综合设计——多源异构数据采集与融合应用综合实践
综合设计——多源异构数据采集与融合应用综合实践
| 这个项目属于哪个课程 | 2023数据采集与融合技术 |
|---|---|
| 组名、项目简介 | 组名:普雷蒙奇、项目需求:多模态情感分析、项目目标:通过在网页中搜索关键词来得到一个综合的情感分析、项目开展技术路线:前端、python 、华为云平台、Django-restframework |
| 团队成员学号 | 102102112、102102115、102102116、102102118、102102119、102102120、102102156、102102159 |
| 这个项目目标 | 通过在网页中上传文本、图片、视频或音频分析其中的情感 |
| 其他参考文献 | [1]梁爱华,王雪峤 多模态学习数据采集与融合、[2]陈燕、赖宇斌 基于CLIP和交叉注意力的多模态情感分析模型 、[3]武星、殷浩宇 面向视频数据的多模态情感分析 |
Gitee文件夹链接(所有代码均存在一个人的码云中):
https://gitee.com/w-jking/crawl_project/blob/master/大作业/datacrawl(1).zip
项目整体介绍:
项目名称:
国产手机风评调查
项目背景:
近年来,国货新潮流兴起,华为Mate60系列供应链90%以上来自国内,消费者的真实反馈对于手机品牌口碑和市场表现至关重要,收集和分析消费者对于国产手机的反馈,不仅可以为用户提供一个选择手机品牌的依据,也可以为品牌提供有价值的建议和改进方向。
项目目标:
通过采集和挖掘不同模态(文本、图片、音频)的数据,运用不同的情感分析模型,构造一个可以对国产手机各个方面进行多模态分析的系统,对国产手机品牌得到一个综合的情感分析,直观的感受到大众对于国产手机的的态度,以便于更好的判断国产手机中的“国货之光”。
项目具体流程图:
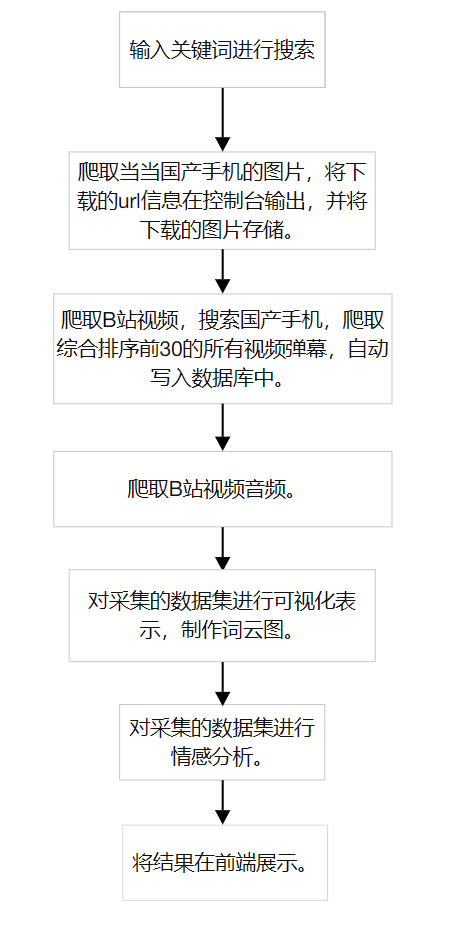
技术路线:
-
前端开发:
-
使用HTML、CSS和JavaScript进行前端的是界面设计,实现输入关键词和视频数量和弹幕数量后得到一个综合分析。
-
提升用户体验,使用动画效果和过渡效果,可以提高页面的交互性和吸引力。
-
-
后端开发:
-
使用python语言来实现后端开发的编写
-
使用Django框架来处理前端信息的接收,以及后端得到的信息返回
-
-
数据处理与分析:
-
文本爬取:
- 爬取B站弹幕和京东评论,但是京东评论在项目最后阶段爬取不到数据,所以只保留了弹幕的爬取。
- 采用request库的findall()函数获取指定cid的弹幕,并通过正则表达式提取出弹幕文本。
-
图片爬取:
- 爬取当当网的图片。
- 使用requests库的findall()函数和正则表达式取所有满足条件的图片链接。
- 并使用多线程机制将图片进行下载。
-
音/视频爬取:
- 爬取B站相关视频。
- 采用request库的findall()函数和正则表达式提取JSON中BV号。
- 使用正则表达式和json库获取视频和音频的url。
- 使用requests库来下载视频和音频文件。
-
文本分析: 首先考虑ERNIE-UIE文心模型,可是配置不成功,导致没有结果显示。接着考虑讯飞的情感分析模型,发现只能单句分析,不太符合需求,最后考虑百度云的API接口。
-
视频和音频分析:
- 对B站相关视频进行爬取,得到视频和音频。
- 使用Whisper方法将音频转为文本。
- 对上传的音频文件进行特征提取和情感识别。
-
图片分析:
- 使用预训练的BERT模型进行图像处理。
- 使用预训练的ResNet-50提取图片特征。
- 将图像特征输入到分类器中进行预测。
-
-
结果输出与展示:将分析结果通过前端界面展示。
输入框:
![输入框]()
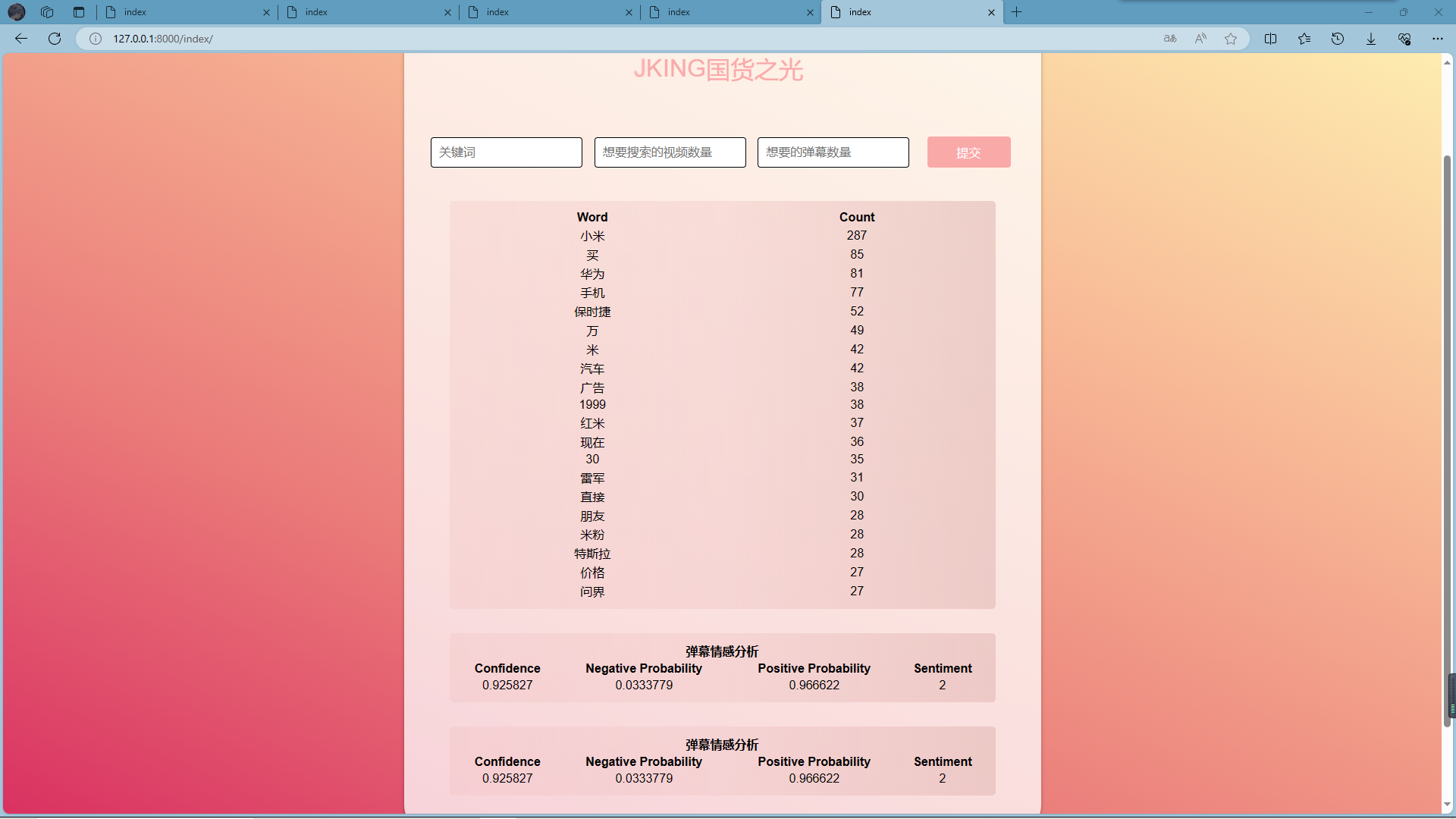
结果输出:
![输出结果]()
爬取关键词的情感分析:
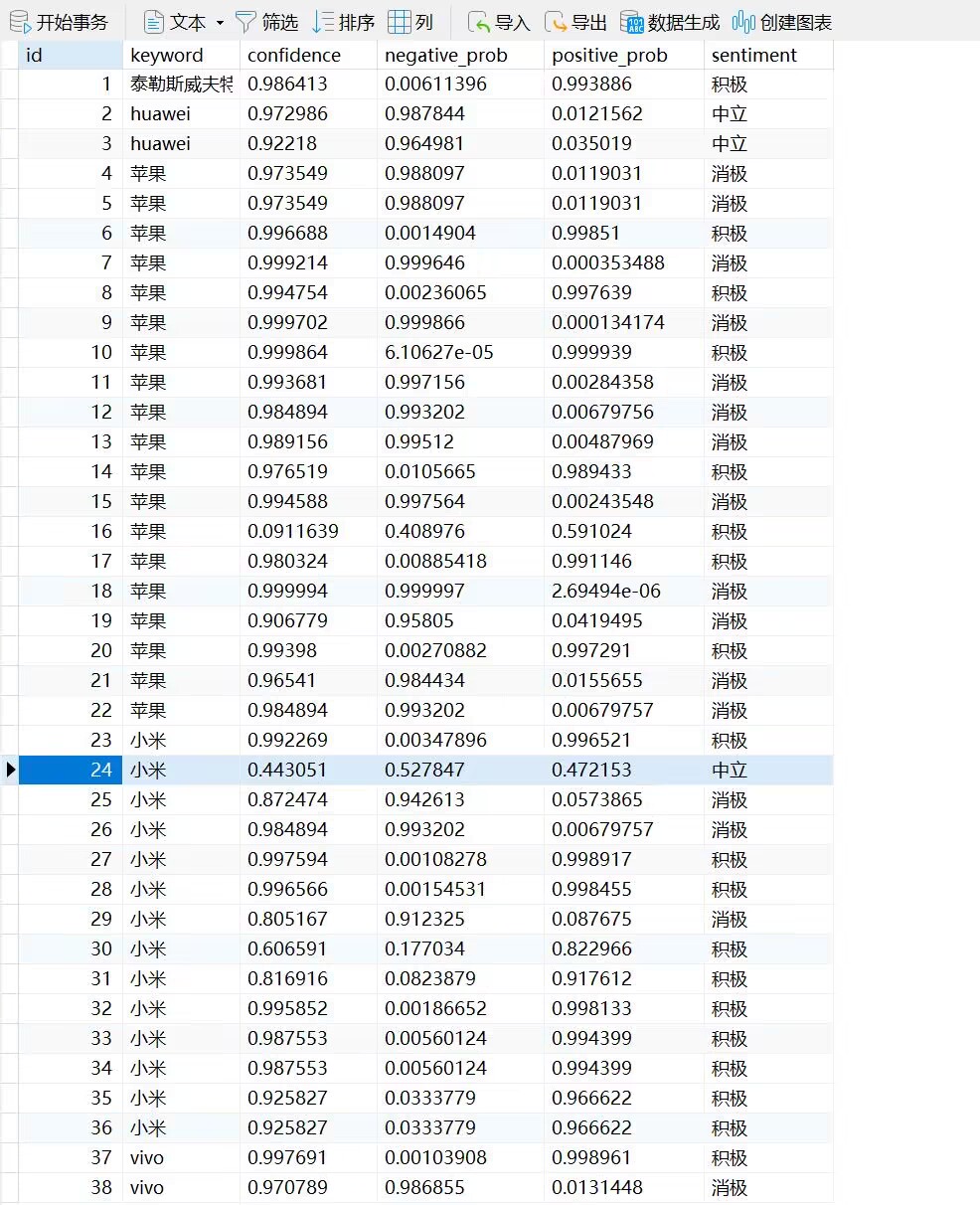
![数据库历史爬取记录]()
历史爬取数据:
![历史搜索记录]()
个人分工
在这次的实践中我主要负责的是项目的模型寻找,以及模型代码的训练和优化的编写。
文本情感分析
def textAnalysis(self):
url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=utf-8&access_token=" + self.get_access_token()
with open('/text.txt', 'r') as file:
text_from_file = file.read(250)
payload = json.dumps({
"text": text_from_file
})
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
return response.text
图片情感分析
def begin():
print("start predicting...")
# 读取test文件
test_path = "F:/datacrawl/imageAnalysis/my_test_without_label.txt"
test_df = pd.read_csv(test_path, sep=",")
test_df.iloc[:, -1] = 0
test_labels = np.array(test_df['tag'])
# tests数据处理并构建数据加载器
image_paths_test = get_valid_imagesPath_from_directory(folder_path, test_df)
dataset_test = Dataset(image_paths_test, test_labels, transform)
loader_test = DataLoader(dataset_test, batch_size=batch_size, shuffle=True)
# 读取保存的在验证集上表现最好的模型进行预测
best_model = torch.load('F:/datacrawl/imageAnalysis/img_model.pt').to(device)
test_predictions = predict_model(best_model, loader_test, device)
test_predictions = np.array(test_predictions)
# 生成预测文件
column_dict_ = {0: "positive", 1: "negative", 2: "neutral"}
test_df['tag'] = test_predictions
pre_df = test_df.replace({"tag": column_dict_})
pre_df.to_csv('F:/datacrawl/imageAnalysis/my_test_predict.txt', sep=',', index=False)
print("prediction finished")
def predict_model(model, test_loader, device):
model.eval()
predictions = []
for images, _ in test_loader:
images = images.to(device)
# texts = texts.to(device)
with torch.no_grad():
outputs = model(images)
_, preds = torch.max(outputs, 1)
predictions.extend(preds.cpu().numpy())
return predictions
音频转文字
def wav_to_text(self, path):
# path = "F:/datacrawl/audio/BV1bw411t7rd.wav"
model = whisper.load_model("base")
result = model.transcribe(path)
with open("/text.txt", "w") as f:
for l in result["segments"]:
print(l["text"])
try:
f.write(l["text"])
f.write("\n")
except:
continue
心得体会
102102112 王俊凯
在这次参与数据采集项目的过程中,我收获了很多宝贵的经验和教训。如项目的一个规划以及项目方向的确定,虽然起初我们还完全没有头绪,但是随着我们每个人的集思广益,慢慢的整个项目的逻辑也理清楚了。在这个项目中,我们选择了Python作为编程语言,并使用了requests库来发送HTTP请求获取数据。此外,我们还使用了wordcloud库构造词云来进行数据可视化。这些工具和技术都为我们提供了高效、灵活的数据采集和分析能力。
对于这次项目实践,自己觉得还有很多不足的地方,比如之前想要搞的有些情感分析的但是因为时间不够再加上自己代码的完整性不行所以不得不取消掉了,这也有点遗憾。不过在在这次的项目实践中,由于我们需要的数据都是我们要自己获取的,比如B站的弹幕信息,视频音信息,以及当当网上面的图片信息等等。通过这些,自己也是再一次对爬虫的工具以及方法的到了一个复习和提升。也加深了我对于机器学习的理解。
我们还从网上找到了很多可以利用的插件,学会合理利用资源,减少工作量提高工作效率,帮我们更精确的表达分析结果。当然更重要的是,通过这次课程设计,我们小组之间的分工合作非常重要,几个人之间相互配合,有效缩短了作业时间,大大提高了工作效率.
总之,这次数据采集项目让我收获了很多宝贵的经验和教训。通过参与项目,我不仅提高了自己的技能和能力,还加深了对数据采集、分析和可视化领域的理解。在未来的工作中,我将继续努力学习和提高自己,为项目的成功贡献更多的力量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号