在大型CDN下评估BBR
原文链接:https://blog.apnic.net/2019/11/01/bbr-evaluation-at-a-large-cdn/
1. 研究背景
1.1本实验解决什么问题?
瓶颈带宽和往返传播时间(BBR)是一种TCP拥塞控制算法,由于其可以给许多内容提供商提供更高吞吐量,它已引起了市场的广泛关注。本实验旨在探究BBR的适用场景。
2. 论文的主要研究内容
2.1实验环境
在本文中,我们将在Verizon Media的内容交付网络(CDN)工作负载的背景下评估BBR(版本1),该工作负载可交付大量(多个Tbps)的软件更新和流视频,并量化收益和对流量的影响。我们希望在大型CDN上进行这样的评估将有助于其他内容提供商为其流量选择正确的拥塞控制协议。
为了了解CDN上BBR的潜力,我们在多个阶段对BBR进行了评估,并从几个入网点(PoP)评估了对TCP流量的影响。
PoP代表位于大型都会区的缓存服务器的集中。最初,我们在PoP上执行了小型BBR测试,并且还执行了完整的PoP测试,所有流量都流向运行BBR的客户端。
为了确定客户将获得的收益,我们在测试过程中以及从套接字级别分析中测量了内部代理Web服务器日志的吞吐量。
2.1.1Full PoP test实验环境
为了大规模评估BBR的性能优势,我们在里约热内卢的PoP上对来自该PoP的网络中所有面向客户端的流量进行了完整的PoP测试。该PoP进行了有趣的案例研究,因为该区域中的位置和对等约束导致客户体验到的RTT中值比其他区域更高。
根据3.1.2中的结果,我们可以发现对于长时间运行的大文件流,可以看到BBR的好处。
2.1.2Reproducing results in a lab setting环境
为了进一步了解流之间的相互作用,我们在虚拟机(VM)中创建了一个测试平台环境,该环境捕获了我们在生产中看到的行为。我们确定了在边缘服务器上模拟不同流量类别的方法,如2.2.2中所示:
该测试的目的是重现我们在生产测试中看到的问题,特别是内部PoP流量和PoP到PoP的小型RTT流的吞吐量下降。
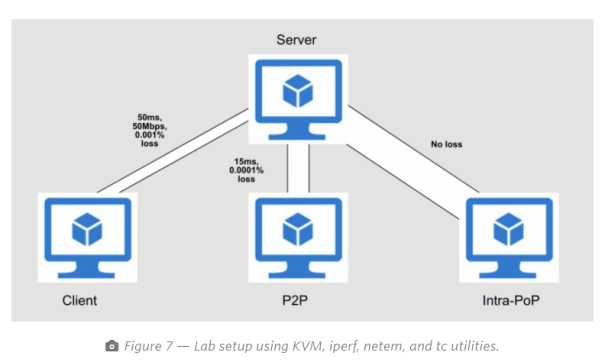
使用此设置,我们使用Cubic和BBR的模拟背景流量对模拟进行了数百次运行,并测量了完成流程所需的“时间”。后台流量的目标是模拟类似生产的环境。现有的许多研究都集中于运行一些Cubic和BBR流程并评估其行为。虽然在这些情况下了解每个流的行为很有用,但它却很难代表大型,大量CDN的复杂性。我们将客户端流完成时间用作可靠的指标,因为对于小文件而言,吞吐量可能很嘈杂。
2.2参数
2.2.1评估指标
我们的多租户CDN可以看到各种各样的客户端流量。许多客户有很多小对象,而其他客户则有更大的数千兆字节对象。因此,至关重要的是要确定成功指标,以捕获跨不同流量模式的实际性能提升。特别是,对于此评估,我们将吞吐量和TCP流完成时间确定为成功参数。
在图1中,我们显示了CDN请求的常见对象大小与服务它们所需的时间的热图。颜色渐变表示每个类别中的请求数。这些是来自一小组服务器的代表性数字,足以捕获常见的行为。
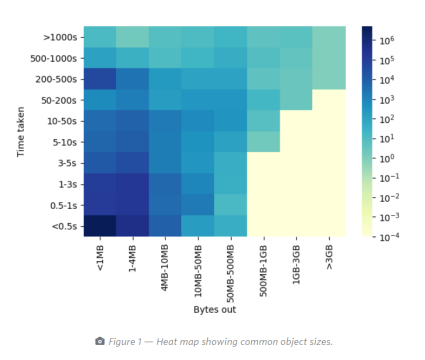
热图使我们了解了不同的请求模式。通常,获得更高的吞吐量是性能提高的最好指标。但是,作为衡量指标的吞吐量可能非常嘈杂,尤其是在对象大小较小(小于几MB)的情况下。
因此,基于对大小提供最可靠的吞吐量评估的单独评估,我们仅将大于3MB的对象大小用于吞吐量评估。对于小于3MB的对象,跟踪流完成时间是一个更好的指标。
作为评估的第一步,我们在洛杉矶PoP的几台服务器上启用了BBR,并监视了所有TCP流的吞吐量和流完成时间。以下结果检查了一些特定于Internet服务提供商的案例研究。(见图二、三)
这些测试报告的收益表明,对于客户端流量来说,结果非常可观。
由于这些收益是合计的,因此我们决定更深入地研究一下PoP上的所有TCP流量是否都看到了使用BBR的好处。还是如果某些TCP流受到影响,具体是哪个?
在CDN边缘,我们执行了四种不同类型的TCP会话:
- PoP到客户端
- PoP到PoP(数据中心之间)
- PoP内部通信(在同一PoP的缓存之间)
- PoP到来源(从PoP到客户来源的数据中心)
2.2.2Reproducing results in a lab setting参数
客户端流量延迟设置为〜50ms,损失范围为0.001至0.1,瓶颈带宽设置为50Mbps。同样,对于PoP到PoP,仅将丢失和延迟设置为〜15ms,并且将0.0001设置为0.01。对于PoP内部流量,我们让VM最大化可用容量。最后,使用各种对象大小运行模拟,以捕获流量的多租户性质。我们将所有三种流量模式与流量的指数到达并行运行,以捕获泊松式流量到达分布。图7显示了测试平台的设置。
3. 实验结果
3.1无线和有线提供商
3.1.1大型无线提供商
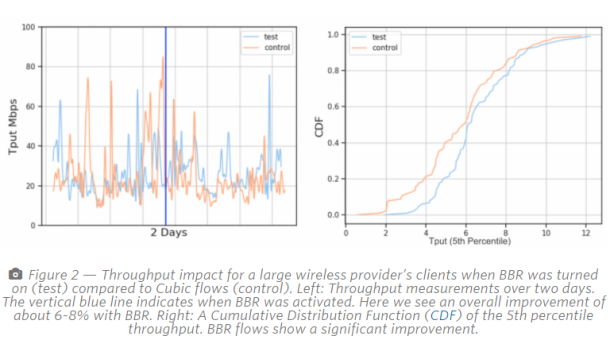
对于这个无线提供商,平均而言,一旦启用BBR,我们的吞吐量就会提高6-8%。我们也看到总体上TCP流程完成时间减少了。这一发现与Spotify,Dropbox和YouTube的其他报告相一致,在丢包很普遍的无线网络中,吞吐量明显增加,但这并不一定表示拥塞。
3.1.2大型有线提供商
接下来,我们检查了一家大型有线提供商的性能。在这里,我们还看到了使用BBR的吞吐量(对于大型对象)和流完成时间(如图3所示)的改善。

3.2在PoP上的测试
3.2.1 PoP-to-PoP and intra-PoP traffic
对于PoP到PoP和PoP内部流量吞吐量,我们看到了性能的大幅度下降。图4显示了在同一时间段内对内部PoP和PoP到PoP流量的影响:

图4 展示了,与Cubic流(对照)相比,当BBR打开(测试)时,对内部PoP和Pop-to-PoP流量的吞吐量影响。两天内的吞吐量测量。垂直的蓝线指示何时激活BBR。使用BBR的吞吐量减少了大约一半。
3.2.2 Full PoP test结果
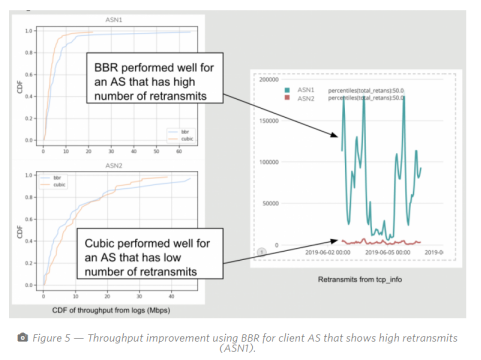
图5显示出使用BBR进行客户端AS的吞吐量改善表现出高重传(ASN1)
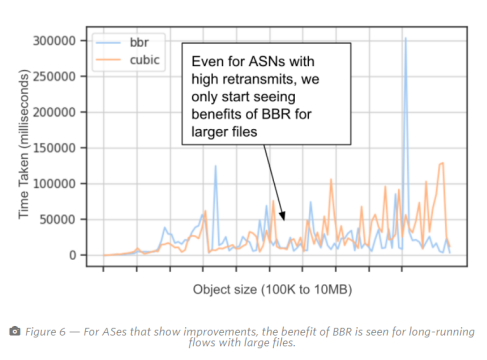
图6是不同对象大小的BBR和Cubic所花费的时间(越低,吞吐量越好)的曲线图。在这里,我们看到BBR仅以MB的顺序开始显示出较大对象的明显好处。我们确实看到了一个使用BBR的异常实例,但是无法将其归因于任何特定的与拥塞控制协议相关的问题。
3.2.3Reproducing results in a lab setting结果

在图8中,我们显示了BBR和Cubic iperf流在两种情况下所花费的CDF时间:3MB(中等大小)文件的客户端流量和PoP到PoP流量。在低丢包高带宽设置中,BBR流无法赶上Cubic。
客户端流量(低带宽)得到了改善,也就是说,BBR流花费的时间更少。但是,小文件的改进是微不足道的。
在测试环境中重现这些行为,使我们确信它们是不同流类型之间相互作用的结果。因此,在CDN上进行BBR的任何部署都必须意识到它可能对混合流类型产生更广泛的影响。
4. 结论
4.1我的思考
4.1.1两种流的对比(BBR,Cubic)
4.1.1.1BBR vs Cubic
当估计瓶颈带宽时,BBR对缓冲区大小和RTT具有高度的反应性。如果缓冲区很大,中间盒可能会排队,则BBR的RTT估计会增加。由于没有数据包丢失,因此Cubic在这种情况下不会下降。换句话说,PoP到PoP样式的流量,Cubic实现了更高的吞吐量。对于较小的缓冲区(例如无线客户端),缓冲区会迅速填充并造成丢包–因此,Cubic会下降,而BBR流的性能会更好。
4.1.1.2BBR vs BBR
在这种情况下,如果有丢包,流量就不会下降。但是,当两个具有不同RTT的流争夺带宽份额时,具有较高RTT的流也具有较大的Min RTT,因此具有较高的带宽延迟乘积(BDP)。因此,与具有较低RTT的流相比,该流以更快的速率增加了其机上数据。这导致带宽按RTT降序重新分配给流,并且具有较高RTT的流比具有较小RTT的流更快地填充缓冲区。
4.1.2BBR不具有普适性
使用BBR时,数据中心/ PoP中的流量以及数据中心之间的流量(PoP到PoP)会受到影响。在某些极端情况下,吞吐量降低了一半。但是,我们确实看到Pop-to-Client流量吞吐量提高了6-8%。
在大规模的完整PoP测试中,我们注意到BBR在重传率很高的AS情况下最有帮助,并建议对大文件使用BBR是值得的。
4.1.3BBR适合的场景
如果我们在系统级别(所有流)启用BBR,则存在PoP内和PoP到PoP流量降低吞吐量的风险。
但是,BBR对于客户端流量表现良好。这说明我们可以有选择地为客户端启用BBR。此外,这些路径具有浅缓冲和无线丢包,这是BBR比其他三次流性能更好的理想情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号