

大数据学习day37-----flume03------1 flume复习梳理 2.吞吐量调优 3. 吞吐量调优实战 4Flume自定义扩展组件(自定义拦截器和source) 5综合案例
1 flume复习梳理
(1)flume是什么?
flume是一个分布式、高可用的数据采集系统
(2)flume主要适用于哪些场景
- 日志文件的采集
- kafka数据的采集
说明:本质上来说,flume可以读取任何数据源,然后传到任何一个数据存储。读不同的数据源有不同的source实现组件来适配,写入不同的数据存储,有不同的sink实现组件来适配。
(3)flume的核心组件

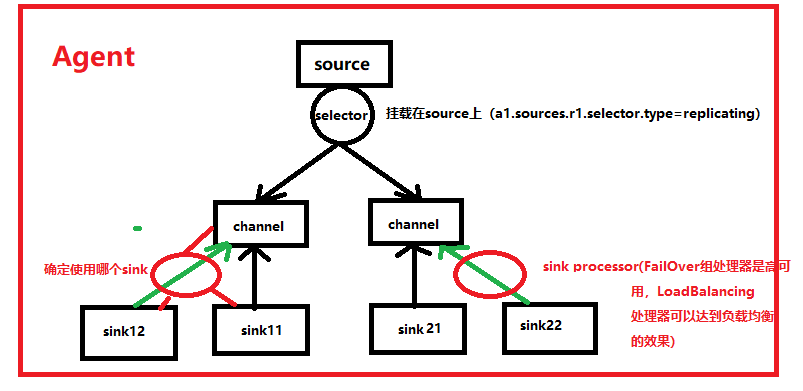
上诉组件都可由用户来自定义扩展(实现相应的接口即可)
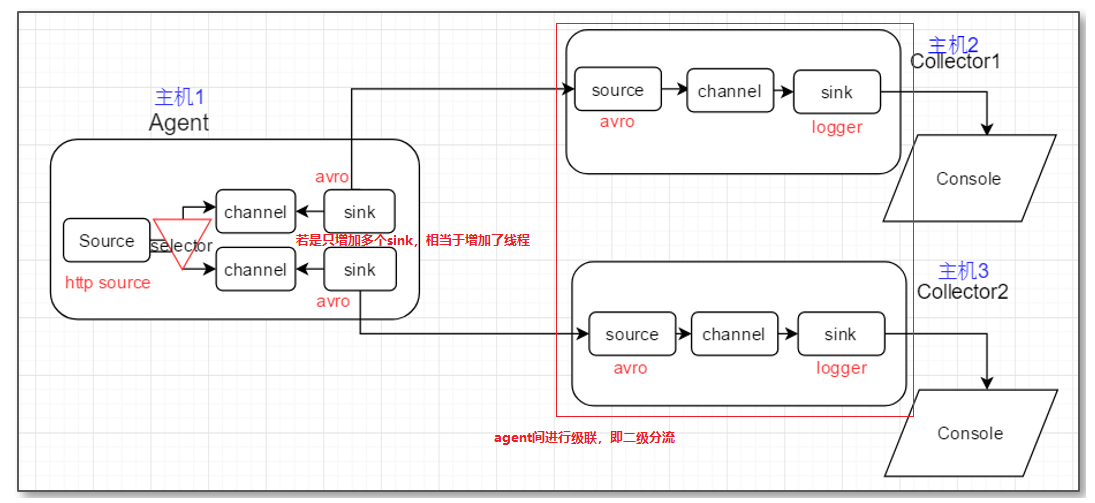
(4)agent可以组成数据传输的网络
提高并行度、分流、内外网环境的打通
(5)核心概念
- Event:source收到数据后所生成的封装格式(headers,body)
- 事务:source获取数据,写入channel。这个过程是一个事务;sink从channel拿数据写到指定存储系统,也是一个事务
- 批次:source写Event到channel是按批次进行的;sink从channel拿数据写出去,也是按批次进行的;事务管理也是按批次进行的
- 吞吐量:吞吐量是指对网络、设备、端口、虚电路或其他设施,单位时间内成功地传送数据的数量(以比特、字节、分组等测量)。
agent的吞吐量由哪些因素决定?
- source 读取数据源的速度; tail -F access.log
- channel 接收数据的速度不太可能成为瓶颈(写内存,还是写本地磁盘都很快),channel提高容量主要可以提高削峰的能力
- sink 写出数据的速度;
所以说,agent的吞吐量由source和sink决定
2.吞吐量调优
吞吐量产生瓶颈的话,数据的采集就会产生时延,如何优化来提高吞吐量呢?======>找瓶颈的原因,哪里有瓶颈就解决哪里
- source读数据慢:
(1)替换慢的source为更快的source,比如 exec 可以换成 taildir
(2)增加并行度:比如数据源同时在多个文件上追加日志,那么,我们可以用多个source分别对应不同的文件组
- sink写数据慢(比如hdfs sink写数据比较慢):
(1)增加并行度,多个sink对接一个channel,就相当于多个hdfs客户端同时写数据(只增加sink就相当于增加线程;若是后面再级联agent,即二级分流,相当于又重新开启进程,这样效率更高)
(2)如果资源有限,只能换更快的sink种类;比如,把hdfssink换成 kafka sink
3. 吞吐量调优实战
(1)案例:本案例通过模拟数据产生的速度和flume从该数据源采集数据的速度是否一致,从而判断出flume吞吐量的优劣,以便进行相关的调优工作。具体模拟步骤如下
使用exec source获取a.log中的数据,a.log中的数据产生特别快,用来模拟大量的数据,其脚本(hdfs_sink.sh)如下
i=1 while true do echo "$((i++)) $RANDOM --.........ABC......" >>a.log done
此处通过比较a.log数据产生的条数和source成功写入channel的条数(写入channel的速度与sinkcong),从而判断吞吐量的好坏
配置文件如下(hdfs-sink.conf):


a1.sources = s1 a1.channels = c1 a1.sinks = k1 a1.sources.s1.channels = c1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /root/logs/a.log a1.sources.s1.batchSize = 100 a1.sources.s1.interceptors = i1 a1.sources.s1.interceptors.i1.type = timestamp a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path =hdfs://feng05:9000/hdfs-sink/%Y-%m-%d/%H-%M/ a1.sinks.k1.hdfs.filePrefix = feng- a1.sinks.k1.hdfs.fileSuffix = .log.gzip a1.sinks.k1.hdfs.inUseSuffix = .tmp a1.sinks.k1.hdfs.rollInterval = 0 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.codeC = gzip a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.writeFormat = Text a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.channel = c1
- 启动flume(由于要调优,所以一定要监控),命令如下:
bin/flume-ng agent -n a1 -c myconf/conf/ -Dflume.monitoring.type=http -f myconf/hdfs-sink.conf -Dflume.monitoring.port=34345 -Dflume.root.logger=INFO,console
- 启动hdfs_sink.sh脚本
sh hdfs_sink.sh
- 通过feng05:34345打开web监控网站,在tail a.log 的同时,立即刷新监控的web网站,比较a.log数据产生的条数和source成功写入channel的条数
- 结果如下:
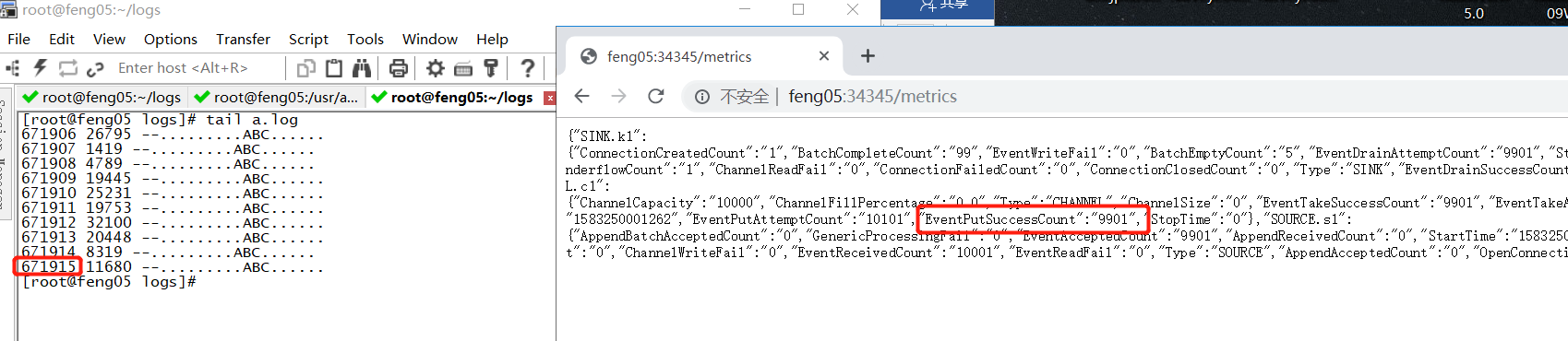
可见成功放入channel中的数据远远小于数据源产生的数据
(2) 调优(以下都属于sink写数据慢的调优)
- 第一种:增加hdfs sink的并行度(即增加线程的形式),此处需要配置sink processor(LoadBalancing),这样能保证多个sink从channel中取到数据不一样,sink从channel中取数据的速度也是很快的,瓶颈只是sink往hdfs中写数据慢。
增加hdfs sink数的配置文件设置如下(此处增加成3个sink)
a1.sources = s1 a1.channels = c1 a1.sinks = k1 k2 k3 a1.sources.s1.channels = c1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /root/logs/a.log a1.sources.s1.batchSize = 100 a1.sources.s1.interceptors = i1 a1.sources.s1.interceptors.i1.type = timestamp a1.channels.c1.type = memory a1.channels.c1.capacity = 10000 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path =hdfs://feng05:9000/hdfs-sink/%Y-%m-%d/%H-%M/ a1.sinks.k1.hdfs.filePrefix = feng01- a1.sinks.k1.hdfs.fileSuffix = .log.gzip a1.sinks.k1.hdfs.inUseSuffix = .tmp a1.sinks.k1.hdfs.rollInterval = 0 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.codeC = gzip a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.writeFormat = Text a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.channel = c1 a1.sinks.k2.type = hdfs a1.sinks.k2.hdfs.path =hdfs://feng05:9000/hdfs-sink/%Y-%m-%d/%H-%M/ a1.sinks.k2.hdfs.filePrefix = feng02- a1.sinks.k2.hdfs.fileSuffix = .log.gzip a1.sinks.k2.hdfs.inUseSuffix = .tmp a1.sinks.k2.hdfs.rollInterval = 0 a1.sinks.k2.hdfs.rollSize = 134217728 a1.sinks.k2.hdfs.rollCount = 0 a1.sinks.k2.hdfs.codeC = gzip a1.sinks.k2.hdfs.fileType = CompressedStream a1.sinks.k2.hdfs.writeFormat = Text a1.sinks.k2.hdfs.round = true a1.sinks.k2.hdfs.roundValue = 10 a1.sinks.k2.hdfs.roundUnit = minute a1.sinks.k2.channel = c1 a1.sinks.k3.type = hdfs a1.sinks.k3.hdfs.path =hdfs://feng05:9000/hdfs-sink/%Y-%m-%d/%H-%M/ a1.sinks.k3.hdfs.filePrefix = feng03- a1.sinks.k3.hdfs.fileSuffix = .log.gzip a1.sinks.k3.hdfs.inUseSuffix = .tmp a1.sinks.k3.hdfs.rollInterval = 0 a1.sinks.k3.hdfs.rollSize = 134217728 a1.sinks.k3.hdfs.rollCount = 0 a1.sinks.k3.hdfs.codeC = gzip a1.sinks.k3.hdfs.fileType = CompressedStream a1.sinks.k3.hdfs.writeFormat = Text a1.sinks.k3.hdfs.round = true a1.sinks.k3.hdfs.roundValue = 10 a1.sinks.k3.hdfs.roundUnit = minute a1.sinks.k3.channel = c1
按照上诉步骤运行后的结果如下
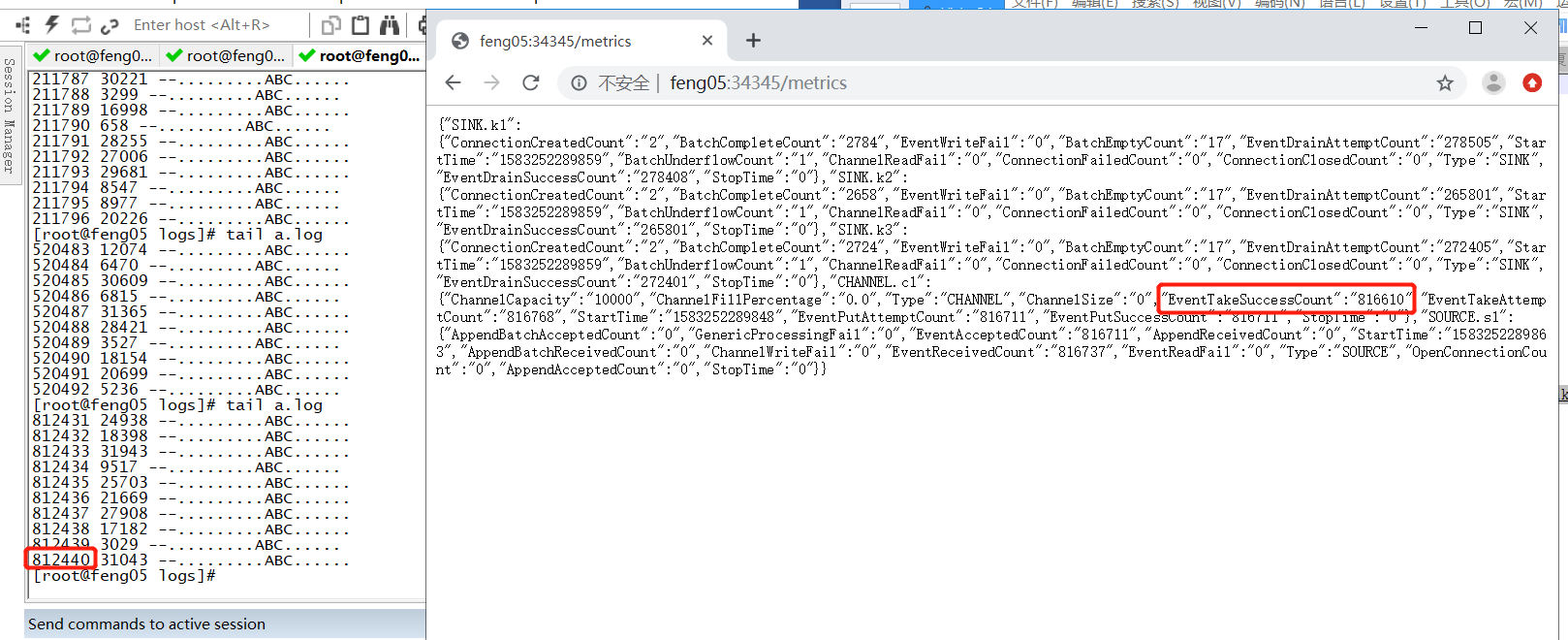
可见,调优起到明显的作用,此处数据产生的速度与flume从中采集的速度几乎一致
- 第二种:若第一种情况的增加线程的形式,数据采集的效果还不够好,可以使用2级分流,即增加agent(见1中的(4))
- 第三种:如果资源有限,只能换更快的sink种类;比如,把hdfssink换成 kafka sink
- 第四种:将提交批次的两增大点,比如将默认的100换成1000,这样性能也会有所提高(100条提交一次,这样提交的频率就大,会对性能有一点点影响)
4 Flume自定义扩展组件
4.1 自定义拦截器
4.1.1 需求场景
公司的点击流日志数据在日志服务器上不断生成: /var/log/click_streaming.log。日志文件会随着文件的大小达到一定阈值(128M)而被roll(滚动、重命名),比如:click_streaming.log.1,并且会生成一个新的click_streaming.log文件继续写入日志流;
日志文件中数据格式如下:
13888776677,click,/baoming,张飞,湖北省 13889976655,click,/xuexi,关羽,山西省
现在需要用flume去日志服务器上采集数据写入HDFS,并且要求,对数据中的手机号、姓名字段进行加密(MD5加密,并将加密结果变成BASE64编码);
4.1.2 实现思路
- source组件可以选择taildir
(1)可以监控到新文件
(2)可以记录采集的偏移量
- channel 为了保证可靠性,可以选择filechannel
(1)会在磁盘上缓存event
(2)会在磁盘上记录事务状态
- sink 目标存储是HDFS,sink自然是选择hdfs sink
- 加密需求的解决
如果从source上解决,那只能修改 taildir组件的源码;如果从sink上解决,那只能修改hdfs sink组件的源码;上述两种,都需要修改源码,不是最佳选择! 最佳选择:通过拦截器来实现对数据的加工!而flume中没有现成的内置拦截器可以实现字段加密,我们可以自定义自己的拦截器;
4.2 自定义拦截器的开发
4.2.1 基本套路
框架中,自定义扩展接口的套路:
(1) 要实现或者继承框架中提供的接口或父类,实现、重写其中的方法
(2)写好的代码要打成jar包,并放入flume的lib目录
(3)要将自定义的类,写入相关agent配置文件
4.2.2 拦截器设计
应对本场景使用自定义拦截器,还要考虑几个参数的问题,即用户要加密的字段,可能会变化,因此要能人为的控制加密的字段。这该怎么解决呢?
(1)可以在配置文件中设计一个参数,来指定要加密的字段:
indices (要加密的字段索引) 以及索引的切割符idxSplitBy // 此处自己为了省事就直接指定索引分割符为逗号了 --》 比如: a1.sources.interceptors.i1.indices = 0:3 a1.sources.interceptors.i1.idxSplitBy = :
(2)为了能够正确切分数据中的字段,还需要一个参数:字段的分隔符dataSplitBy
--》 比如: a1.sources.interceptors.i1.dataSplitBy= ,
4.2.3 代码:
思路:
(1)需要拿到配置文件中的参数,即知道了要加密的字段
(2)将获取到的参数传给拦截器(通过构造方法的形式将数据传给拦截器)
(3)拦截器的具体工作逻辑(即对一个event数据进行处理)
(4)通过for循环反复调用(3)涉及的方法
代码如下
EncryptInterceptor
package com.yiee.flume; import org.apache.commons.codec.binary.Base64; import org.apache.commons.codec.digest.DigestUtils; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.util.List; public class EncryptInterceptor implements Interceptor { // 配置文件中指定的待加密字段的index : 0,3 private String toEncryptFields; private String fieldsSeparator; // 定义带参数构造方法 private EncryptInterceptor(String toEncryptFields, String fieldsSeparator){ this.toEncryptFields = toEncryptFields; this.fieldsSeparator = fieldsSeparator; } public void initialize() { } /** * 拦截器的具体工作逻辑 * 对一个event进行处理 * event中的数据 * 13888776677,click,/baoming,张飞,湖北省 * 13889976655,click,/xuexi,关羽,山西省 * @param event * @return */ public Event intercept(Event event) { // 取出event中的数据 byte[] bodyBytes = event.getBody(); String bodyString = new String(bodyBytes); // 切分数据字段 String[] fields = bodyString.split(fieldsSeparator); // 切分加密索引 String[] indices = toEncryptFields.split(","); for (String idx:indices) { // 取出待加密的数据 String data = fields[Integer.parseInt(idx)]; // 对数据进行加密 String md5Data = DigestUtils.md5Hex(data); String base64Data = Base64.encodeBase64String(md5Data.getBytes()); // 替换掉原来的字段值 fields[Integer.parseInt(idx)] = base64Data; } // 将数据重新拼接成字符串 StringBuilder sb = new StringBuilder(); for (String field:fields) { sb.append(field).append(fieldsSeparator); } // 删除最后一个分割符 String res = sb.deleteCharAt(sb.length() - 1).toString(); event.setBody(res.getBytes()); return event; } public List<Event> intercept(List<Event> events) { for (Event event : events) { intercept(event); } return events; } public void close() { } public static class MyBuilder implements Interceptor.Builder{ private String toEncryptFields; private String fieldsSeparator; // 构造一个拦截器对象 public Interceptor build() { return new EncryptInterceptor(toEncryptFields,fieldsSeparator); } // 配置拦截器相关参数,context参数中就包含有agent配置中的拦截器相关参数 public void configure(Context context) { toEncryptFields = context.getString(ParamConstants.TO_ENCRYPT_FIELDS); fieldsSeparator = context.getString(ParamConstants.FIELDS_SEPARATOR); } } /** * 参数类(代码规范) */ public static class ParamConstants{ public static final String TO_ENCRYPT_FIELDS = "toEncryptFields"; public static final String FIELDS_SEPARATOR = "fieldsSeparator"; } }
4.2.4 测试
(1)将上诉代码打成jar包,放入flume的lib文件夹中
(2)写好配置文件,启动flume进行数据采集,即可得到加密后的数据
配置文件如下:
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/b.log a1.sources.r1.batchSize = 2 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.yiee.flume.EncryptInterceptor$MyBuilder a1.sources.r1.interceptors.i1.toEncryptFields =0,3 a1.sources.r1.interceptors.i1.fieldsSeparator=, a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.channels.c1.type = memory
(3)测试结果(若想看到加密结果,可以将数据存储到hdfs)
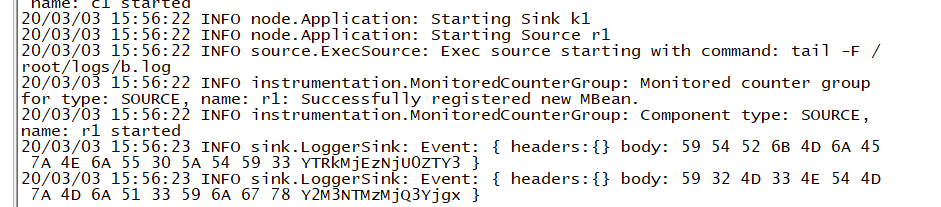
4.3 自定义source
4.3.1 需求场景
什么情况下需要自定义source?一般是某种数据源,用flume内置的source组件无法解析,比如XML文档。本案例需要实现文本日志的采集,并能记住偏移量
4.3.2 实现思路
首先,找到自定义source所要实现或集成的父类/接口---->重写方法(插入中间的需求逻辑)----->将代码打成jar包,传入flume的lib目录------->agent文件配置自定义的source
4.3.3 代码
HoldOffsetTailSource
package com.yiee.flume; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.EventDrivenSource; import org.apache.flume.channel.ChannelProcessor; import org.apache.flume.conf.Configurable; import org.apache.flume.event.EventBuilder; import org.apache.flume.source.AbstractSource; import java.io.*; import java.util.ArrayList; /** * 功能: 读取一个不断追加数据的日志文件 * 并且,能记录读取位置的偏移量,以便宕机重启后,还能根据所记录的偏移量断点续采 */ public class HoldOffsetTailSource extends AbstractSource implements EventDrivenSource, Configurable { private String path; private int batchSize; private long batchInterval; private String positionFilePath; private RandomAccessFile reader; /** * agent会调用此方法,来开启source的采集工作 */ @Override public synchronized void start() { ChannelProcessor channelProcessor = getChannelProcessor(); // 1.读取文件 // 1.1 先读偏移量 try { File posFile = new File(positionFilePath); long offset = 0L; if(posFile.exists()){ BufferedReader br = new BufferedReader(new FileReader(posFile)); String line = br.readLine(); } // 1.2 从指定偏移量处读取文件 reader = new RandomAccessFile(path, "r"); reader.seek(offset); String line = null; ArrayList<Event> eventList = new ArrayList<Event>(); long preBatchTime = System.currentTimeMillis(); while(true){ line = reader.readLine(); // 如果待采日志文件中还没有新数据,则休眠1s if(line == null){ Thread.sleep(1000); }else{ // 每一行封装成一个Event Event event = EventBuilder.withBody(line.getBytes()); // 把event放入一个eventList中攒起来 eventList.add(event); if ((System.currentTimeMillis() - preBatchTime) >= batchInterval * 1000 || eventList.size() >= batchSize) { // 提交 channelProcessor.processEventBatch(eventList); // 清空list eventList.clear(); // 更新批次提交时间 preBatchTime = System.currentTimeMillis(); // 获取当前的偏移量,并持久化到偏移量记录文件中 long newOffset = reader.getFilePointer(); // 记录偏移量到文件中 FileOutputStream out = new FileOutputStream(positionFilePath); out.write((newOffset + "").getBytes()); out.close(); } } } } catch (Exception e) { e.printStackTrace(); } } @Override public synchronized void stop() { super.stop(); super.stop(); try { if(reader != null) { reader.close(); } }catch (Exception ignored){ } } // 获取配置参数的方法 public void configure(Context context) { this.path = context.getString("path"); this.batchSize = context.getInteger("batchSize"); this.positionFilePath = context.getString("positionFile"); this.batchInterval = context.getLong("batchInterval"); } }
5 综合案例
5.1 案例场景
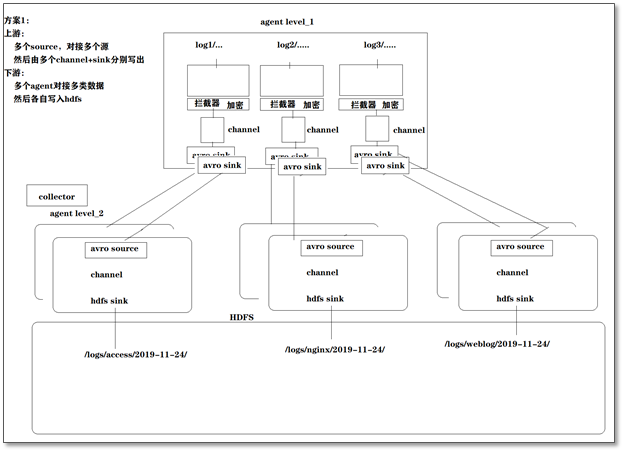
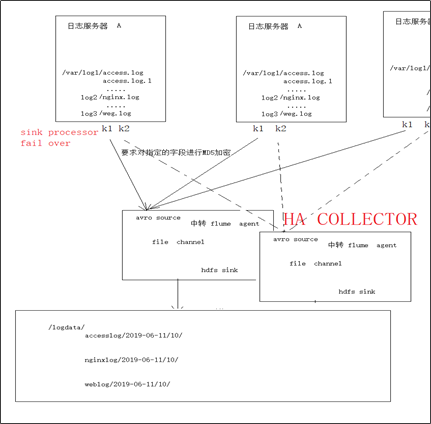
A、B等日志服务机器实时生产日志,日志分为多种类型:log1/access.log,log2/nginx.log,log3/web.log
现在要求:
把日志服务器中的各类日志采集汇总到一个中转agent上,然后分类写入hdfs中。但是在hdfs中要求的目录为:

方案一:
方案二

 浙公网安备 33010602011771号
浙公网安备 33010602011771号