}")
choice = input("请输入您的选择编号>>>:").strip()
if choice in func_dic:
func_dic[choice][1]()
else:
print('暂不支持该功能')
- db
- lib
- common.py
# -*- coding: utf-8 -*-
# @Author : JKey
# Timer : 2021/1/7 8:56
import random, pickle
import logging.config
from conf import settings
def make_code(size=4):
res = ''
for i in range(size):
num = str(random.randint(0, 9))
low_world = chr(random.randint(65, 90))
upper_world = chr(random.randint(97, 122))
res += random.choice([num, low_world, upper_world])
return res
def get_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC)
return logging.getLogger(name)
def save_file(path, info):
with open(path, 'wb') as w_f:
pickle.dump(info, w_f)
def get_info(path):
with open(path, 'rb') as r_f:
file_info = pickle.load(r_f)
return file_info
- log
- start.py
# -*- coding: utf-8 -*-
# @Author : JKey
# Timer : 2021/1/7 8:33
from core import src
if __name__ == '__main__':
src.run()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号