A:数据删除均为逻辑删除,不会物理删除。而且在每次完整的数据迁移过程中,必定概率性出现死锁,因此排除该原因。(百万量级数据,分页参数500,每次迁移出现死锁概率/次数不等)
2、温故知新
2.1锁类型及锁模式
| |
锁类型(lock_type,锁的粒度)
|
|---|
|
锁模式
(lock_mode)
|
|
表锁
|
行锁
|
|---|
|
读锁
|
LOCK_IS
|
LOCK_S
|
|
写锁
|
LOCK_IX
|
LOCK_X
|
|
自增锁
|
LOCK_AUTO_INC
|
|
2.2行锁及其兼容矩阵
|
显式锁
|
隐式锁
|
|---|
|
Record Locks
|
Gap Locks
|
Next-Key Locks
|
Insert Intention Locks
|
| |
Record Locks
|
Gap Locks
|
Next-Key Locks
|
Insert Intention Locks
|
|---|
|
Record Locks
|
|
√
|
|
√
|
|
Gap Locks
|
√
|
√
|
√
|
√
|
|
Next-Key Locks
|
|
√
|
|
√
|
|
Insert Intention Locks
|
√
|
|
|
√
|
(第一行表示已有的锁,第一列表示要加的锁)
2.3隐式锁转换
- InnoDB 在插入记录时,是不加锁的。如果事务 A 插入记录且未提交,这时事务 B 尝试对这条记录加锁,事务 B 会先去判断记录上保存的事务 id 是否活跃,如果活跃的话,那么就帮助事务 A 去建立一个锁对象,然后自身进入等待事务 A 状态,这就是所谓的隐式锁转换为显式锁。
- 前边说 INSERT 语句一般情况下不加锁,不过如果即将插入的间隙已经被其他事务加了 Gap Locks ,那么本次 INSERT 操作会阻塞,并且当前事务会在该间隙上加一个Insert Intention Locks,进入锁等待 。除此之外,在下边两种特殊情况下也会进行加锁操作:
- 当子表中的外键值可以在父表中找到时,那么无论当前事务是什么隔离级别,只需要给父表中 对应的记录添加一个 S型正经记录锁 就好了。
- 当子表中的外键值在父表中找不到时:那么如果当前隔离级别不大于RC时,不对父表记录加 锁;当隔离级别不小于RR时,对父表中该外键值所在位置的下一条记录添加gap锁。
2.4唯一约束冲突加锁
- 当隔离级别不大于RC时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加S型Record Locks。
- 当隔离级别不小于RR时,插入新记录的事务会给已存在的主键值重复的聚簇索引记录添加S型Next-Key Locks。
不论是哪个隔离级别,插入新记录的事务都会给已存在的二级索引列值重复的二级索引记录添加S型next-key锁,再强调一遍,加的是Next-Key Locks!加的是Next-Key Locks!加的是Next-Key Locks!这是RC隔离级别中为数不多的给记录添加gap锁的场景。
2.5加锁原则及案例分析
- 加锁基本单位是Next-Key Locks;
- 查找过程中访问到的对象才会加锁;
- 索引上的等值查询,给唯一索引加锁的时候,Next-Key Locks退化为记录锁;
- 索引上的等值查询,向右遍历到最后一个不满足等值条件时候,退化为间隙锁;
- 唯一索引上的查询范围会访问到不满足第一个值为止。
CREATE TABLE `Test` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
insert into Test values(0,0,0),(5,5,5),(10,10,10),(15,15,15);
-
案例一:主键索引等值间隙锁
-
delete from Test where id=8;
表中没有id=8这条记录,根据原则1,事务A加锁范围是(5,10],根据原则4是id=8是等值查询,遍历到id=10不满足查询提交,临建锁退化为间隙锁,所以最终加锁范围是(5,10)
-
案例二:主键索引范围锁
-
delete from Test where id>=10 and id<11;
根据原则1找到第一个id=10的行,next-key lock(5,10],根据原则3,主键id等值条件退化为了记录锁,只加了10这一行记录锁;
范围查找继续往后找,找到id=15这一行,加临建锁(10,15]
-
案例三:非唯一索引范围锁
-
delete from Test where a>=10 and a<11;
根据原则1找到第一个a=10的行,next-key lock(5,10],(10,15]
-
案例四:唯一索引范围锁
-
delete from Test where id>5 and id<=11;
根据原则1和原则5,索引id的(5,10],(10,15]都会加锁
-
案例五:非唯一索引等值锁
-
delete from Test where a=10;
根据原则1和原则4,索引a的(5,10],(10,15)都会加锁
3、死锁案例分析
3.1场景分析
-
先删除一条数据,则在该行数据上加Delete Mark,表示该行数据已经被删除,但并没有物理删除。
-
插入一条具有相同唯一约束的数据,触发Duplicate Key检查。
-
在打了Delete Mark的行数据上加Next-Key Locks。
3.2解决方案
导致问题的根本原因是Gap Locks和Insert Intention Locks冲突,解决该问题有以下几个途径:
-
每次只操作单条数据。
结论:可能导致锁等待,但是不会引发死锁。功能实现上可行,但是效率低,不推荐。
-
将删除和插入动作拆分为两个步骤,独立进行。
结论:删除和插入动作不是同一个事务,可能导致数据遗漏或产生脏数据,不推荐。
-
取数逻辑按照唯一索引UK_BIZCODE_VERSION有序获取,保证不同线程对数据有序加锁。
结论:可能引发锁等待,但不会引发死锁。但是,由于取数过程中,可能有新数据插入,而新插入数据在唯一约束中的位置是随机的,可能导致不同线程获取到重复数据,不可行。
-
将唯一约束去掉,UK_BIZCODE_VERSION改为非唯一索引。
结论:数据迁移过程中不会引发死锁,待完成迁移后将UK_BIZCODE_VERSION改为唯一索引,采用该方式。
4、死锁案例扩展
案例一
https://github.com/aneasystone/mysql-deadlocks
案例二
![]()
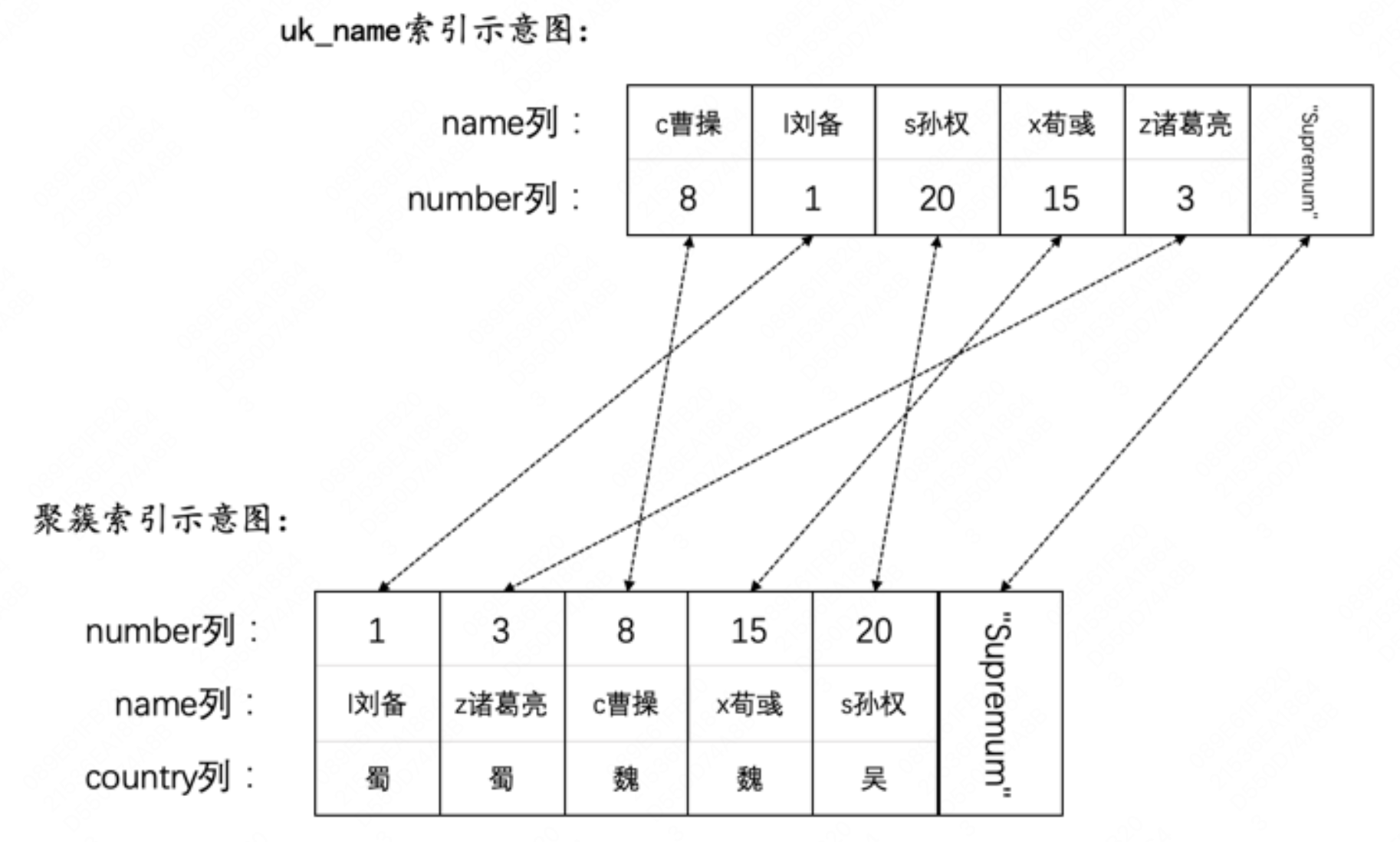
- T1先插入name值为 g关羽 的记录,可以插入成功,此时对应的唯一二级索引记录被隐式锁保护,没有行锁。
![]()
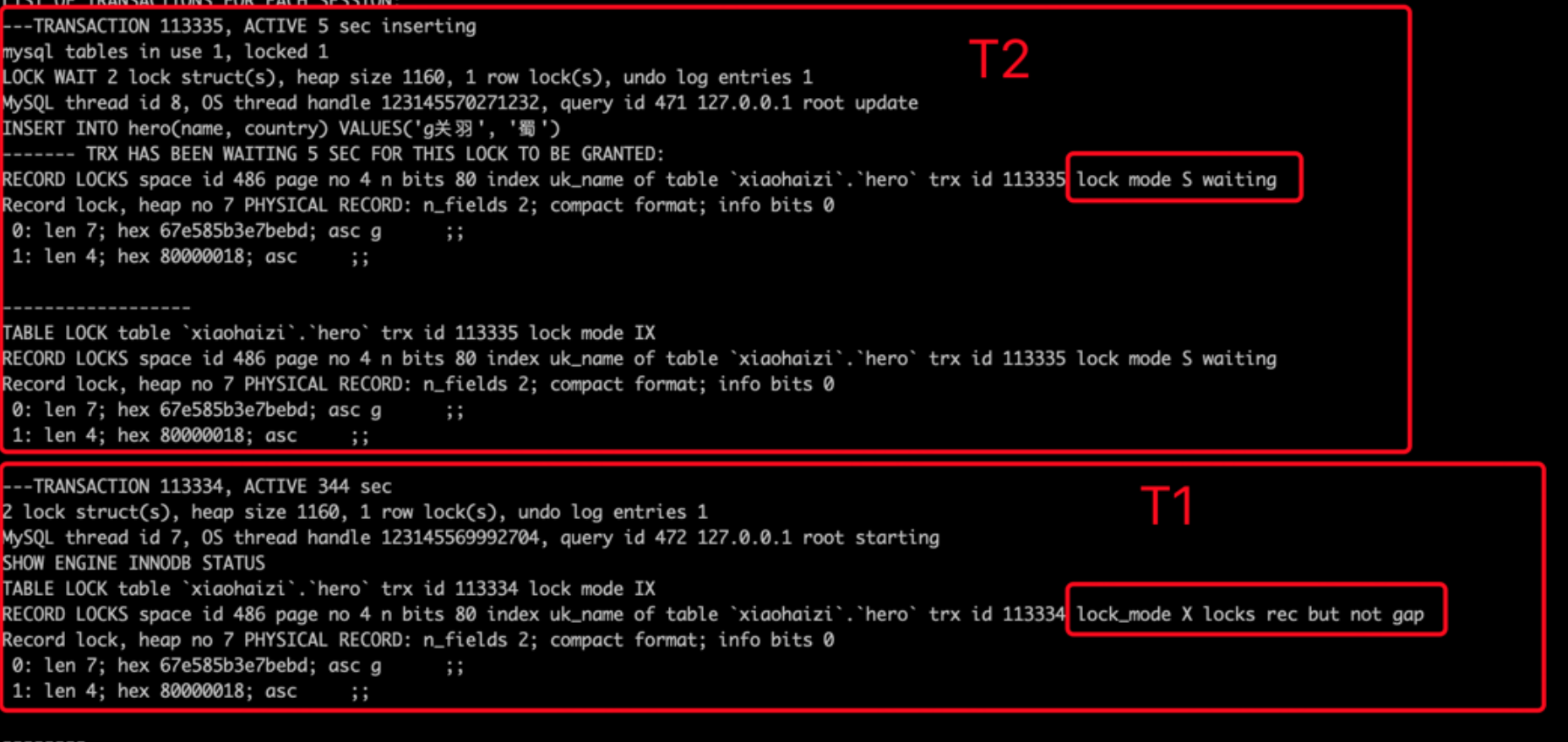
- 接着T2也插入name值为 g关羽 的记录。由于T1已经插入name值为 g关羽 的记录,所以T2在插入二级索引记录时会遇到重复的唯一二级索引列值,此时T2想获取一个S型Next-Key Locks,但是T1并未提交,T1插入的name值为 g关羽 的记录上的隐式锁相当于一个X型Record Locks,所以T2向获取S型Next-Key Locks时会遇到锁冲突,T2进入阻塞状态,并且将T1的隐式锁转换为显式锁(就是帮助T1实现隐式锁转换)。
![]()
- 接着T1再插入一条name值为 d邓艾 的记录,被T2的Next-Key Locks阻塞。(…………………………………………………………)
![]()
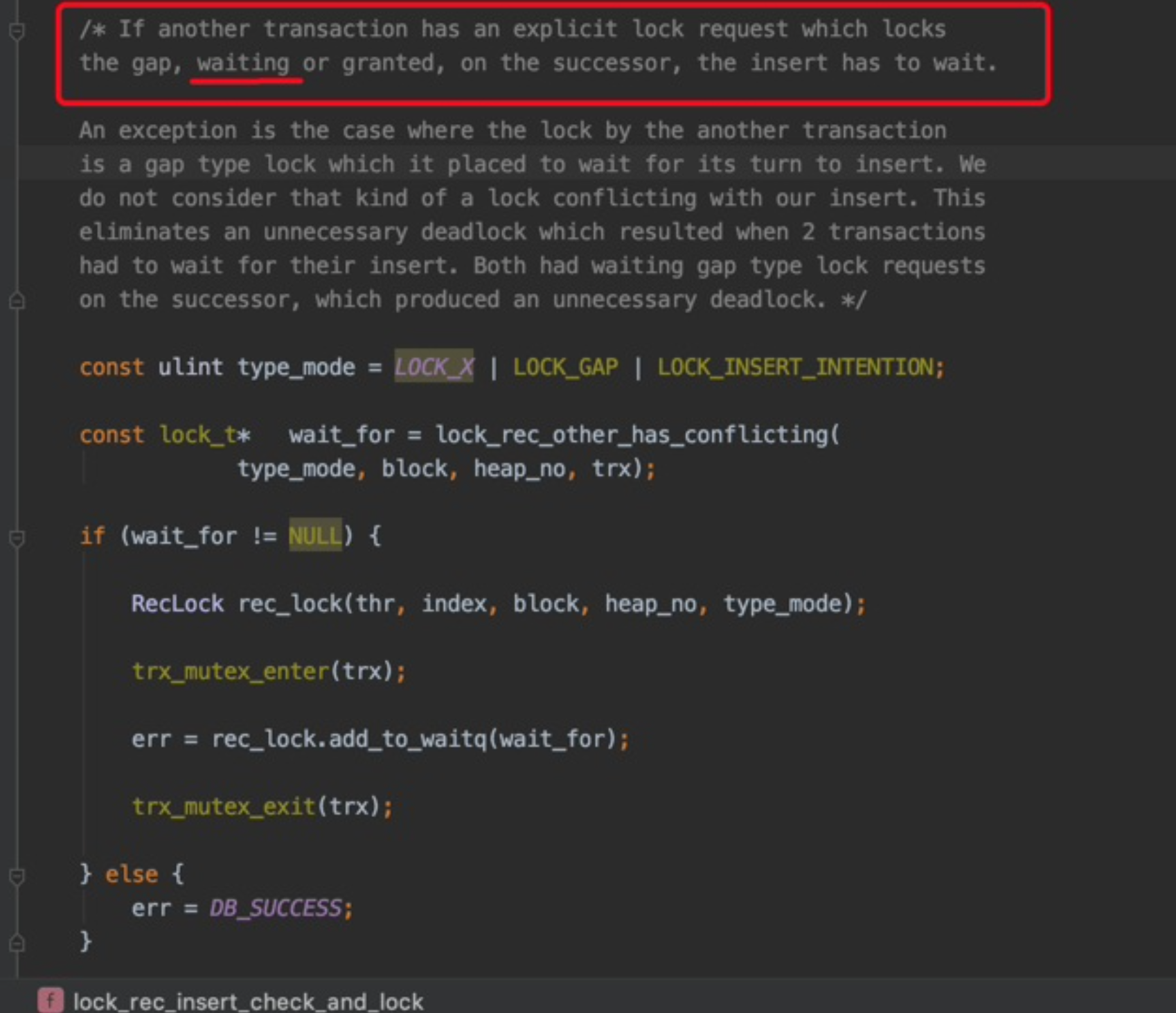
Tips:只要别的事务生成了一个显式的gap锁的锁结构,不论那个事务已经获取到了该锁(granted),还是正在等待获取(waiting),当前事务的INSERT操作都应该被阻塞。
Q:如何解决这个场景下的问题呢?
A:方式一:一个事务只插入一条数据。方式二:改变插入顺序,使得唯一索引从小到大升序插入。
案例三
更新聚簇索引和二级索引时触发锁循环等待。(参考淘宝数据库内核月报:http://mysql.taobao.org/monthly/)
|
索引名称
|
索引字段
|
是否唯一索引
|
|---|
|
PRIMARY
|
ID
|
是
|
|
IDX_A
|
A
|
否
|
|
TX1
|
TX2
|
|---|
|
update test set a='a' where id = 1;
|
update test set b='b' where a='a';
|
-
上述案例中TX1走的索引是PRIMARY,而且涉及到二级索引字段的更新,因此先对聚簇索引加锁,再对二级索引加锁(如果二级索引字段没有被更新则没有该步骤)。
-
TX2走的索引是IDX_A,且涉及到其他字段的更新需要更新聚簇索引,因此先对二级索引加锁,再对聚簇索引加锁。
上述案例中,死锁概率性发生,非稳定复现。
5、如何避免死锁
-
以固定的顺序访问表和行。在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能;
-
Gap 锁往往是程序中导致死锁的真凶,由于默认情况下 MySQL 的隔离级别是 RR,所以如果能确定幻读和不可重复读对应用的影响不大,可以考虑将隔离级别改成 RC,基本可以避免 Gap 锁导致的死锁;
-
为表添加合理的索引,如果不走索引将会为表的每一行记录加锁,死锁的概率就会大大增大;
-
避免大事务,尽量将大事务拆成多个小事务来处理;因为大事务占用资源多,耗时长,与其他事务冲突的概率也会变高;
-
我们知道 MyISAM 只支持表锁,它采用一次封锁技术来保证事务之间不会发生死锁,所以,我们也可以使用同样的思想,在事务中一次锁定所需要的所有资源,减少死锁概率;
-
避免在同一时间点运行多个对同一表进行读写的脚本,特别注意加锁且操作数据量比较大的语句;我们经常会有一些定时脚本,避免它们在同一时间点运行;
-
设置锁等待超时参数:innodb_lock_wait_timeout,这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号